

感动源于真实,而真实不是坐而论道就能做到的,不是闭门造车就能实现的,不是靠天马行空的幻想就能再现的。——人民日报

前言
我们知道大数据面临的痛点就是:
①数据存储问题.数据超级大,可达TB级别.所以没有任何合适的工具存储这些数据.mysql等数据也无法有效的存储.
②数据在有效的时间整合出结果,即计算问题.就算能够存储下来,也无法有效的操作这些数据. 即,无法通过类似sql语句查询mysql一样去整合数据得到有效的信息.
但是我们又说到, hadoop解决了这两个问题.
首先hadoop解决数据存储问题的模块就是HDFS. 也就是说HDFS就是针对大数据存储问题的一套落地的解决方案.
那么数据存储了,我需要分析呀.如何取分析呢?使用什么引擎去分析呢?
答案就是: MapReduce. 一个模块负责存储, 一个模块负责分析.
MapReduce概述
MapReduce定义
MapReduce是一个分布式运算架,是用户开发“基于Hadoop的数据分析应用”的核心框架。
MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。
MapReduce优缺点
优点

1 | 什么叫离线处理? |
缺点
其实也不能叫缺点,以为他本身设计的时候就没有去考虑这些东西,如果考虑这些东西就可能解决不了大量数据的处理了

静态的就表示,数据已经放好了在这里了,而不是你时不时还往里面添加数据,这是不支持的
就是如下图,什么叫有向图(DAG)计算?就是后面应用程序输入的数据是前面数据输出的数据,而mapReduce不擅长做这个,但是也不是不能做. 如果这么做的话会有大量的磁盘io操作. 就是你前面的MapReduce程序完成后结果放在磁盘中,下一个MapReduce程序读取磁盘的结果来操作. 这个过程会发生大量的磁盘io.所以你这个性能是非常低下的
MapReduce核心思想
之前map 和 reduce 一个负责分,一个负责合,这是一个很笼统的认识
现在MapReduce核心编程思想,如图所示:
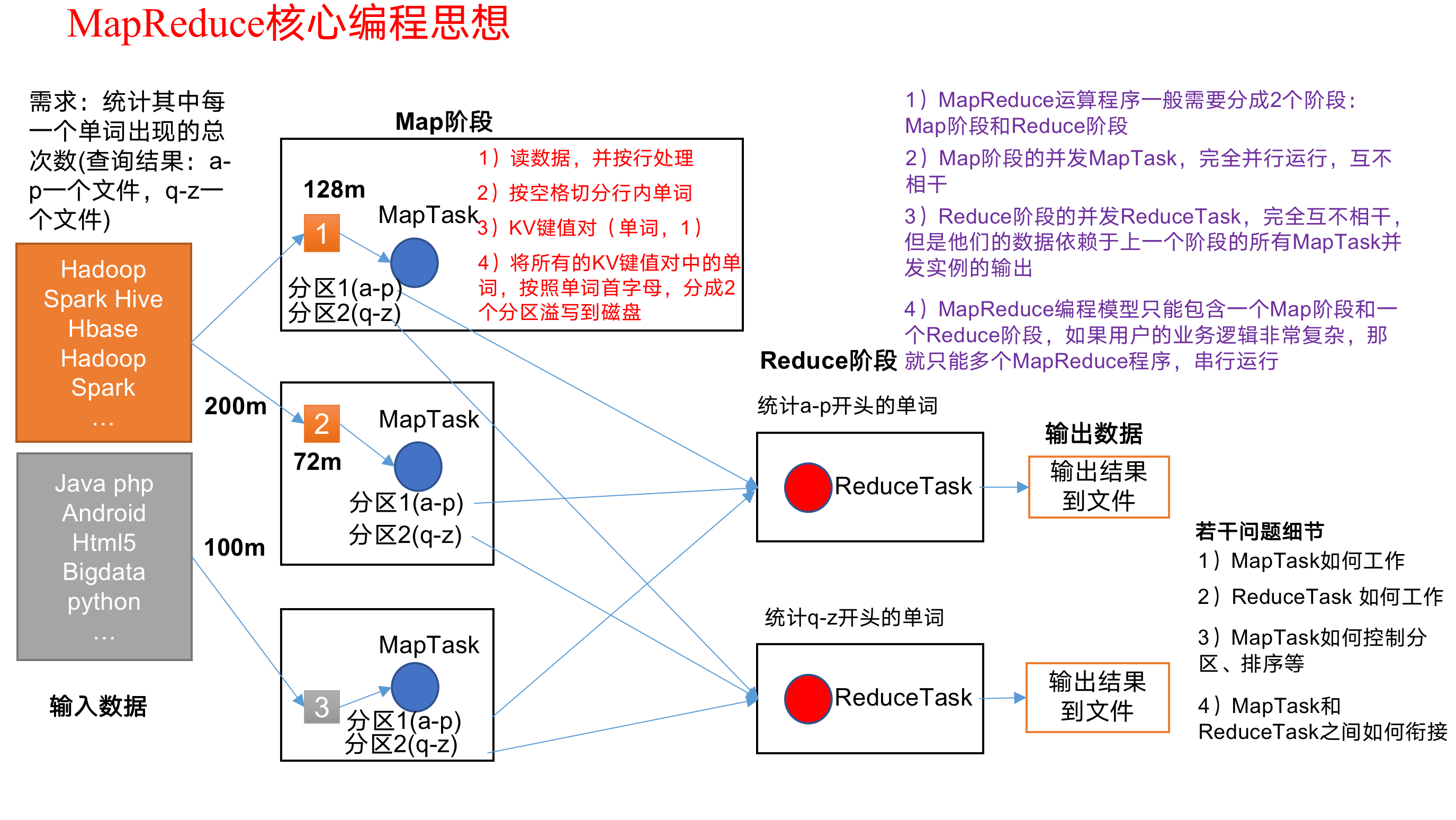
