

路子对了,就不怕遥远。 ——人民日报

前言
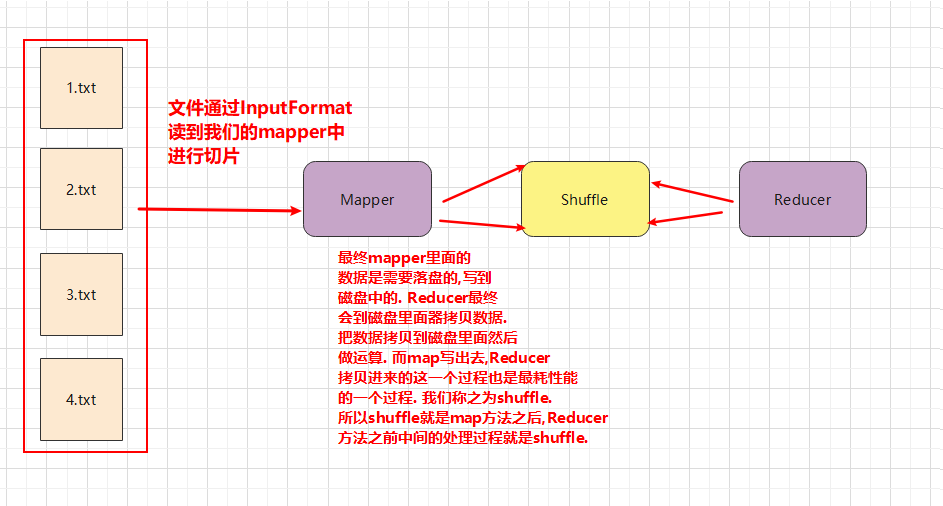
mapreduce过程概括为: InputFormat—-> mapper,shuffle,reducer—>OutputFormat
此篇文章记录shuffle原理.
Shuffle机制
什么是shuffle?
shuffle就是数据落盘的过程.
hadoop在mapreduce计算过程中,什么阶段会有落盘呢? 在map打散数据之后,reduce聚合数据之前.
Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle
以后我们在做一些操作的时候, 能没有reducer的话, 就不写Reducer.
因为整个MapReduce任务中, shuffle是最耗费时间的. 因为你Reducer没有shuffle也就没有了. 那么这个程序性能就比较高.
其实我们的MapReduce整个阶段我们细细的分可以分为5个阶段.
Map——> sort(排序) ——-> copy ——>sort(排序) ——-> Reducer
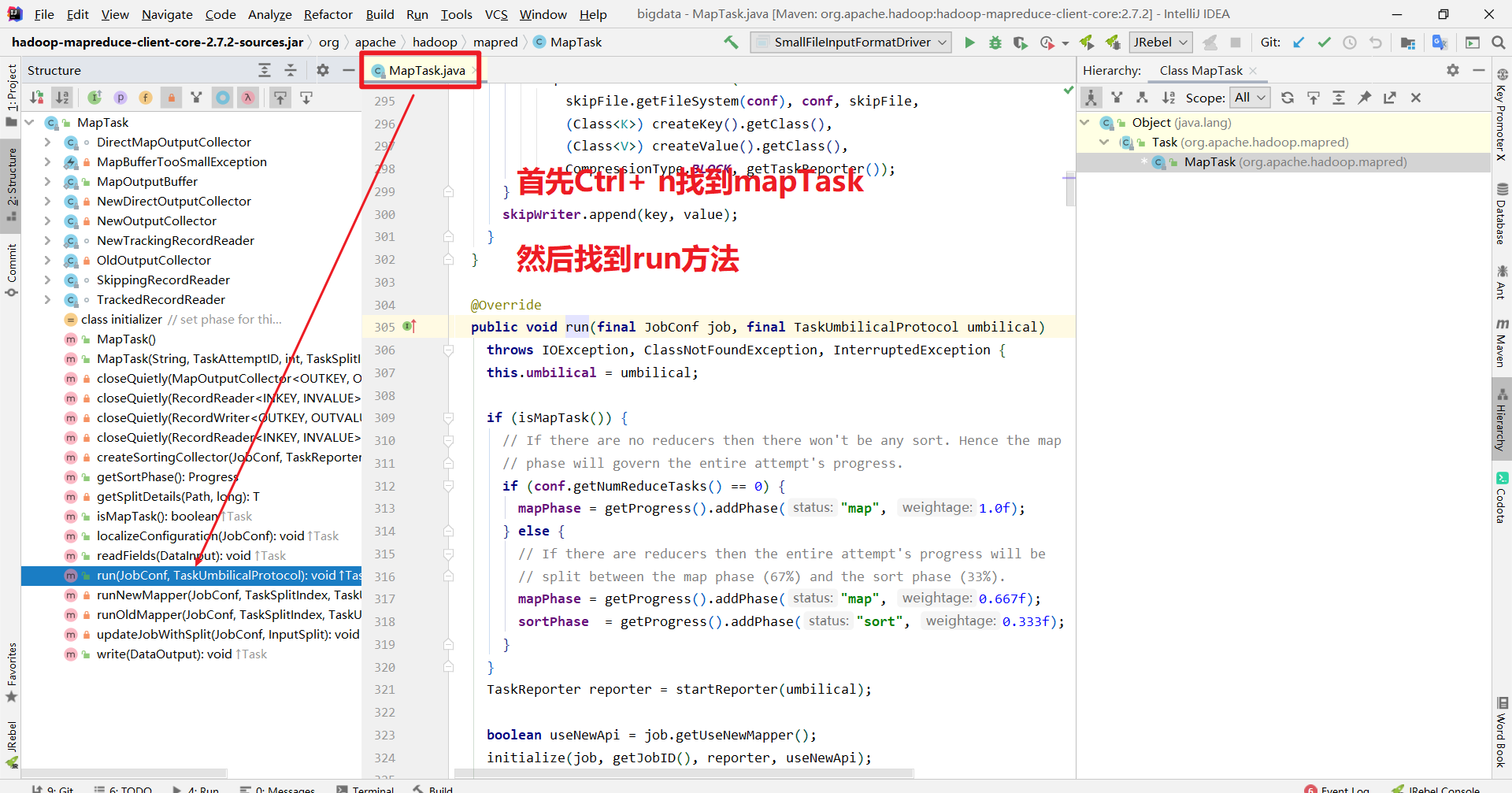
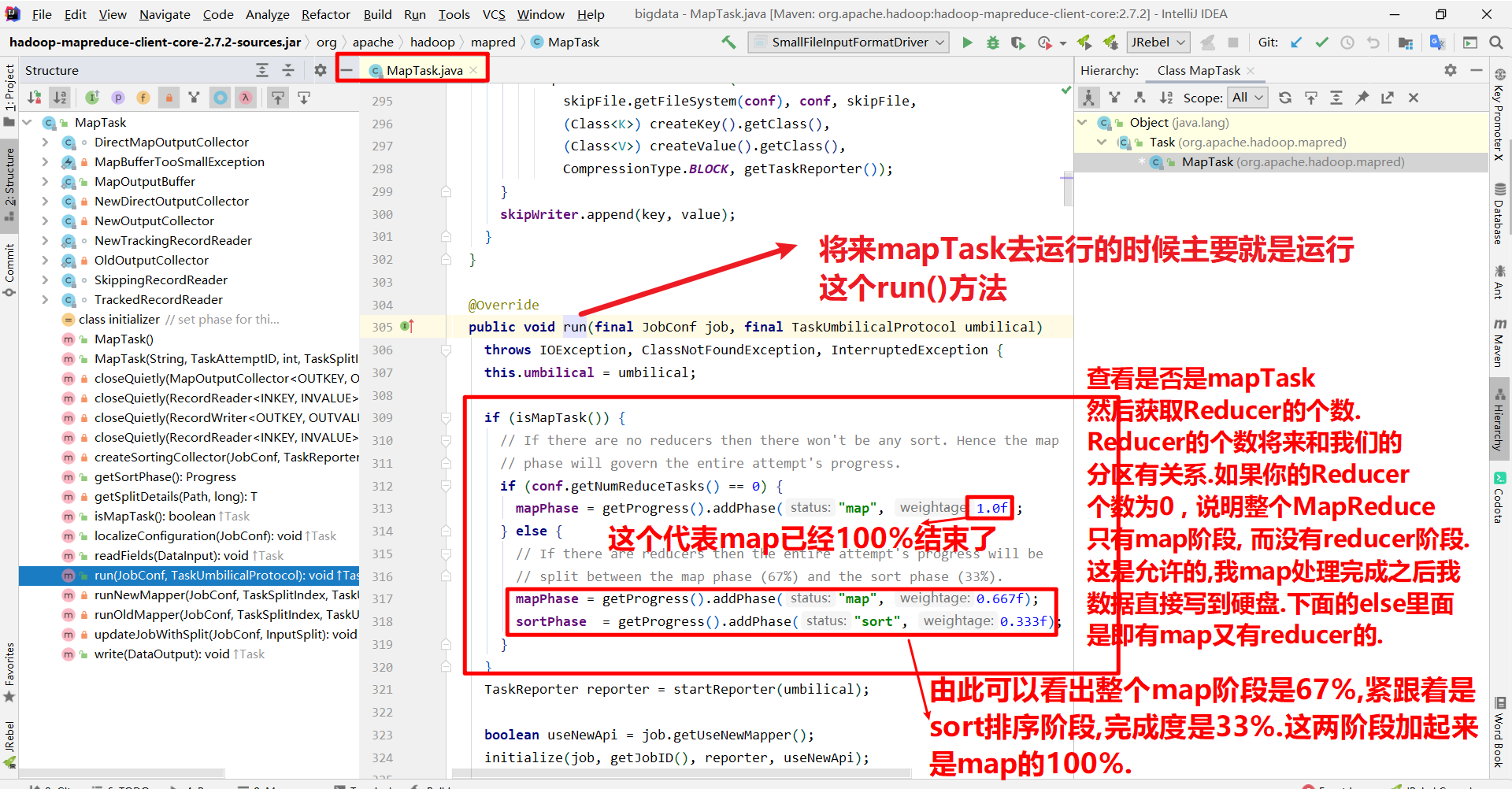
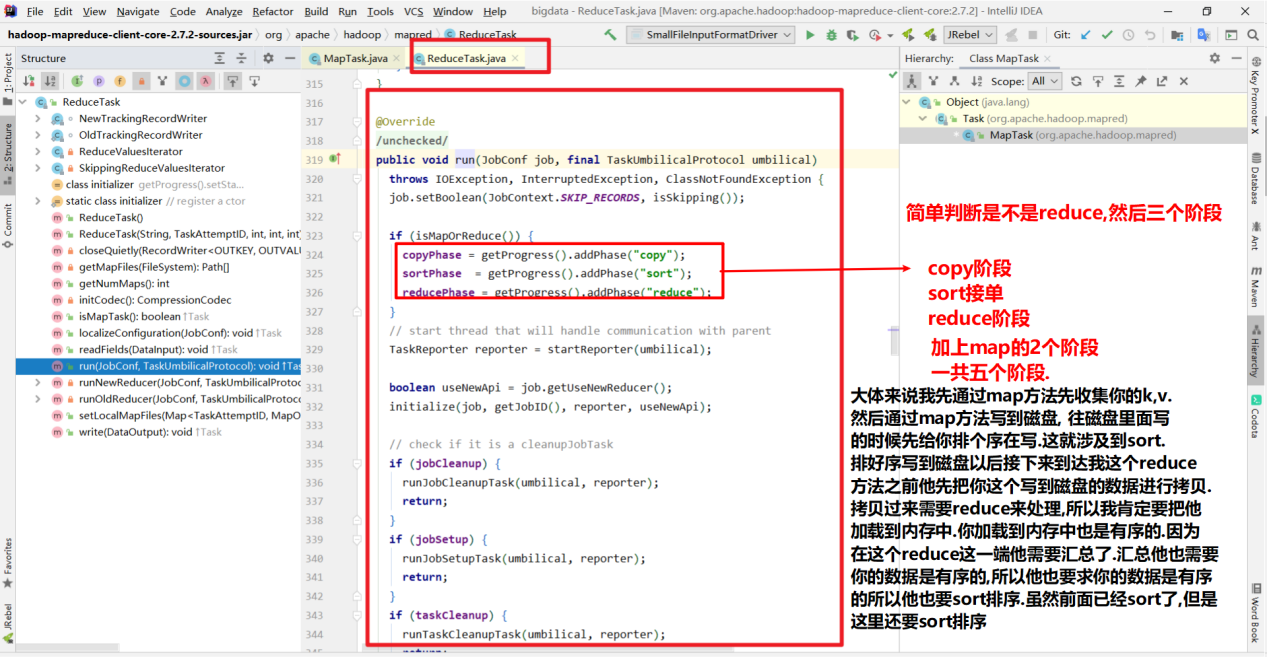
首先我们在看shuffle机制之前先了解一下 shuffle过程的前一个过程和后一个过程, 即,mapTask过程和ReduceTask过程.
