

Kafka 概述
kafka定义

消息队列
目 前企 业中比 较常 见的 消息 队列产 品主 要有 Kafka、ActiveMQ 、RabbitMQ 、RocketMQ 等。
在大数据场景主要采用 Kafka 作为消息队列。在 JavaEE 开发中主要采用 ActiveMQ、RabbitMQ、RocketMQ。
传统消息队列的应用场景
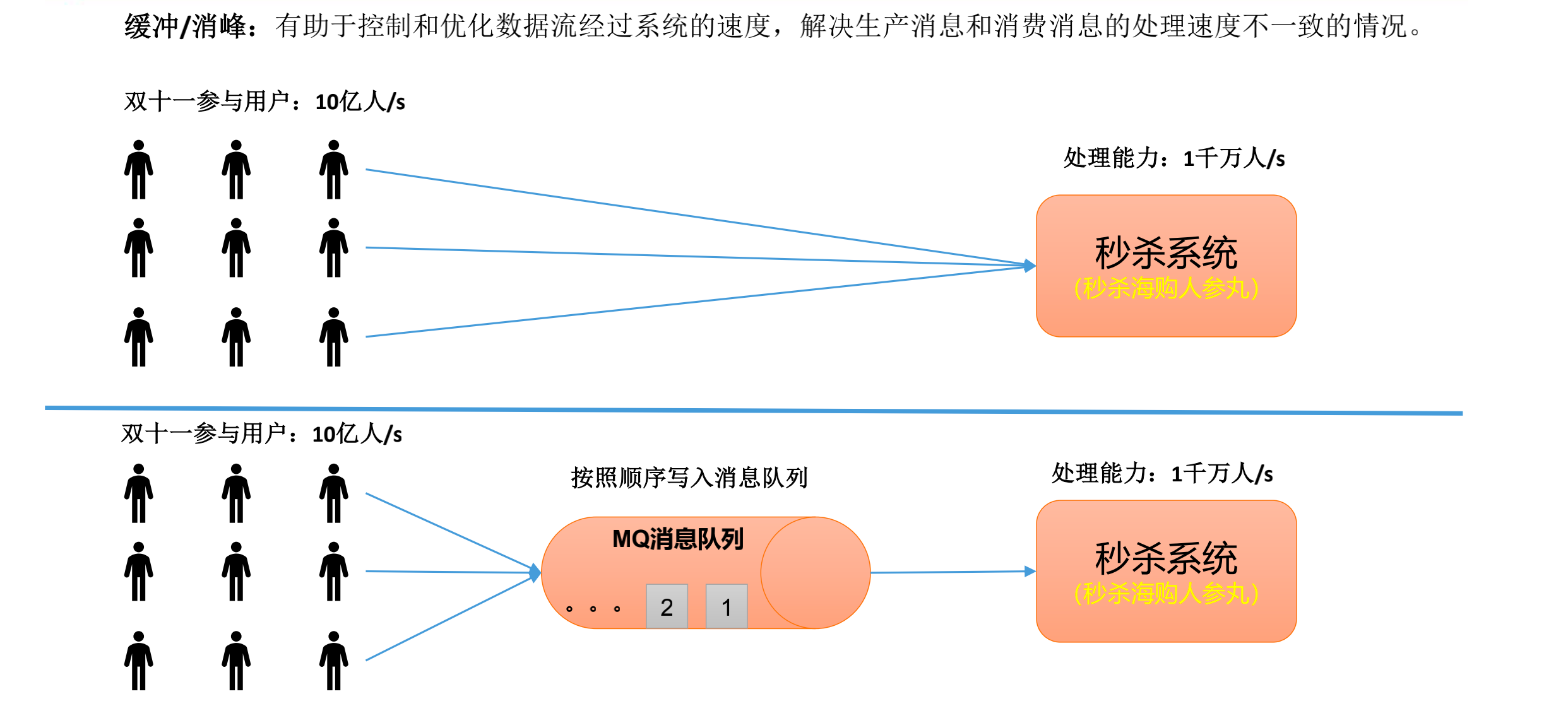
传统的消息队列的主要应用场景包括:缓存/消峰、解耦和异步通信。
消息队列的应用场景——缓冲/消峰
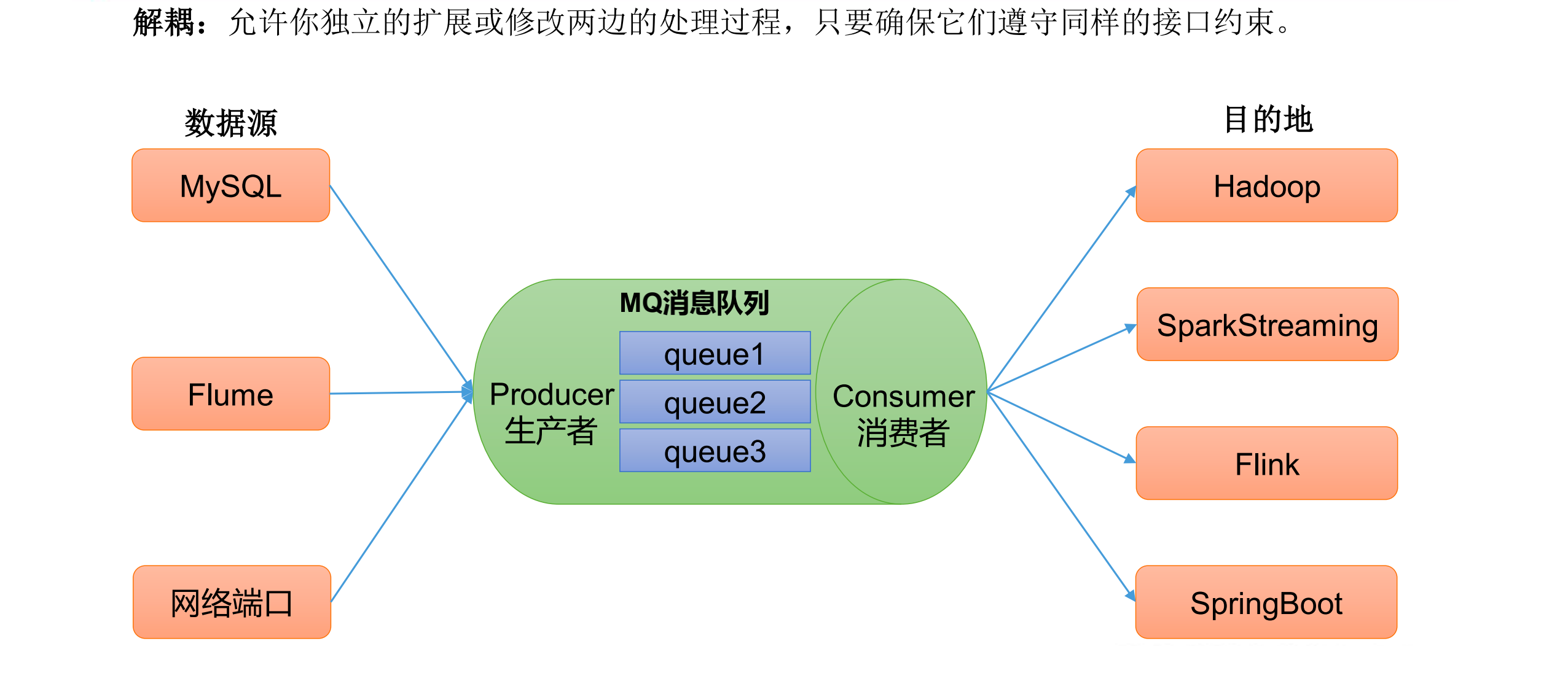
消息队列的应用场景——解耦