对上图MapReduce核心思想解释
第一个文件200m 我们立马想到,我们存到hdfs中后立马存两块(128M一块). 这里有两个文件,所以有三块数据.在map阶段会读取你的每一块内容,每一块内容都会交给maptask来处理.这个maptask就是map阶段最核心的一个对象. 整个maptask的过程中就是你的map阶段.所有的工作都是围绕着maptask来进行工作的.maptask就是一个任务.是map阶段的一个任务.正常情况下你的每一块数据都会交给maptask来进行处理.在我的maptask里面做什么操作呢?我要把你文件中的每一行数据都给他读出来.
1)读数据,并按行处理 (就是我读一行进来)
2)按空格切分行内单词 (具体要不要按照行处理看你每个单词与单词之间是否已空格划分)
3)K键值对(单词,1) (hadoop,1)(hive,1)(spark,1)
4)将所有的KV键值对中的词,按照单词首字母,分成2个分区溢写到磁盘 (为什么要分成两个分区呢?因为我最终的结果我要的是两个,那我就是将a-z,q-p开头的单词写到不同的文件中)
最终我的三个maptask中一共六个文件,即分区1(z-p),分区2(q-z)各两个.
把三个maptask里面分区1的给一个reduce中,分区2的给一个reduce中.
所以在这种情况下他就有两个reducetask,为什么有两个呢? 其实就是由你这个分区来决定的.因为你最终有两个文件,所以我就开启两个reduceTask来处理. 这reduceTask到每一个mapTask生成的文件里面去拷贝数据,比如说分区1里面拷贝到处理a-p的ReduceTask, 分区2拷贝到处理q-z的ReduceTask中.
Mapreduce程序只能包含一个map阶段和一个reduce阶段.你不能有多个.如果说你的一个MapReduce程序处理完成后还没有得到你想要的结果,那你只能再重新再开一个MapReduce程序接着去处理你这个数据.不能再一个MapReduce中写多个map阶段或者多个reduce阶段程序.
问题:
为什么一个mapTask要处理一块数据?