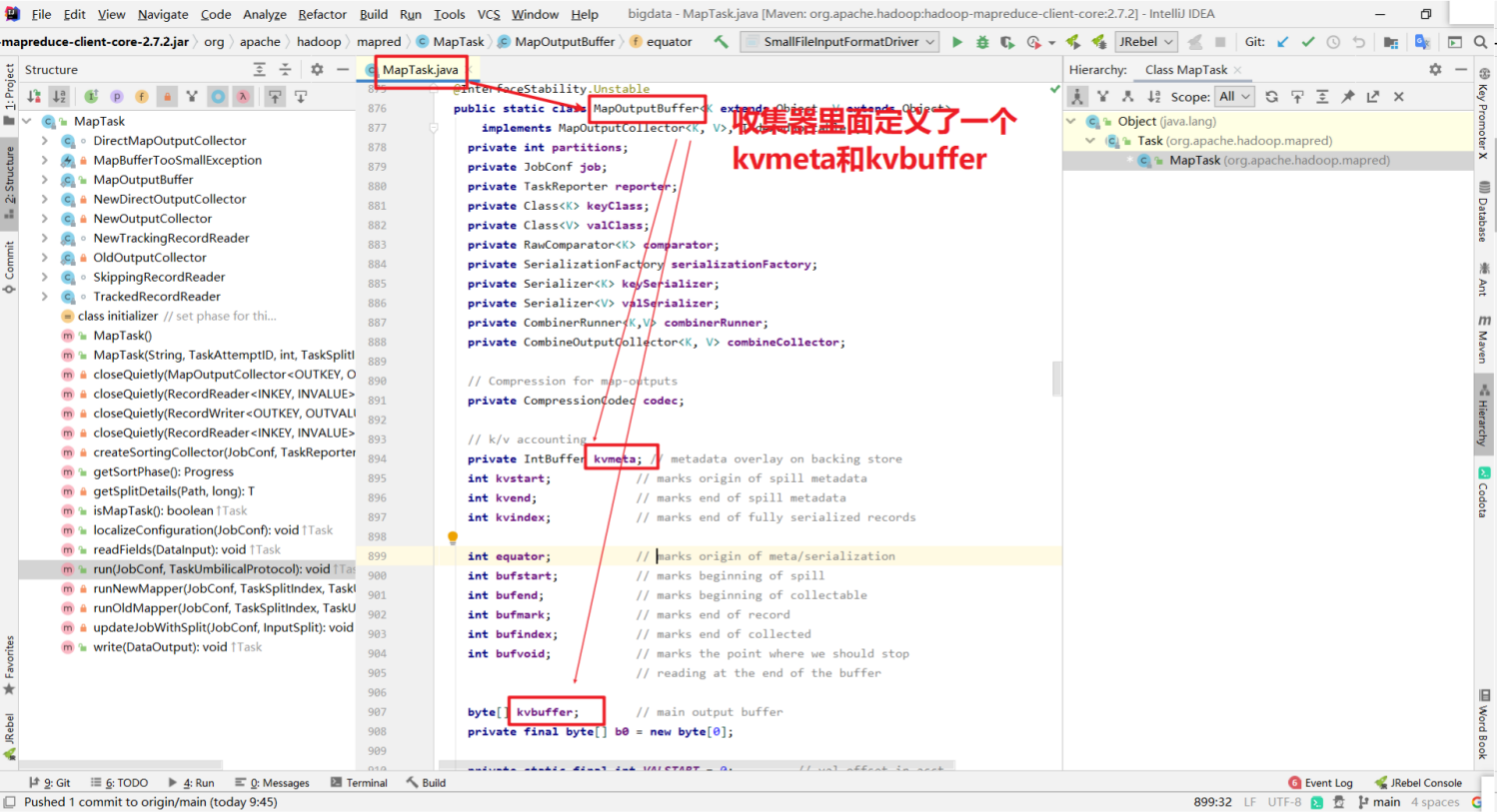
通过源码简单了解一下mapTask和ReduceTask:
因为你我们的mapreduce程序分为mapTask 和 reduceTask. 在中间的过程就是shuffle过程.所以简单看一下mapTask和reduceTask的源码.
mapTask
这是shuffle之前的过程
ReduceTask
这是shuffle之后的过程

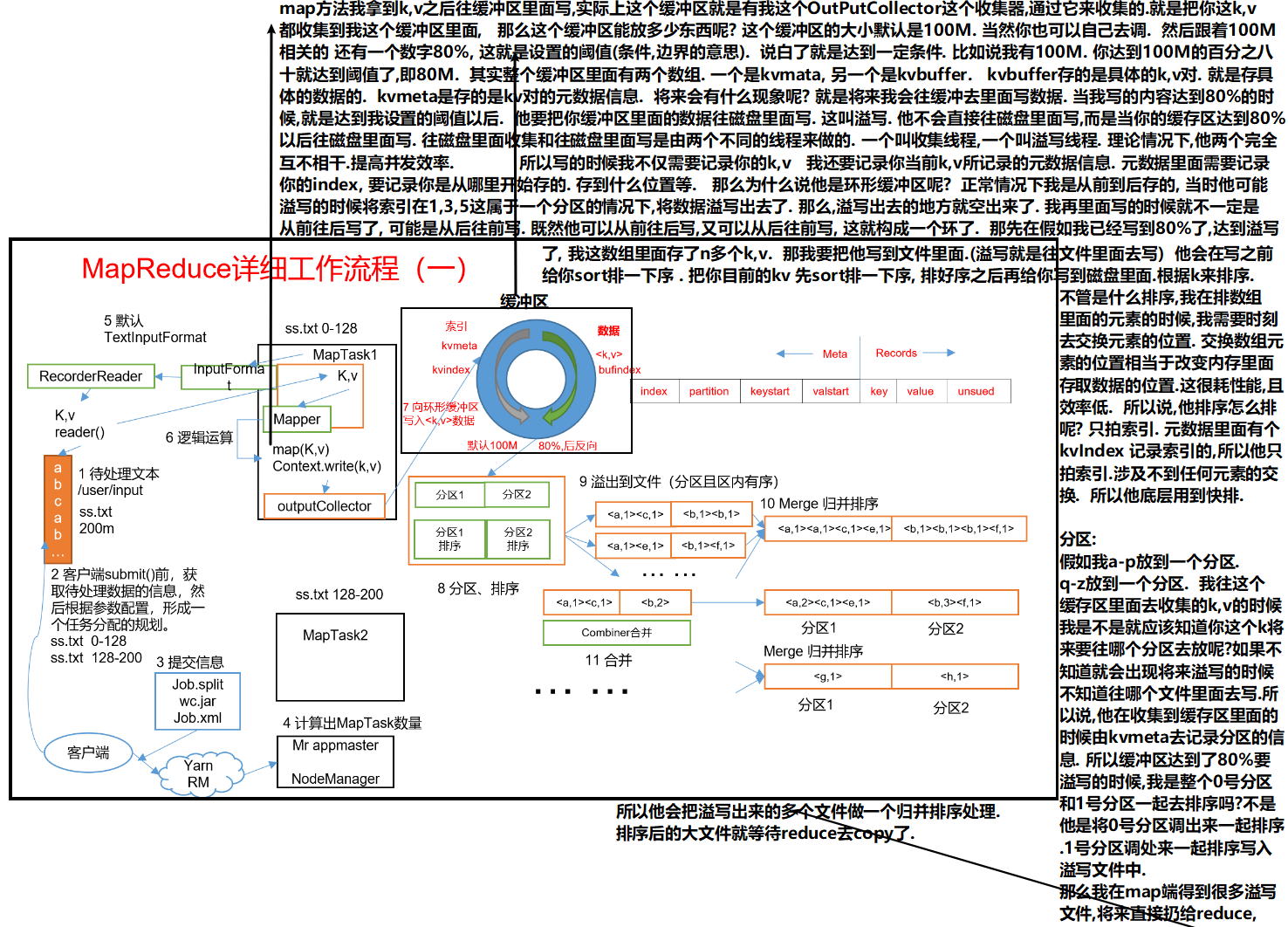
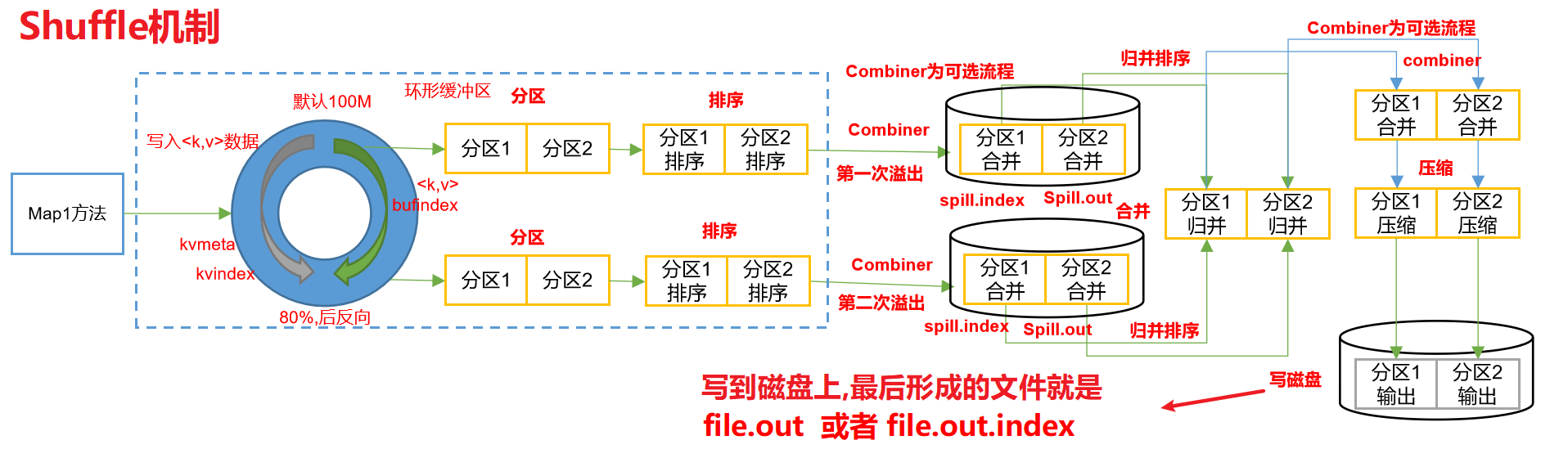
shuffle机制的整个过程图
shuffle过程是在MapTask方法之后,ReduceTask方法之前的数据处理过程称之为Shuffle。
shuffle机制展示图:

对于shuffle机制的解读
Map方法出来之后先进入到getPartition方法,获取是哪一个分区的.
