

Kafka概述
kafka定义
Kafka是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于大数据实时处理领域。
队列先进先出
消息队列
传统消息队列的应用场景
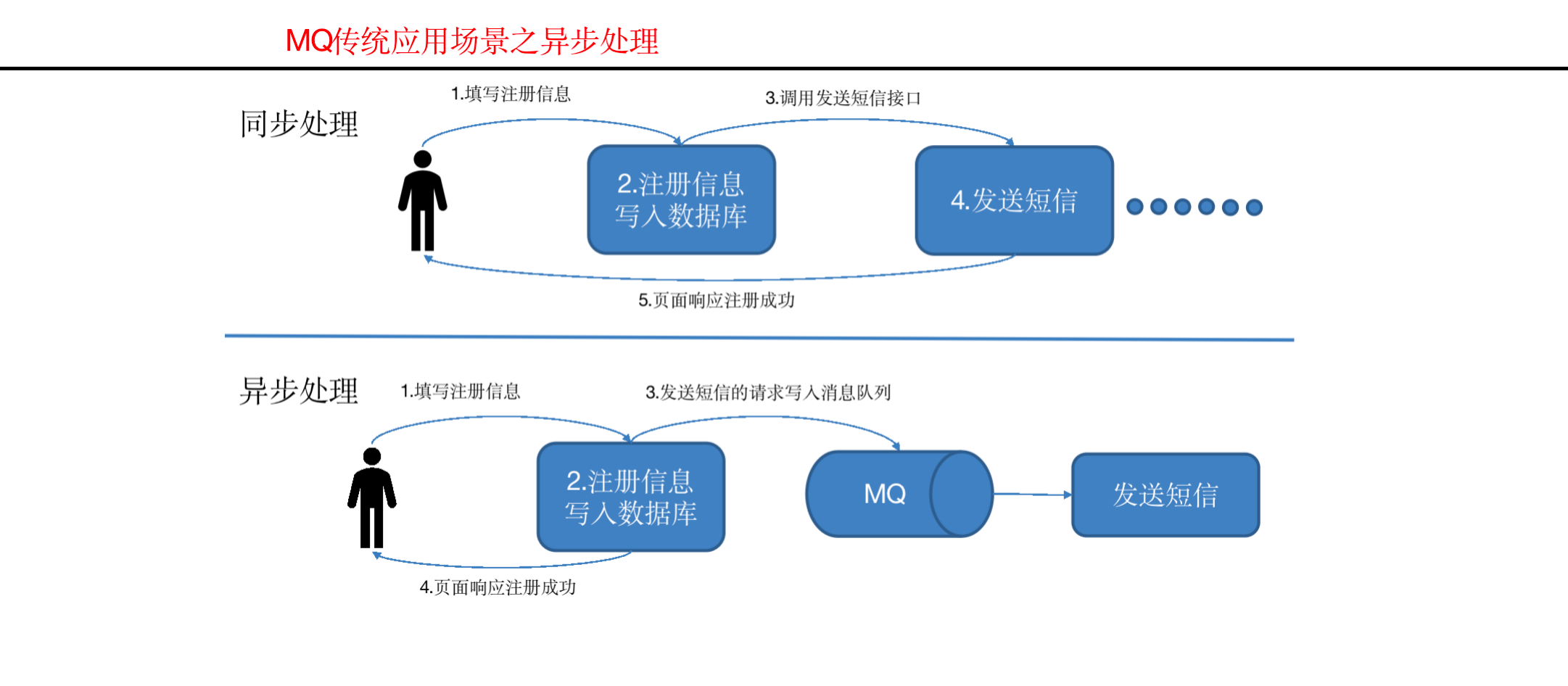
使用消息队列的好处
1 | 1)解耦 |
消息队列的两种模式 (不是kafka的模式, kafka是发布订阅模式)
1)点对点模式(一对一,只在两个系统之间,不会给到其他系统,消费者主动拉取数据,消息收到后消息清除)
消息生产者生产消息发送到Queue中,然后消息消费者从Queue中取出并且消费消息。
消息被消费以后,queue中不再有存储,所以消息消费者不可能消费到已经被消费的消息。Queue支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
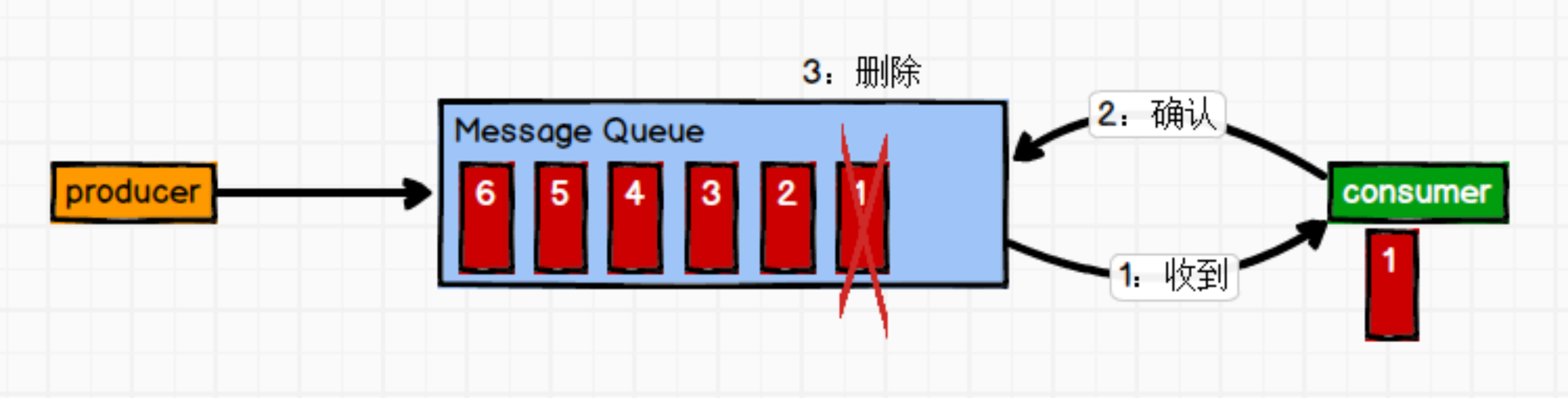
(2)发布/订阅模式(一对多,消费者消费数据之后不会清除消息)
Kafka是发布/订阅模式的基于消费者主动拉取得模式
消息生产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到topic的消息会被所有订阅者消费。
A系统和B系统之间加一个消息中间件 , 中间件只管暂存一下,不负责处理. 消息队列,先进先出的原则. B系统10M/s的速度读取数据. 如果我A系统生产速度是10M/s, B系统消费跟不上, 那么我们就得升级 ,加机器.