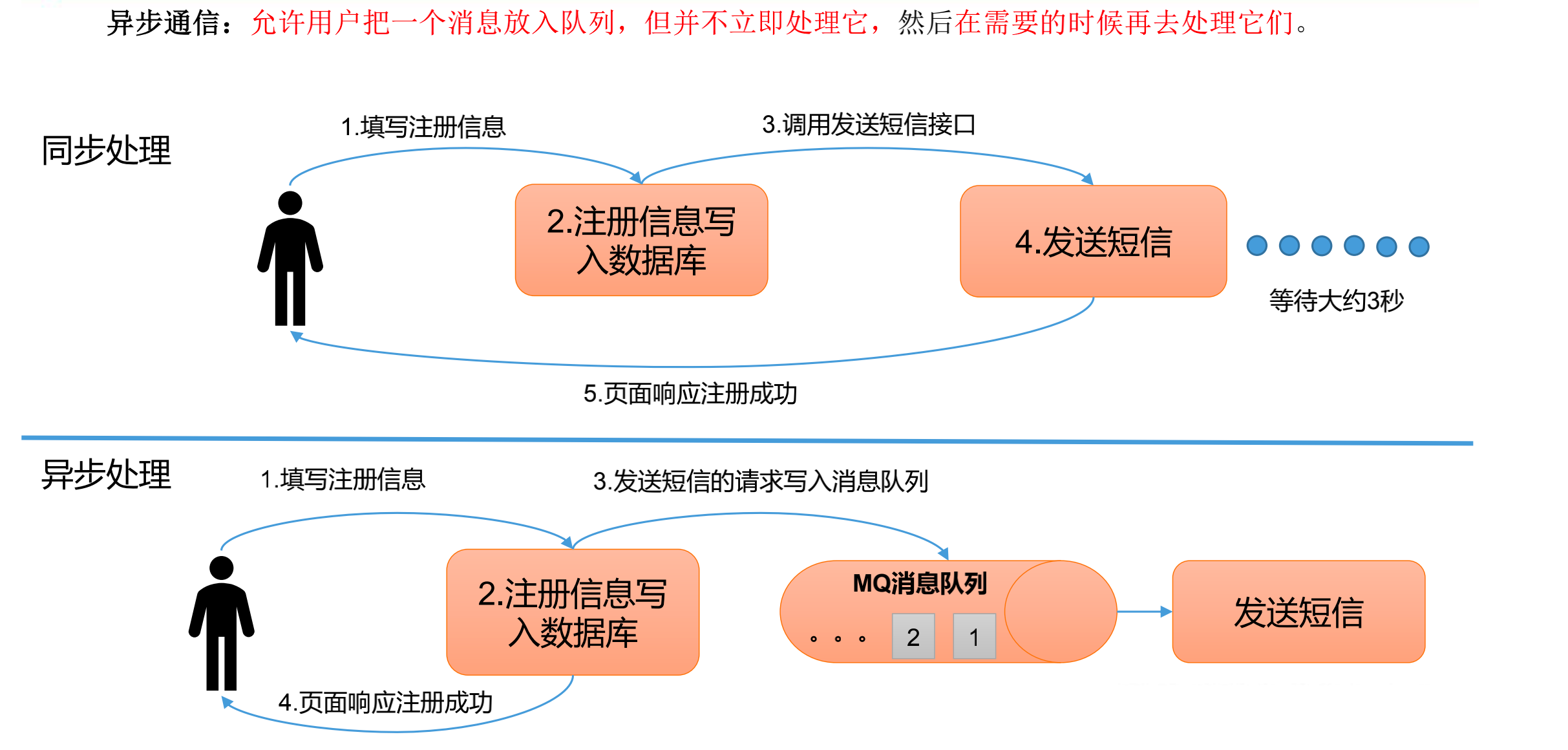
消息队列的应用场景——异步通信
消息队列的两种模式(Rabbit MQ,Active MQ,kafka)
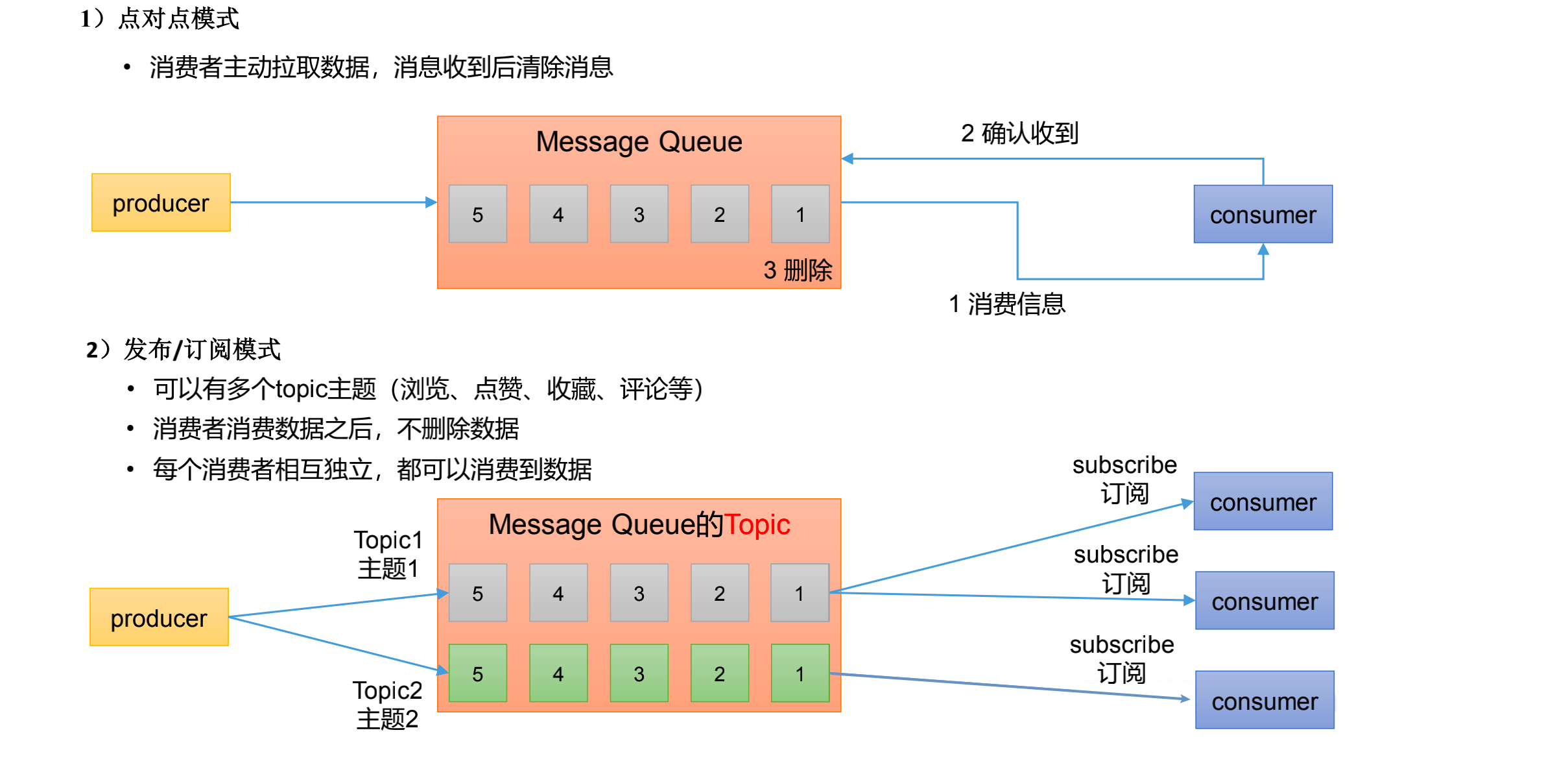
Kafka 基础架构
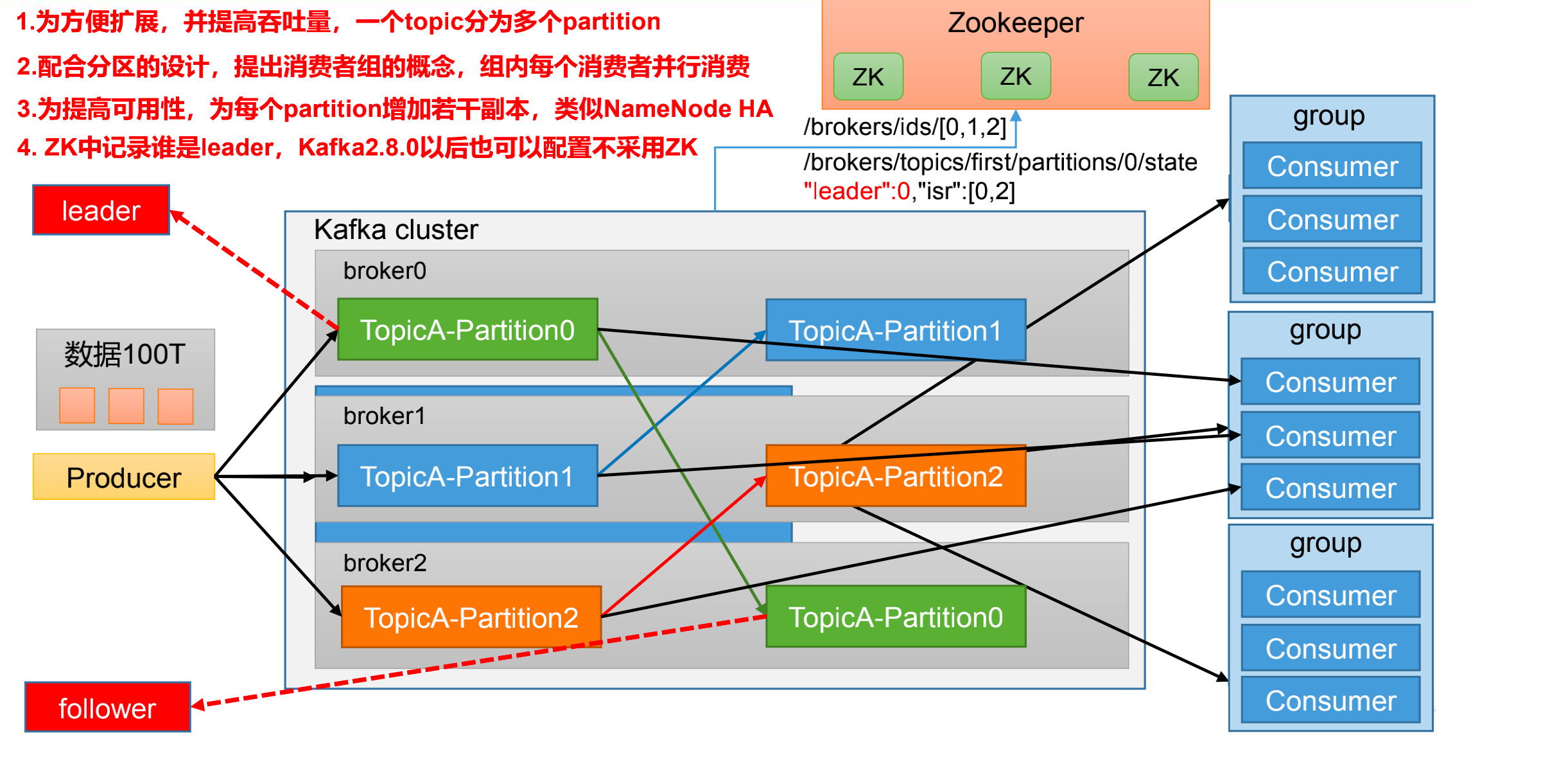
100T的数据存储到一台服务器上,一台服务器一般是8-90T. 所以不能存下. 所以,遇到海量数据分而治之. 把100T数据切分成几块来处理.
kafka也是采用这种思想. 把100T的数据切割成几块来处理. 就是把一个主题的数据分割成多个partition分区. 