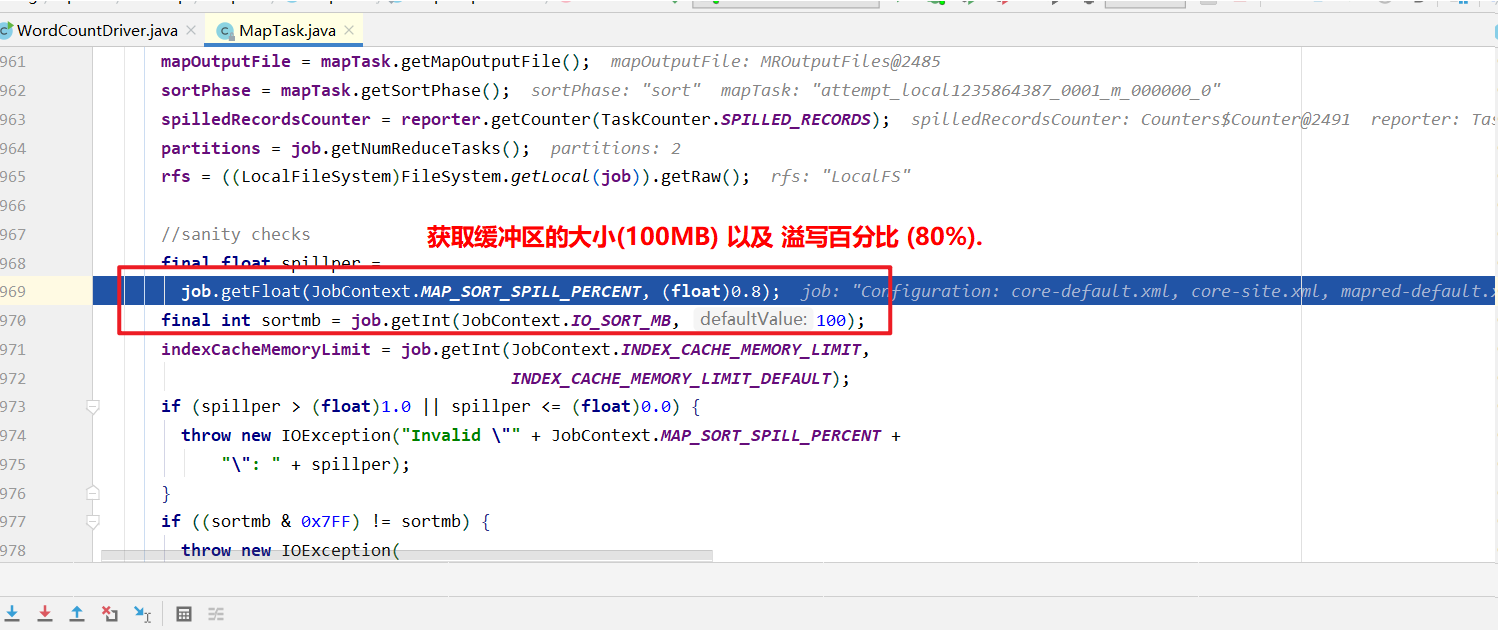
然后进入环形缓冲区.(默认100M,企业开发一般调整到200M,这是优化.) 到达80%溢写.溢写对数据排序. 排序手段是快排. 对key的索引按照字典顺序排 .溢写后产生大量的溢写文件.针对溢写文件进行归并排序. 按照分区放到对应磁盘上等待拉取. reduce拉取对应分区数据放入内存.内存不够放入磁盘. 内存中数据或者磁盘中数据都需要进行归并排序. 排完序后分组. 然后进入到reduce方法.
map端的溢写过程产生的溢写文件进行归并,默认是一次归并10个. 但是随着机器性能提高. 这个也可以提高到20 或者30.
总体上默认的mapTask的内存是1G. 默认的reduceTask也是1G.
通常我们调整做多的是ReduceTask为什么是reduceTask呢?
因为他是一个聚合汇总. 因为mapTask默认是128M的数据.
而reduceTask是将所有数据都聚合到这里面,数据量相对来说大一些
真正开发的时候可以适当调整到4个G左右.
yarn单个节点(就是一个服务器)默认内存是8个G,通长也是需要调整的,一般是跟你的集群的节点内存相等,正常是128G.
yarn的单个任务(就是处理一件事) 默认内存也是8G. 生产过程这些都是需要调整的.
优化:
环形缓冲区.(默认100M,企业开发一般调整到200M,这是优化.)
到达80%溢写.(企业一般调整到90%或者95% 这是优化,调大了减少溢写文件的次数)
这样做可以减少溢写次数这就优化了. 对文件进行归并排序前可以进行一次Combiner.前提条件是不影响业务.比如求和,汇总业务不影响. 求平均值就影响.