Kafka基础架构
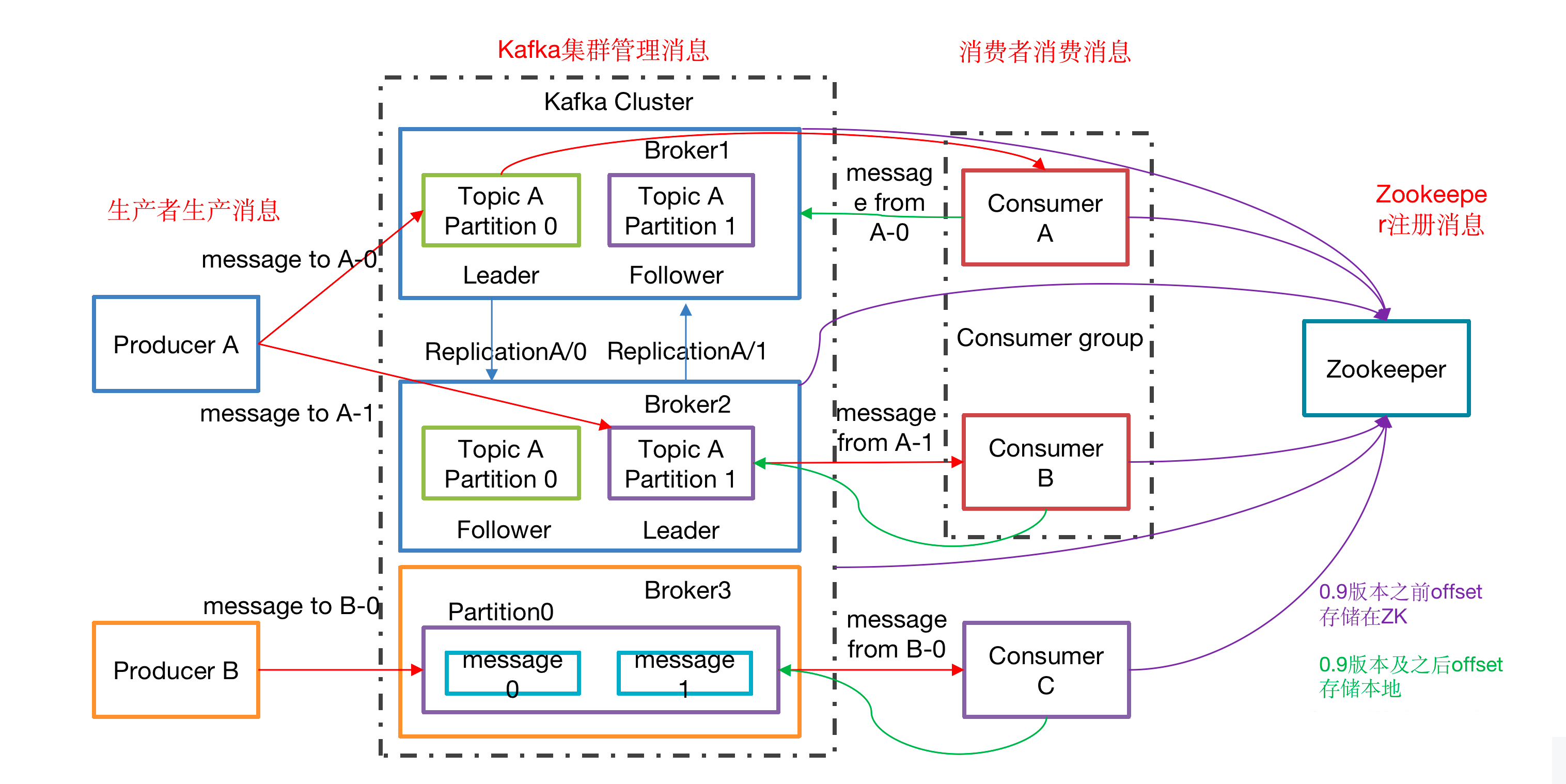
同一个消费者组里面的消费者不能同时消费同一个分区的数据
1 | 1)Producer :消息生产者,就是向kafka broker发消息的客户端; |
虚拟机上的命令
//查看kafka的消费记录offset需要使用命令:
kafka-consumer-offset-checker.sh –zookeeper hadoop101,hadoop102,hadoop103 –topic sensor –group flink-consumer_group
offset是什么?
对于每一个topic, Kafka集群都会维持一个分区日志
每个分区都是有序且顺序不可变的记录集,并且不断地追加到结构化的log文件。分区中的每一个记录都会分配一个id号来表示顺序,我们称之为offset,offset用来唯一的标识分区中每一条记录。
offset有什么用?
消费者在消费数据时,发生宕机后,再次重新启动后,消费的数据需要从宕机位置开始读取
如果从头读取,有一部分消息一定出现了重复消费
如果从宕机时的消费位置读取,就不会出现重复消费
因此kafka设计了offset可以用于处理这种情况
如何维护offset的数值?
有两种方式,