我的kv对处理完成以后如何写到多个分区里面呢?
我的reduce阶段如何去拷贝我的多个分区的数据?
mapreduce核心思想总结
1)分布式的运算程序往往需要分成至少2个阶段。
2)第一个阶段的MapTask并发实例,完全并行运行,互不相干。
3)第二个阶段的ReduceTask并发实例互不相干,但是他们的数据依赖于上一个阶段的所有MapTask并发实例的输出。
4)MapReduce编程模型只能包含一个Map阶段和一个Reduce阶段,如果用户的业务逻辑非常复杂,那就只能多个MapReduce程序,串行运行。
总结:分析WordCount数据流走向深入理解MapReduce核心思想。
MapReduce进程
一个完整的MapReduce程序在分布式运行时有三类实例进程:
1)MrAppMaster:负责整个程序的过程调度及状态协调。
2)MapTask: 负责Map阶段的整个数据处理流程。
3)ReduceTask: 负责Reduce阶段的整个数据处理流程。
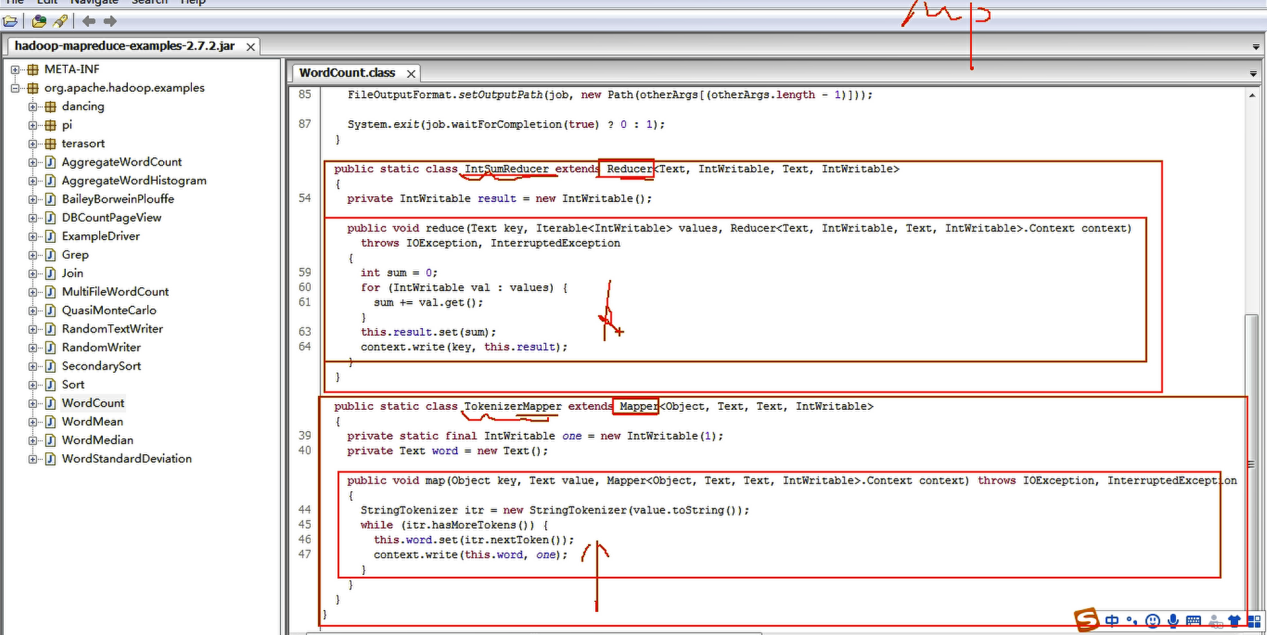
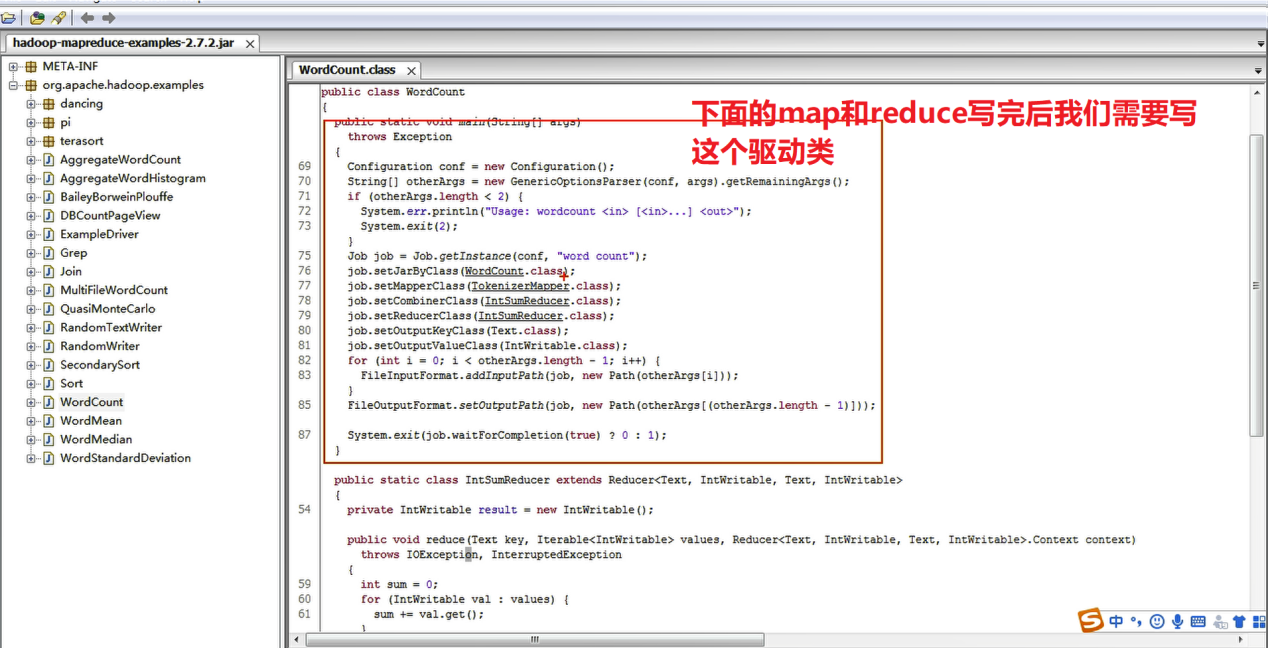
通过官方WordCount源码查看我们如何取去写MapReduce程序
采用反编译工具反编译源码,发现WordCount案例有Map类、Reduce类和驱动类。且数据的类型是Hadoop自身封装的序列化类型。
Hadoop常用数据序列化类型