Combiner之后进行归并排序. 然后放到对应分区的磁盘上.
为了减少磁盘io,即为了减少从map端到reduce端的拉取过程采用压缩.减少磁盘io. 在MapReduce整个过程中,map输入端,map输出端,reduce输出端都可以压缩. 输入端需要注意切片,输入端谁支持切片呢?那种压缩支持切片呢?LZO支持切片.LZO里面需要额外的建立索引. 如果LZO里面没有建立索引,那就不支持切分.
reduce默认拉取磁盘数据是5个.但是我们可以增大到10个或者20个.前提条件是机器性能和内存.
通常map输出端的压缩使用snappy或者LZO
对于shuffle机制中的缓存区解释图
以后我们在做一些操作的时候, 能没有reducer的话, 就不写Reducer.
因为整个MapReduce任务中, shuffle是最耗费时间的. 因为你Reducer没有shuffle也就没有了. 那么这个程序性能就比较高.
Shuffle过程源码解读
1 | 1.根据ReduceTask的个数决定获取哪个输出对象。 |
Shuffle过程源码解读图示
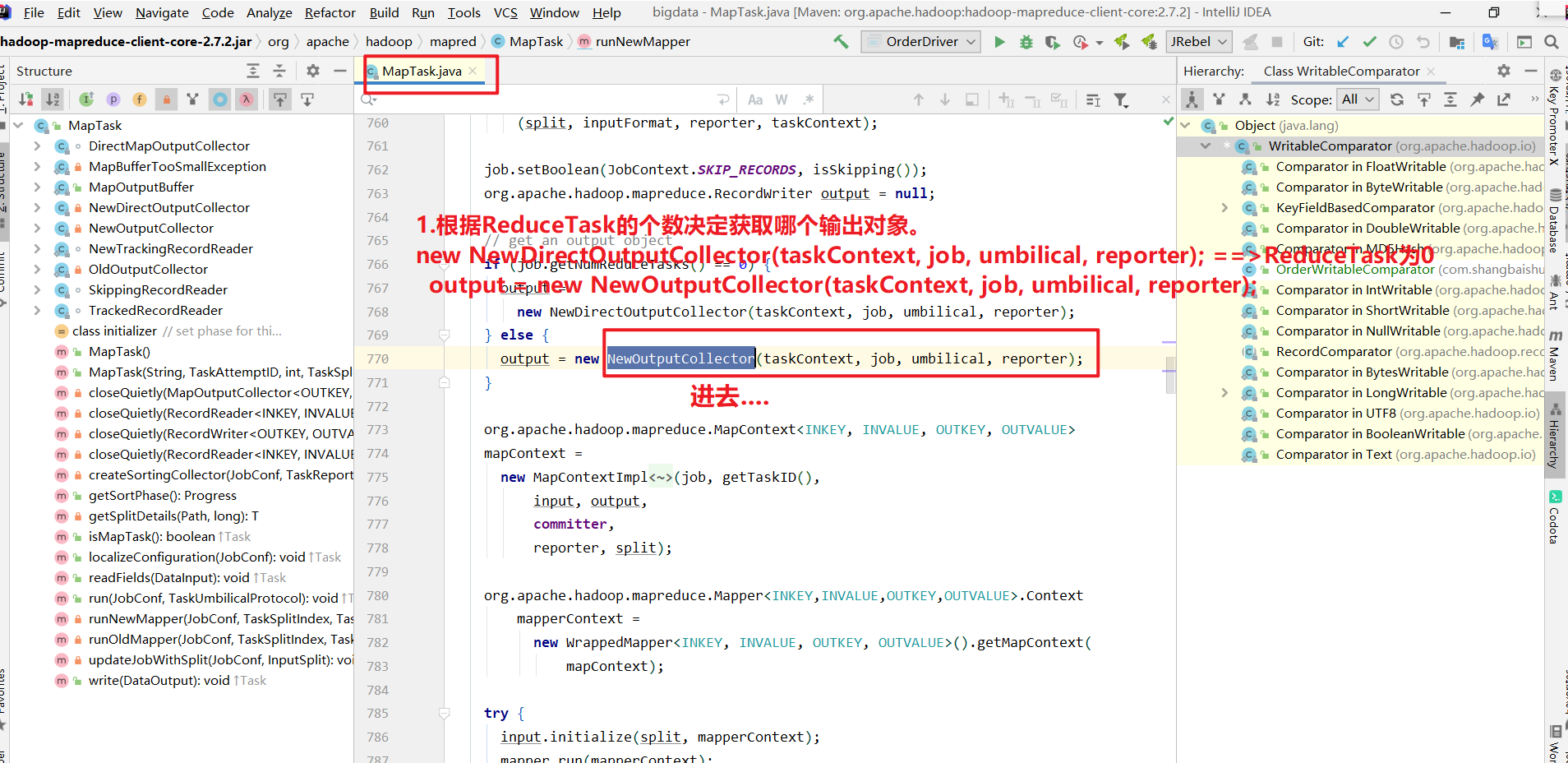
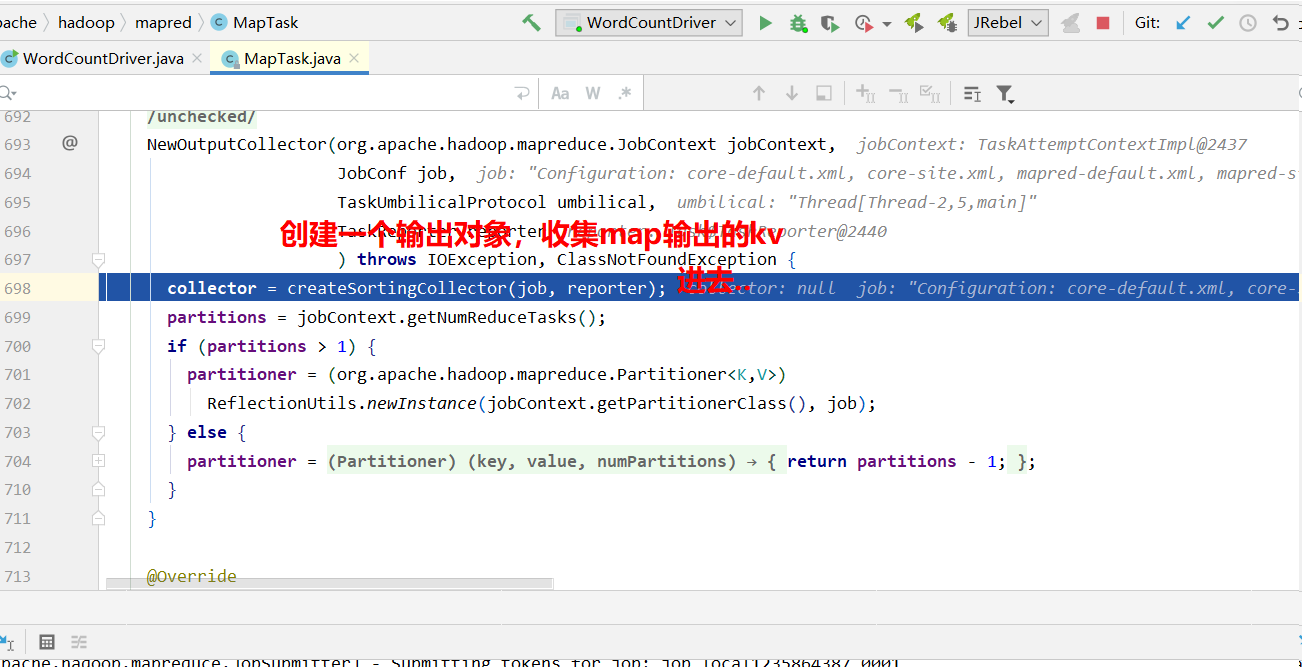
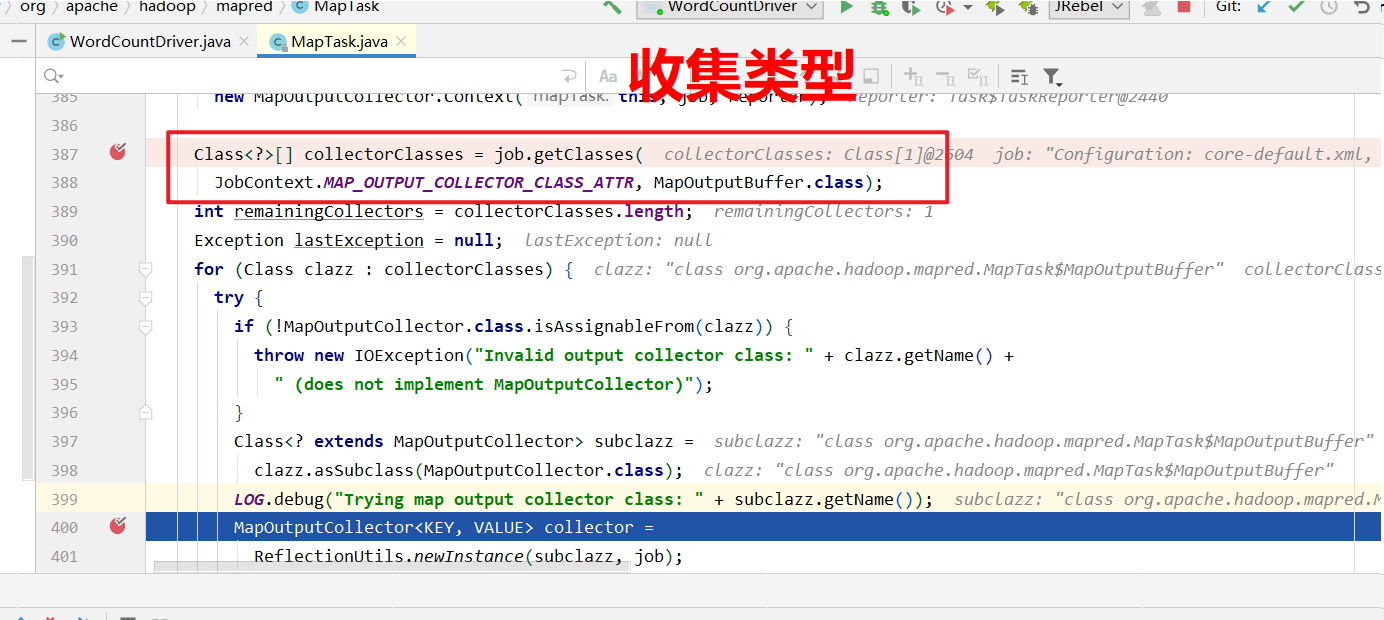
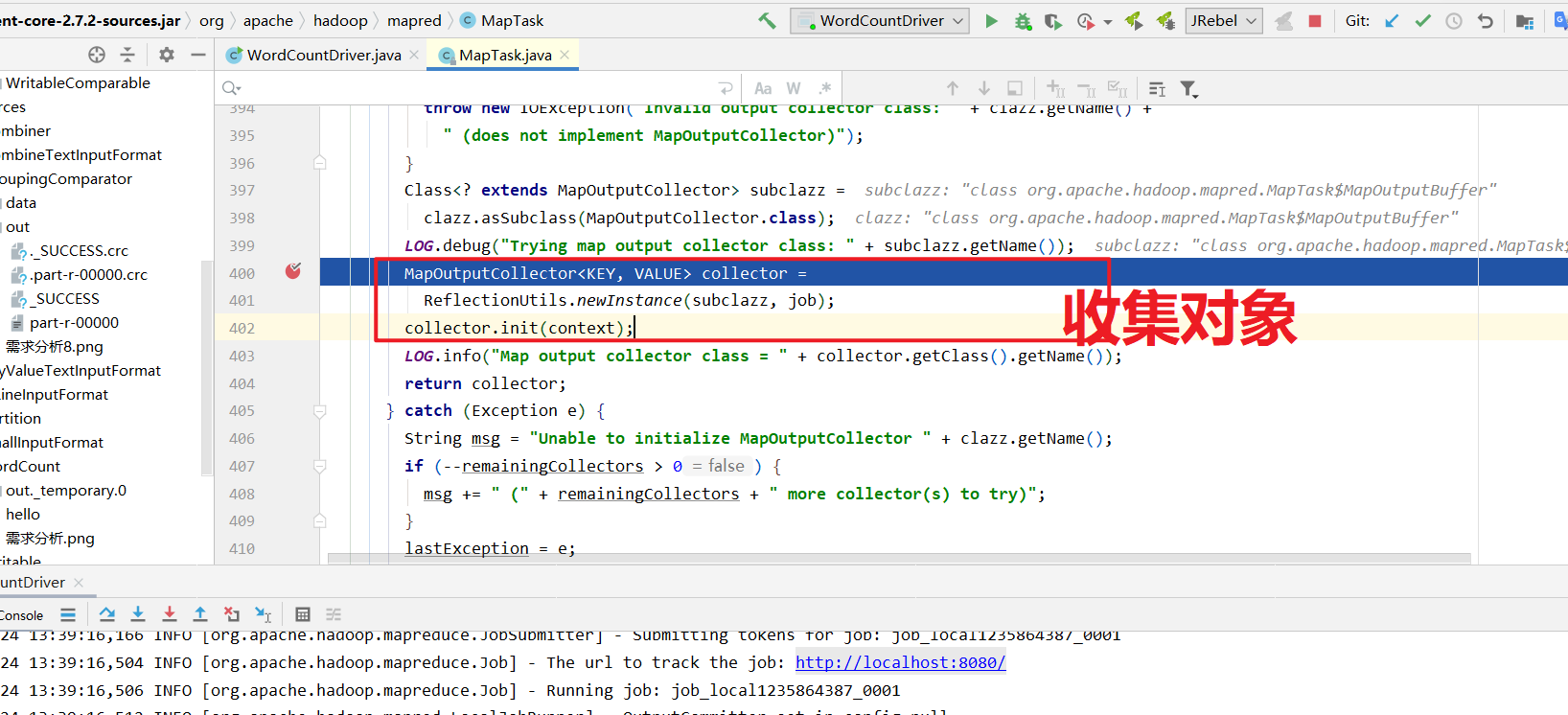
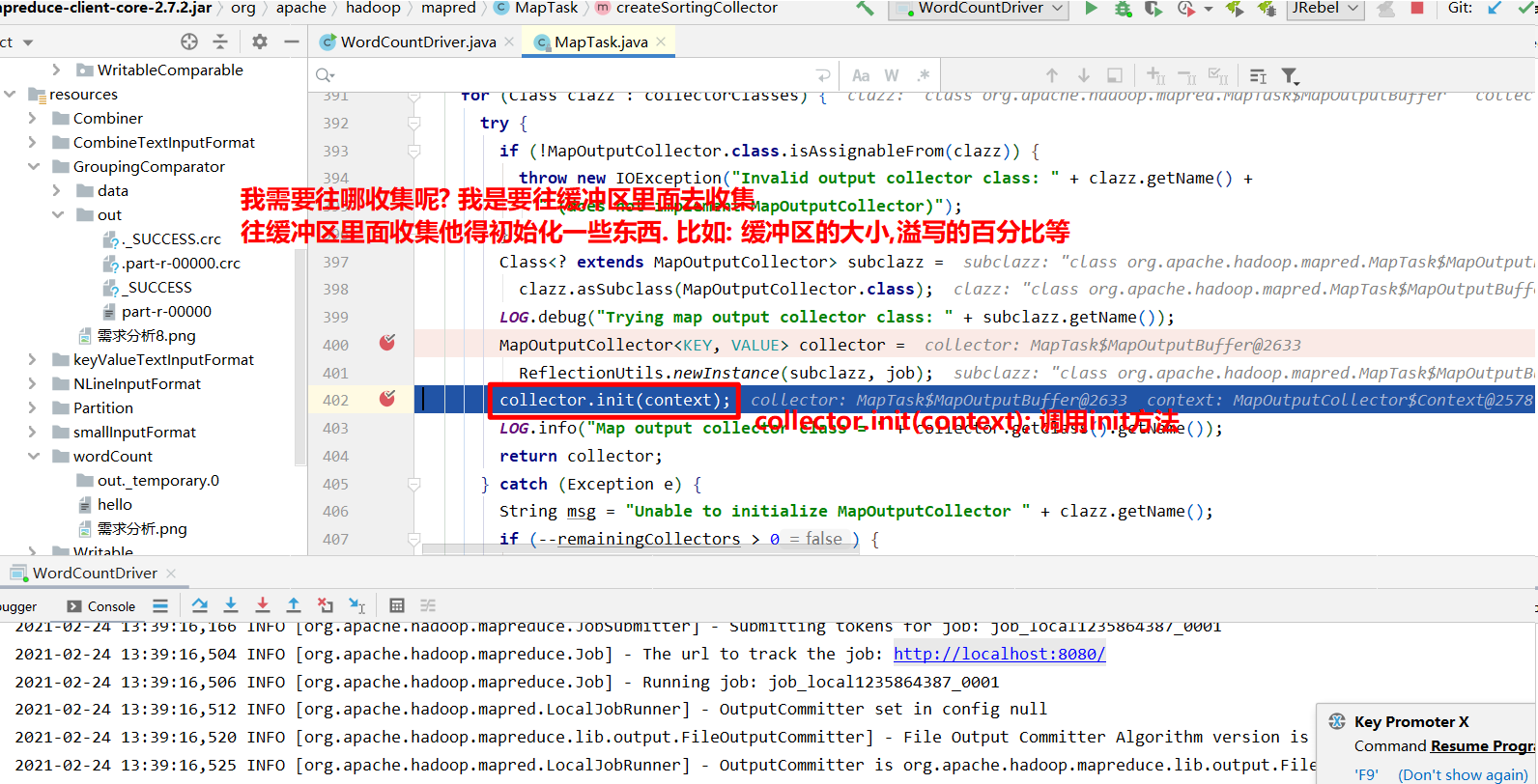
进入collector.init(context)里面.