自动提交,设置enable.auto.commit=true,更新的频率根据参数【auto.commit.interval.ms】来定。这种方式也被称为【at most once】,fetch到消息后就可以更新offset,无论是否消费成功。默认就是true
手动提交,设置enable.auto.commit=false,这种方式称为【at least once】。fetch到消息后,等消费完成再调用方法【consumer.commitSync()】,手动更新offset;如果消费失败,则offset也不会更新,此条消息会被重复消费一次
offset实体在什么位置?
0.9.0版本以前.这些数值维护在zookeeper中,但是zk不适合大量写入.后来做了改动
0.9.0 版本以后,数据维护在kafka的_consumer_offsets主题下.
内部结构包括groupid:topicName_partition offset


- 本文作者: xubatian
- 本文链接: http://xubatian.cn/kafka概述/
- 版权声明: 本博客所有文章除特别声明外均为原创,采用 CC BY 4.0 CN协议 许可协议。转载请注明出处:https://www.xubatian.cn/
 故人的博客
故人的博客
 IT周的博客
IT周的博客
 大胖胖的笔记
大胖胖的笔记
 常瑞的部落落
常瑞的部落落
 Fortune博客
Fortune博客
 星空下的YZY
星空下的YZY
 BOBL技术博客
BOBL技术博客