在mapreduce中用的数据类型都是hadoop重新提供出来的一套数据类型,他没有直接使用java中提供好的8个基本数据类型,因为他认为java定义好的在序列化和反序列化操作时的数据量比较大,所以他自己搞了一套数据类型和一套序列化,实际上特别好记,就是在原java后面加了writable,除了字符串
常用的数据类型对应的Hadoop数据序列化类型
| Java类型 | Hadoop Writable类型 |
|---|---|
| Boolean | BooleanWritable |
| Byte | ByteWritable |
| Int | IntWritable |
| Float | FloatWritable |
| Long | LongWritable |
| Double | DoubleWritable |
| String | Text |
| Map | MapWritable |
| Array | ArrayWritable |


- 本文作者: xubatian
- 本文链接: http://xubatian.cn/hadoop组成模块之MapReduce概述/
- 版权声明: 本博客所有文章除特别声明外均为原创,采用 CC BY 4.0 CN协议 许可协议。转载请注明出处:https://www.xubatian.cn/
 故人的博客
故人的博客
 IT周的博客
IT周的博客
 大胖胖的笔记
大胖胖的笔记
 常瑞的部落落
常瑞的部落落
 Fortune博客
Fortune博客
 星空下的YZY
星空下的YZY
 BOBL技术博客
BOBL技术博客