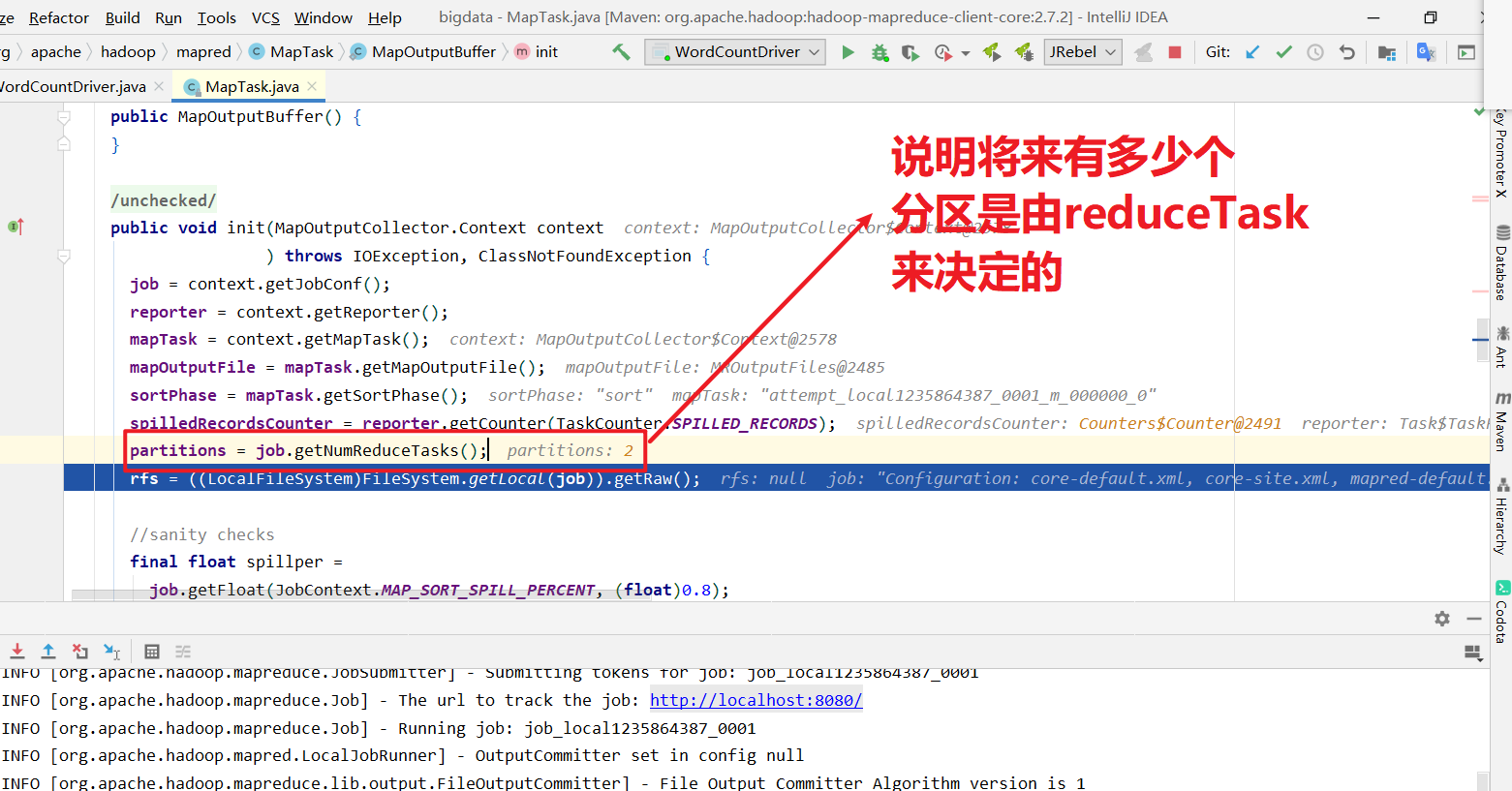
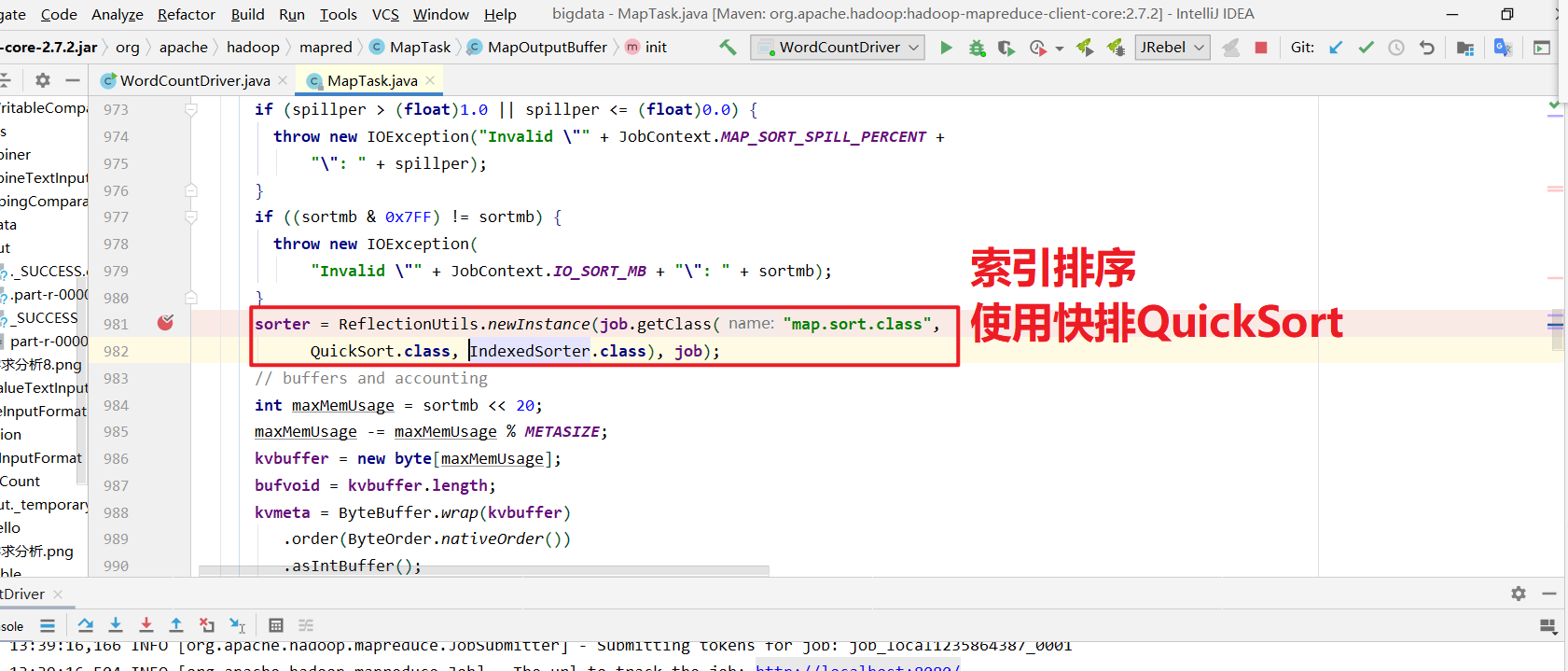
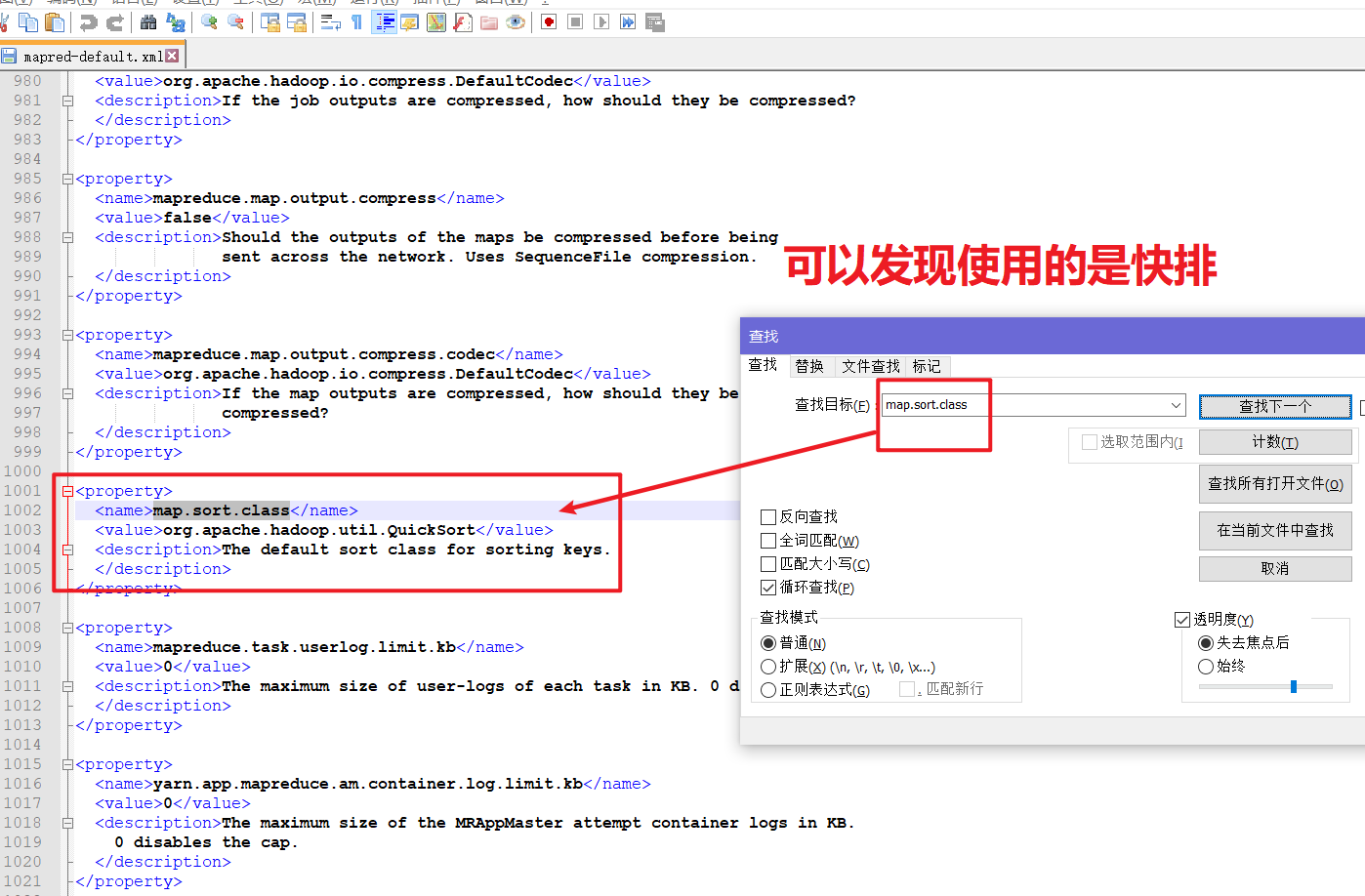
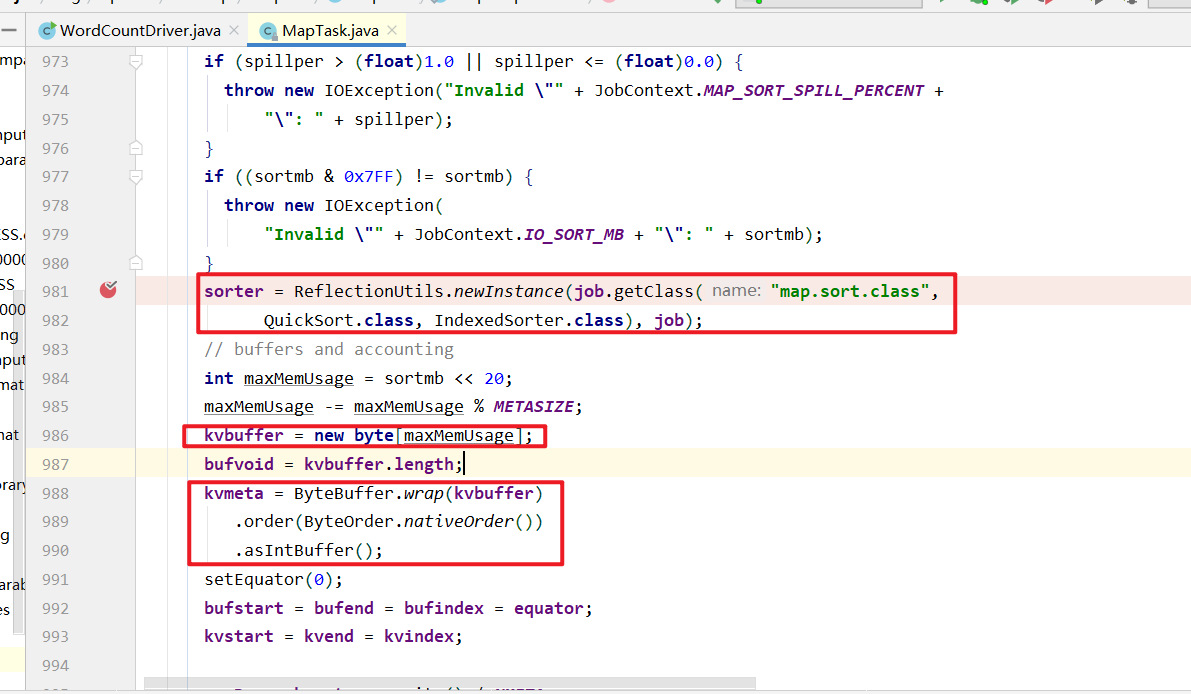
获取到分区器, 计算每个KV对应的分区号,溢写的时候将kv写到对应的分区文件中.