100T的数据存到一个主题里面,但是因为数据太大. 我们把这个主题又分为多个分区. 即,100T的数据发往topicA主题当中, 但是我每一台服务器都无法同时存储下这100T数据. 所以我们把这100T数据切割成n份分区.每一个服务器只存储30多T的数据.(broker0,broker1,broker2代表hadoop101,102,103对应的主题名称,即三台服务器)
既然生产切分了,消费要并行消费才会很快. 所以就有消费者组的概念, 消费者组里面有n个消费者,每一个人负责对应的分区. 消费者组就消费你这个topic主题.这样消费就很快. 一个分区的数据只能由一个消费者来消费.
如果一个分区挂了怎么办呢?
考虑到可靠性,kafka可以增加副本. hadoop里面的副本是一样的.但是kafka里面的副本分为 leader和 follower.
无论是生产者和消费者,生产消费的时候只针对leader这个副本进行生产和消费. follower的作用就是,当你的leader挂掉之后,follower有条件成为新的leader.
zookeeper上存了kafka的那些信息?
kafka有一部分信息存在zookeeper里面的.他帮kafka来存储整个集群中那些服务器上线了.也就是记录服务器运行的节点状态.zookeeper还会帮你记录每一个分区谁是leader. 这样后续生产和消费的时候直接找leader. Kafka2.8.0之前,kafka必须要有zookeeper进行配合使用.2.8.0之后就不是必须的了.他是可选的.



- 本文作者: xubatian
- 本文链接: http://xubatian.cn/kafka3-0-0之kafka概述/
- 版权声明: 本博客所有文章除特别声明外均为原创,采用 CC BY 4.0 CN协议 许可协议。转载请注明出处:https://www.xubatian.cn/
 故人的博客
故人的博客
 IT周的博客
IT周的博客
 大胖胖的笔记
大胖胖的笔记
 常瑞的部落落
常瑞的部落落
 Fortune博客
Fortune博客
 星空下的YZY
星空下的YZY
 BOBL技术博客
BOBL技术博客