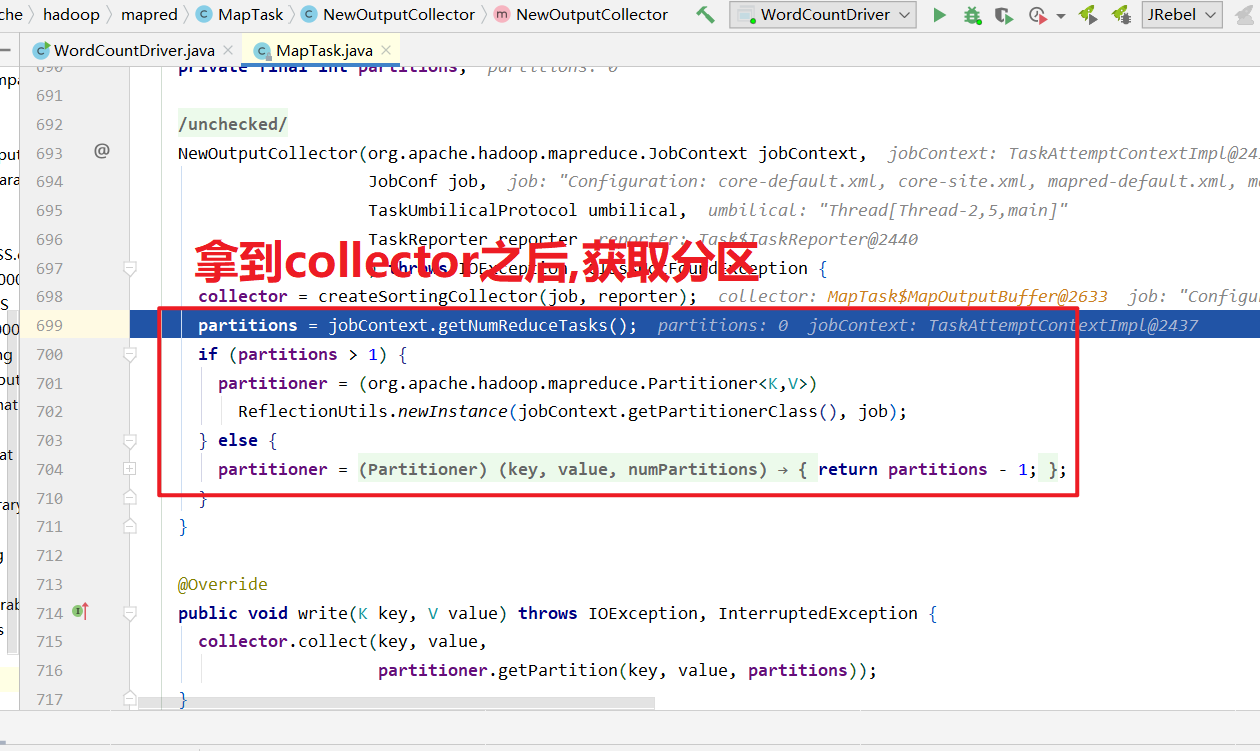
源码: (上面部分只是准备过程, 这里开始是执行过程)
1 | 2. Mapper方法执行,写出去KV ,collector收集, 达到阈值, 溢写, 最后合并. |
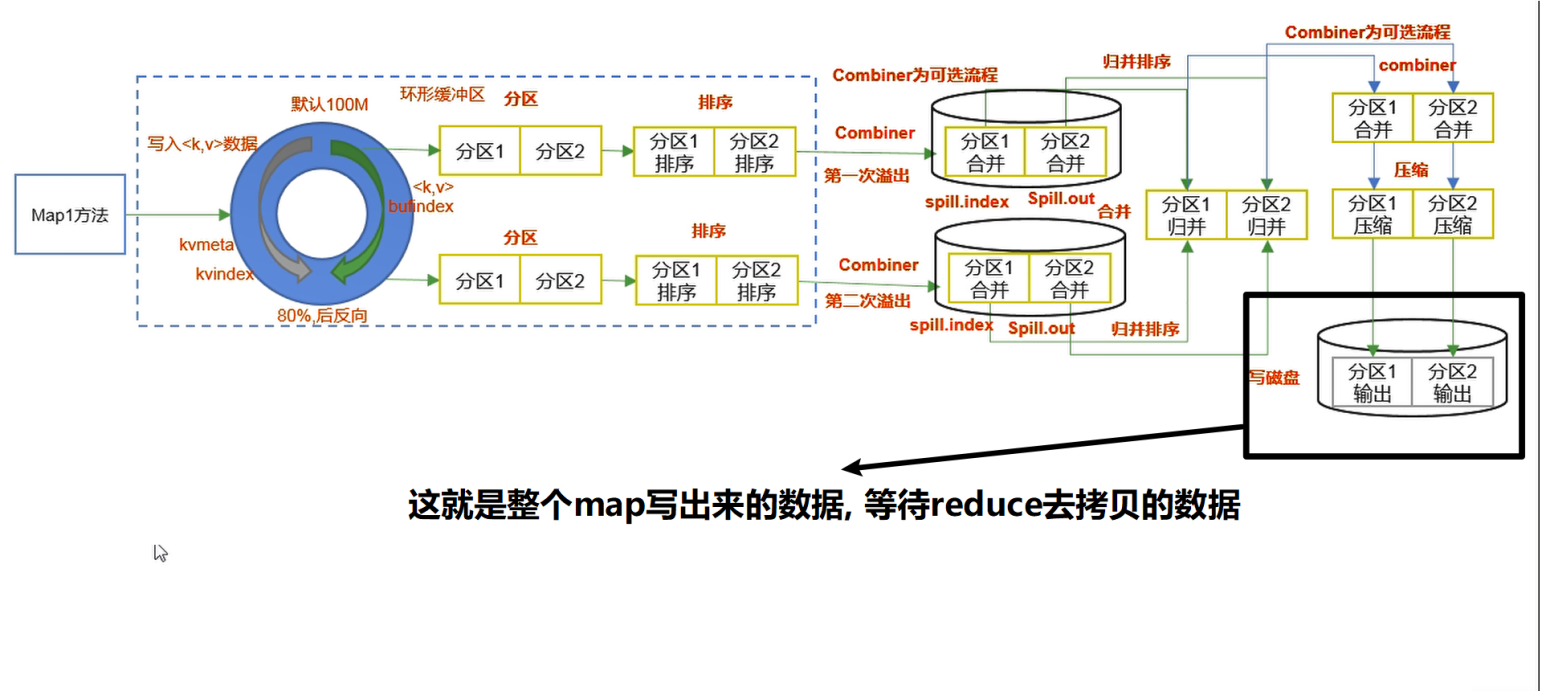
如下图只是一个mapTask的过程, 假如有多个mapTask, 每一个mapTask最终都会去生成file.out或者file.out.index文件
收集器源码
shuffle完成后,从Map写出来的数据过程图
mapreduce过程概括为: InputFormat—-> mapper,shuffle,reducer—>OutputFormat
Partition分区
什么是partition分区呢? 他的作用使用么?
1、问题引出
要求将统计结果照条件输出到不同文件中(分区)比如:将统计结果按照手机归属地不同省份输出到不同文件中(分区)
2、默认Partitioner分区
1 | public class HashPartitioner<K, V> extends Partitioner<K,V>{ |
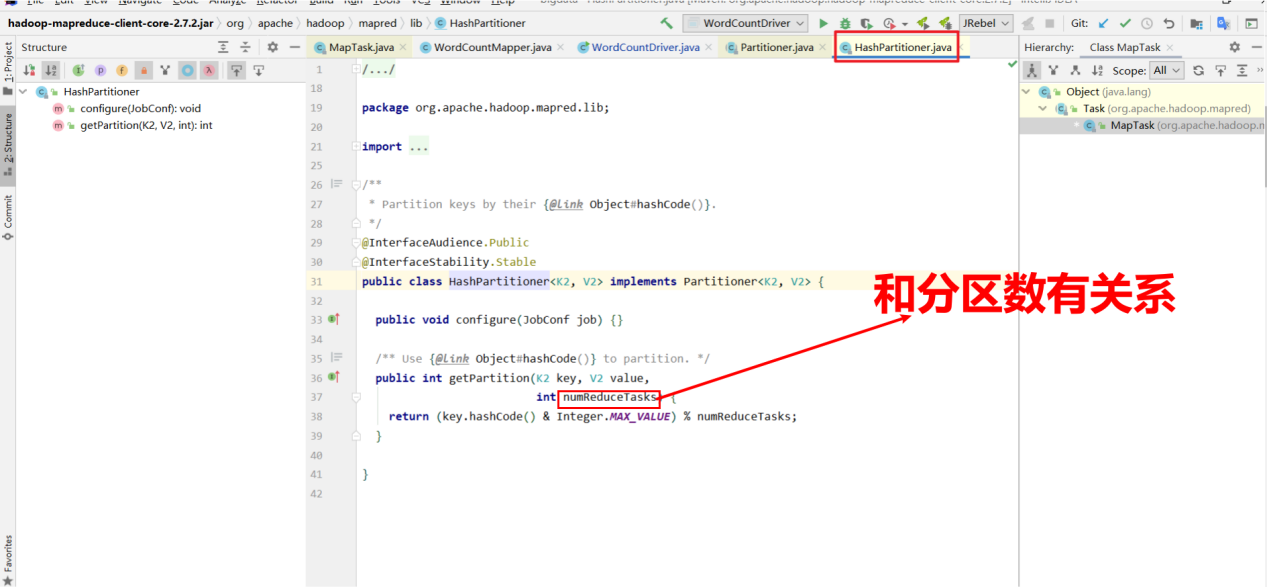
默认分区是根据key的hashCode对ReduceTasks个数取模得到的。用户没法控制哪个key存储到哪个分区。
3、自定义Partitioner步骤及代码
(1)自定义类继承Partitioner,重写getPartition()方法
1 | public class CustomPartitioner extends Partitioner<Text, FlowBean> { |
(2)在Job驱动中,设置自定义Partitioner
1 | job.setPartitionerClass(CustomPartitioner.class); |
(3)自定义Partition后,要根据自定义Partitioner的逻辑设置相应数量的ReduceTask
1 | job.setNumReduceTasks(5); |
4、分区总结
(1)如果ReduceTask的数量> getPartition的结果数,则会多产生几个空的输出文件part-r-000xx;
(2)如果1<ReduceTask的数量<getPartition的结果数,则有一部分分区数据无处安放,会Exception;
(3)如果ReduceTask的数量=1,则不管MapTask端输出多少个分区文件,最终结果都交给这一个ReduceTask,最终也就只会产生一个 结果文件part-r-00000;
(4)分区号必须从零开始,逐一累加。
5、案例分析
例如:假设自定义分区数为5,则
1 | (1)job.setNumReduceTasks(1); 会正常运行,只不过会产生一个输出文件 |
对于partition分区的总结
块(block): 就是存到hdfs的时候是以什么块为单位.
切片就是MapReduce程序在处理你每一块数据的时候生成的逻辑上的切片信息.
分区就是你的MapReduce处理完我这个数据后,最终往磁盘上输出结果的时候,我最终要输出几个文件. 比如说我要输出3个文件,那也就代 表着我有三个分区. 如果我输出一个文件,就代表只有一个分区. 所以分区简单理解为将来MapReduce处理完成以后他要帮我输出几个文件就是几个分区.
比如说我一堆单词, a-q ,q-p各自放在一个文件中. 那么这两个文件就必须有两个分区来完成. 说白了这两个文件就是两个分区.
如图展示什么是partition分区:

对于一个wordCount案例来讲, 我希望将统计的结果输出到两个文件中, 但是我没有说什么样的分区给到一分区, 什么样的分区给带二分区. 也就是说没有明确告诉那个k,v按照什么样的条件进入什么样的分区呢? 如图设置两个分区:
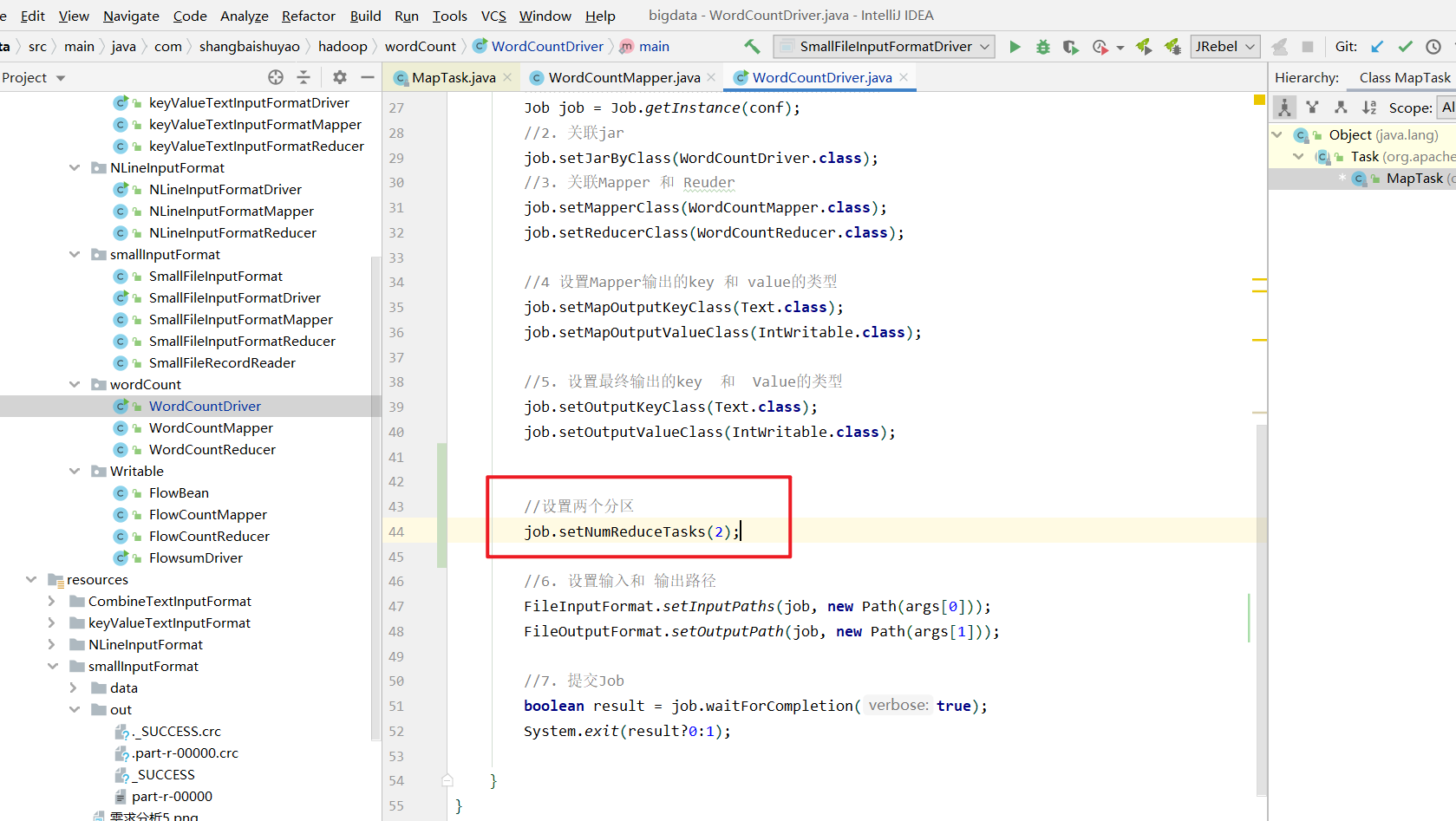
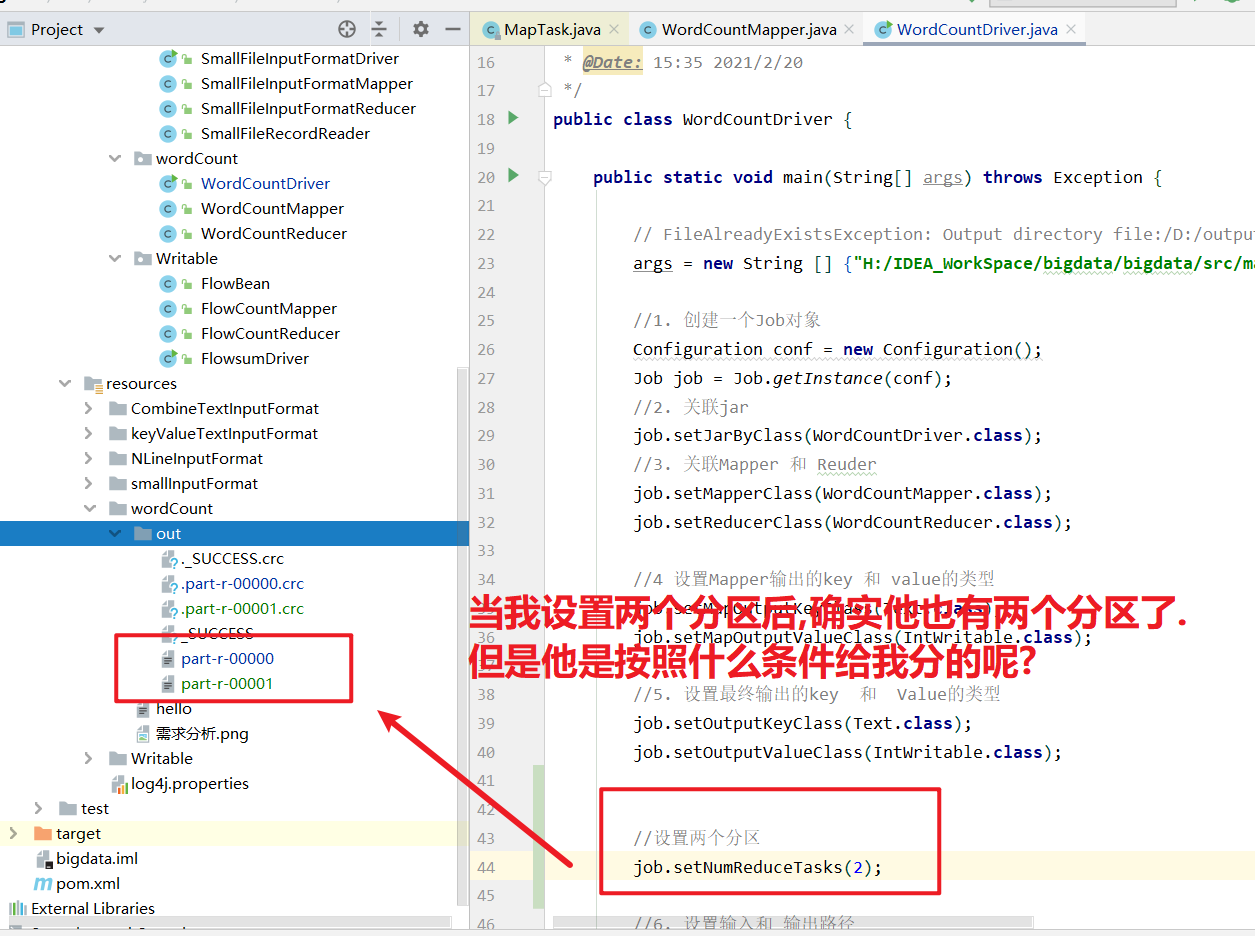
其实他是根据我们的hash算法来帮你区分的. 他会拿上你每一个key的hashcode值去对我的reduce的个数取模,上面我的reduce是2, 任何数字对reduce取模只有可能是0和1. 所以最后我的分区是00000, 00001 即0号分区和1号分区. 简单理解就是我的使用key的hashcode对reduce个数取模, 如果得到是0就往0号分区放. 得到是1就往1号分区放. 所以他默认情况下用的是hash运算. 这就是默认的分区器Partition. 如下图:

Partitioner分区器源码解读
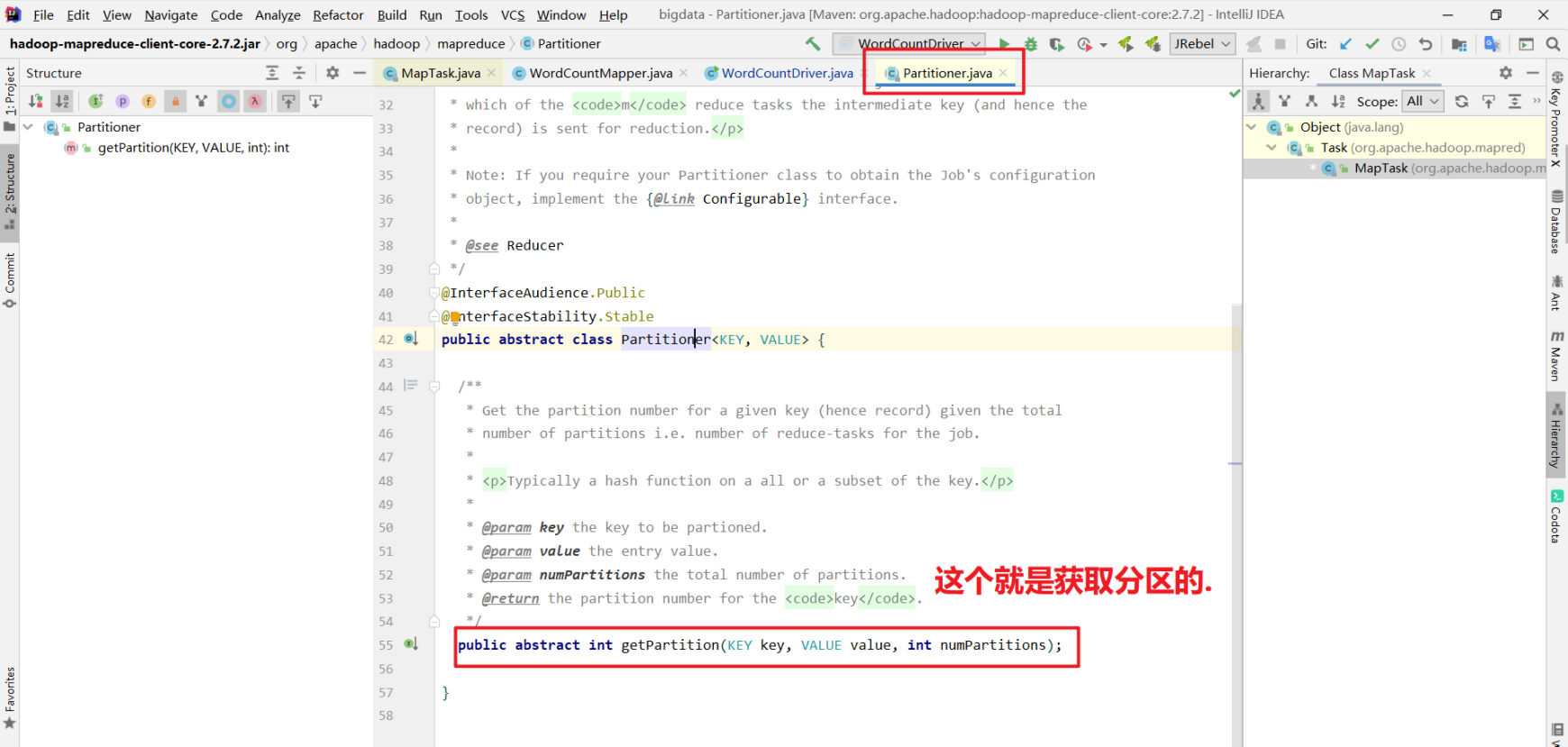
Partitioner: 分区器
默认的分区器: HashPartitioner ,通过key的hashcode值对ReduceTasks的个数取余确定去往哪个分区.
1 | 如何确定分区的: |
WritableComparable排序
溢写到磁盘需要sort排序, 合并成大文件需要排序
排序概述
排序是MapReduce框架中最重要的操作之一. MapTask和ReduceTask均会对数据按照key进行排序。该操作属于
Hadoop的默认行为。任何应用程序中的数据均会被排序,而不管逻辑上是否需要。
默认排序是按照排序,且实现该排序的方法是快速排序。
对于MapTask,它会将处理的结果暂时放到环形缓冲区中,当环形缓冲区使用率达到一定阈值后,再对缓冲区中的数据进行一次快速排序,并将这些有序数据溢写到磁盘上,而当数据处理完毕后,它会对磁盘上所有文件进行归并排序。
对于ReduceTask,它从每个MapTask上远程拷贝相应的数据文件,如果文件大小超过一定阈值,则溢写磁盘上,否则存储在内存中。如果磁盘上文件数目达到一定阈值,则进行一次归并排序以生成一个更大文件;如果内存中文件大小或者数目超过一定阈值,则进行一次合并后将数据溢写到磁盘上。当所有数据拷贝完毕后,ReduceTask统一对内存和磁盘上的所有数据进行一次归并排序。

排序分类
(1)部分排序
MapReduce根据输入记录的键对数据集排序。保证输出的每个文件内部有序。
(2)全排序
最终输出结果只有一个文件,且文件内部有序。实现方式是只设置一个ReduceTask。但该方法在
处理大型文件时效率极低,因为一台机器处理所有文件,完全丧失了MapReduce所提供的并行架构。
(3)辅助排序:(GroupingComparator分组)
在Reduce端对key进行分组。应用于:在接收的key为bean对象时,想让一个或几个字段相同(全部字段比较不相同)的key进入 到同一个reduce方法时,可以采用分组排序。
(4)二次排序
在自定义排序过程中,如果compareTo中的判断条件为两个即为二次排序。
自定义排序WritableComparable及代码
原理分析
bean对象做为key传输,需要实现WritableComparable接口重写compareTo方法,就可以实现排序。
Combiner合并
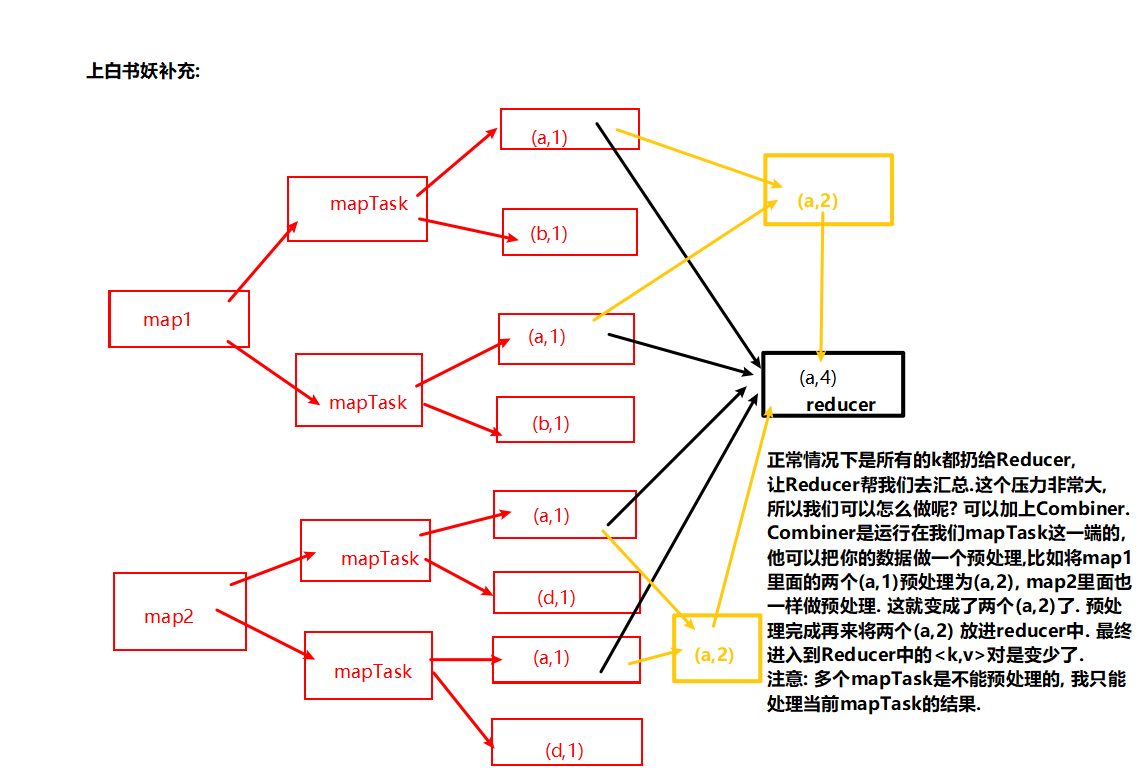
Combiner虽然继承Reducer,但是他是在mapTask过程中运行的, 而Reducer是在reduceTask过程中运行的.
(1)Combiner是MR程序中Mapper和Reducer之外的一种组件。
(2)Combiner组件的父类就是Reducer。
(3)Combiner和Reducer的区别在于运行的位置
Combiner是在每一个MapTask所在的节点运行;
Reducer是接收全局所有Mapper的输出结果;
(4)Combiner的意义就是对每一个MapTask的输出进行局部汇总,以减小网络传输量。
(5)Combiner能够应用的前提是不能影响最终的业务逻辑,而且,Combiner的输出key,value应该跟Reducer的输入key,value类型要 对应起来。
如下所示:
1 | Mapper Reducer |
( 6)自定义Combiner实现步骤
(a) 自定义一个Combiner继承Reducer,重写Reduce方法
1 | public class WordcountCombiner extends Reducer<Text, IntWritable, Text,IntWritable>{ |
(b) 在Job驱动类中设置
1 | job.setCombinerClass(WordcountCombiner.class); |
对于运行结果展示:
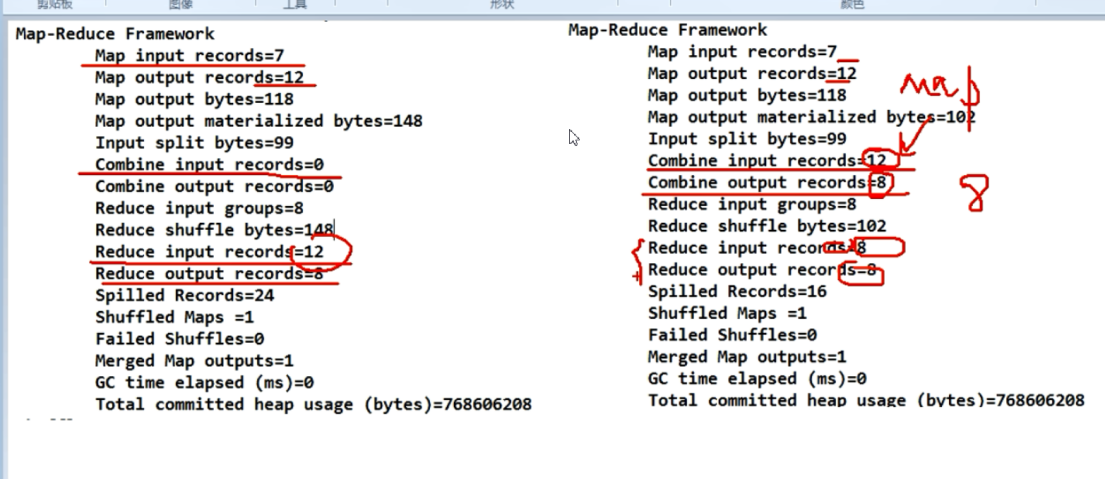
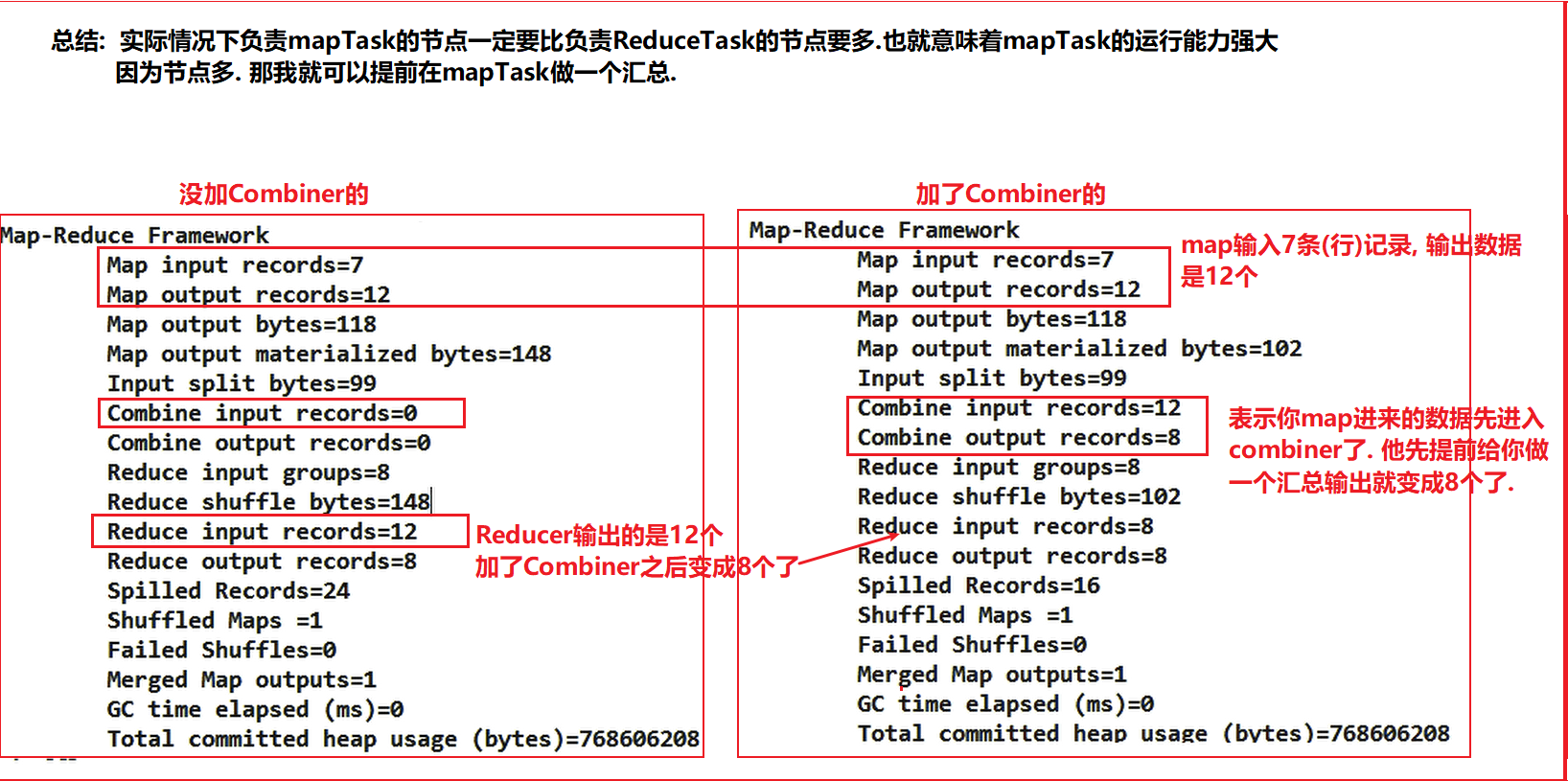
mapreduce过程概括为: InputFormat—-> mapper,shuffle,reducer—>OutputFormat
最后就是计算好的结果输出问题了.
OutputFormat数据输出
和InputFormat一样,OutputFormat也有许多接口实现类.
OutputFormat接口实现类
OutputFormat是MapReduce输出的基类,所有实现MapReduce输出都实现了OutputFormat接口。下面我们介绍几种常见的OutputFormat实现类。
1.文本输出TextOutputFormat
默认的输出格式是TextOutputFormat,它把每条记录写为文本行。它的键和值可以是任意类型,因为TextOutputFormat调用toString()方法把它们转换为字符串。
2.SequenceFileOutputFormat
将SequenceFileOutputFormat输出作为后续 MapReduce任务的输入,这便是一种好的输出格式,因为它的格式紧凑,很容易被压缩。
- 自定义OutputFormat
根据用户需求,自定义实现输出。
自定义OutputFormat

MapReduce开发总结



- 本文作者: xubatian
- 本文链接: http://xubatian.cn/mapreduce过程中的shuffle机制原理/
- 版权声明: 本博客所有文章除特别声明外均为原创,采用 CC BY 4.0 CN协议 许可协议。转载请注明出处:https://www.xubatian.cn/
 故人的博客
故人的博客
 IT周的博客
IT周的博客
 大胖胖的笔记
大胖胖的笔记
 常瑞的部落落
常瑞的部落落
 Fortune博客
Fortune博客
 星空下的YZY
星空下的YZY
 BOBL技术博客
BOBL技术博客