

在濒临绝境中突出重围,在困顿逆境中毅然奋起,经受一切风险考验,攻克一个又一个看似不可攻克的难关。——人民日报

前言
上文了解到了hadoop由四个模块组成: HDFS,MapReduce,Yarn,Common.
本篇文章具体了解hadoop的HDFS模块.
什么是HDFS?
HDFS有什么功能?
如何掌握HDFS?
HDFS概述
是什么原因使得HDFS产生的呢?
我们知道大数据面临的痛点就是:
① 数据存储问题. 数据超级大,可达TB级别.所以没有任何合适的工具存储这些数据.mysql等数据也无法有效的存储.
② 数据在有效的时间整合出结果,即计算问题.就算能够存储下来,也无法有效的操作这些数据. 即,无法通过类似sql语句查询mysql一样去整合数据得到有效的信息.
但是我们又说到, hadoop解决了这两个问题.
首先hadoop解决数据存储问题的模块就是HDFS. 也就是说HDFS就是针对大数据存储问题的一套落地的解决方案.
那么为什么连mysql这样的数据库都无法解决的问题,hadoop的HDFS能够解决呢?
答案就是: 分布式文件存储. 可以理解为, 将十台服务器的磁盘整合成一个磁盘,如果每台服务器是10T,那么,整个HDFS就是100T. 如果后期磁盘不够了,我还可以增加服务器的方式继续扩容.
HDFS产生背景
随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。HDFS只是分布式文件管理系统中的一种。它主要解决什么问题呢?它主要解决的是,当我的是数据量大到一定程度的时候,我把我的数据分布到多台机器上去存储,但是我可以多多台机器上的数据进行统一的管理.
HDFS定义
HDFS( Hadoop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位文件;
其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色. 因为有很多服务器联合起来是一个HDFS.
每台服务器上都有HDFS.如何区分谁是主,谁是从呢? 因为有了主从才能更好的管理. 就像董事长管着经理,经理管着员工,这样才能掌控整个大的集团. 毕竟一个角色的人是有限的. 此逻辑在这里也适用.
HDFS的使用场景
适合一次写入,多次读出的场景,且不支持文件的修改,也不支持删除,只支持末尾追加。适合用来做数据分析,并不适合用来做网盘应用.
Namenode所有元数据信息都是维护在内存中的
HDFS优缺点
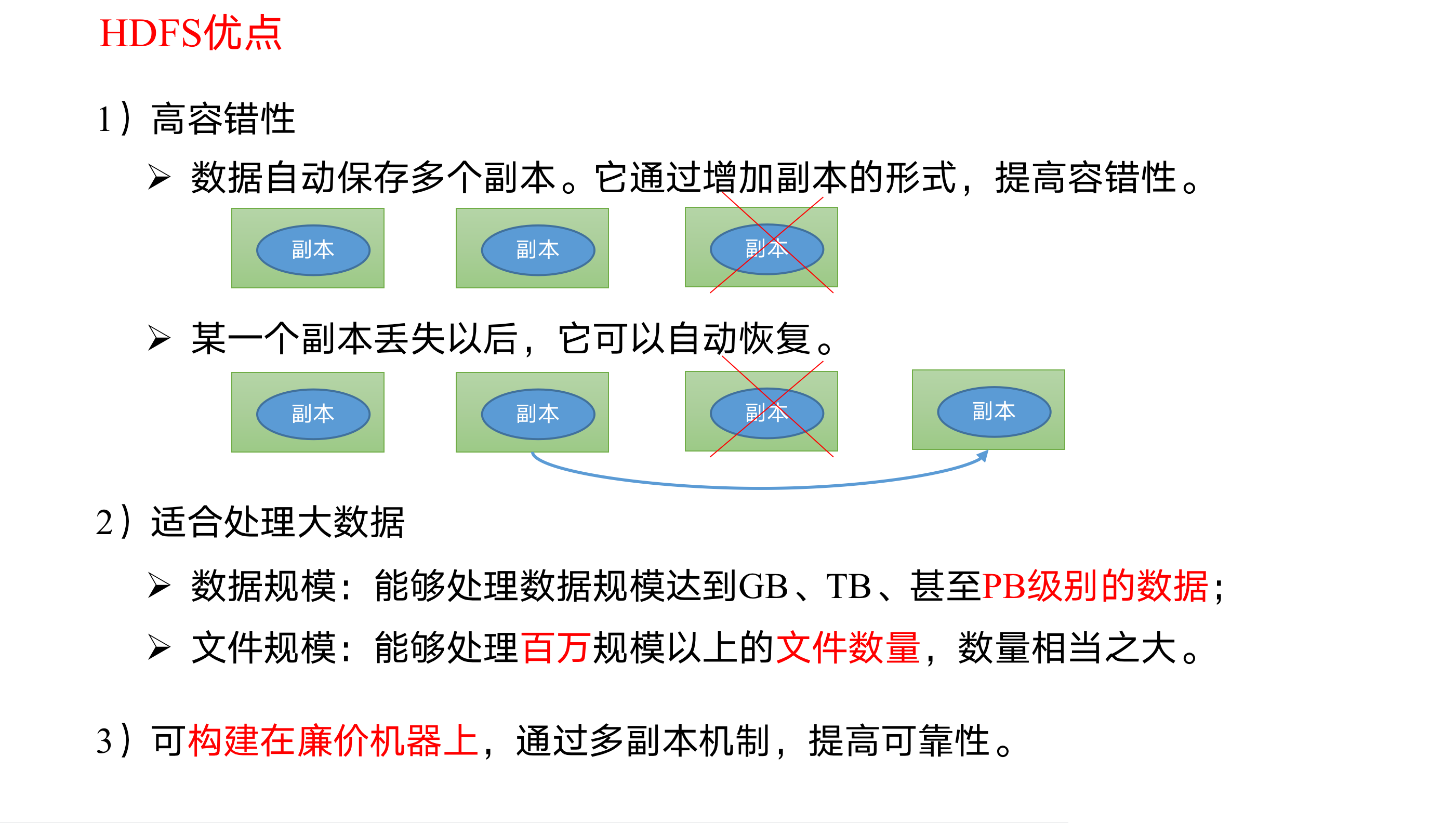

1 | 要知道,namenode给datanode下达指令,但是NameNode具体给datanode下达什么指令是由我们客户端来操作NameNode来决定的;注意在HDFS当中他的文件单位是以块(Block)为单位的存储的. |
HDFS组成架构
上面说了HDFS是有很多服务器联合起来的. 但是需要工作你得有一个领导人.你得分清楚哪一个是领导. 将来数据来了之后我需要存在哪台机器上得由一个小领导来指挥.要知道,namenode给datanode下达指令,但是NameNode具体给datanode下达什么指令是由我们客户端来操作NameNode来决定的;注意在HDFS当中他的文件单位是以块(Block)为单位的
Namenode具体要给datanode下达什么指令,都是我们客户端来操作的.
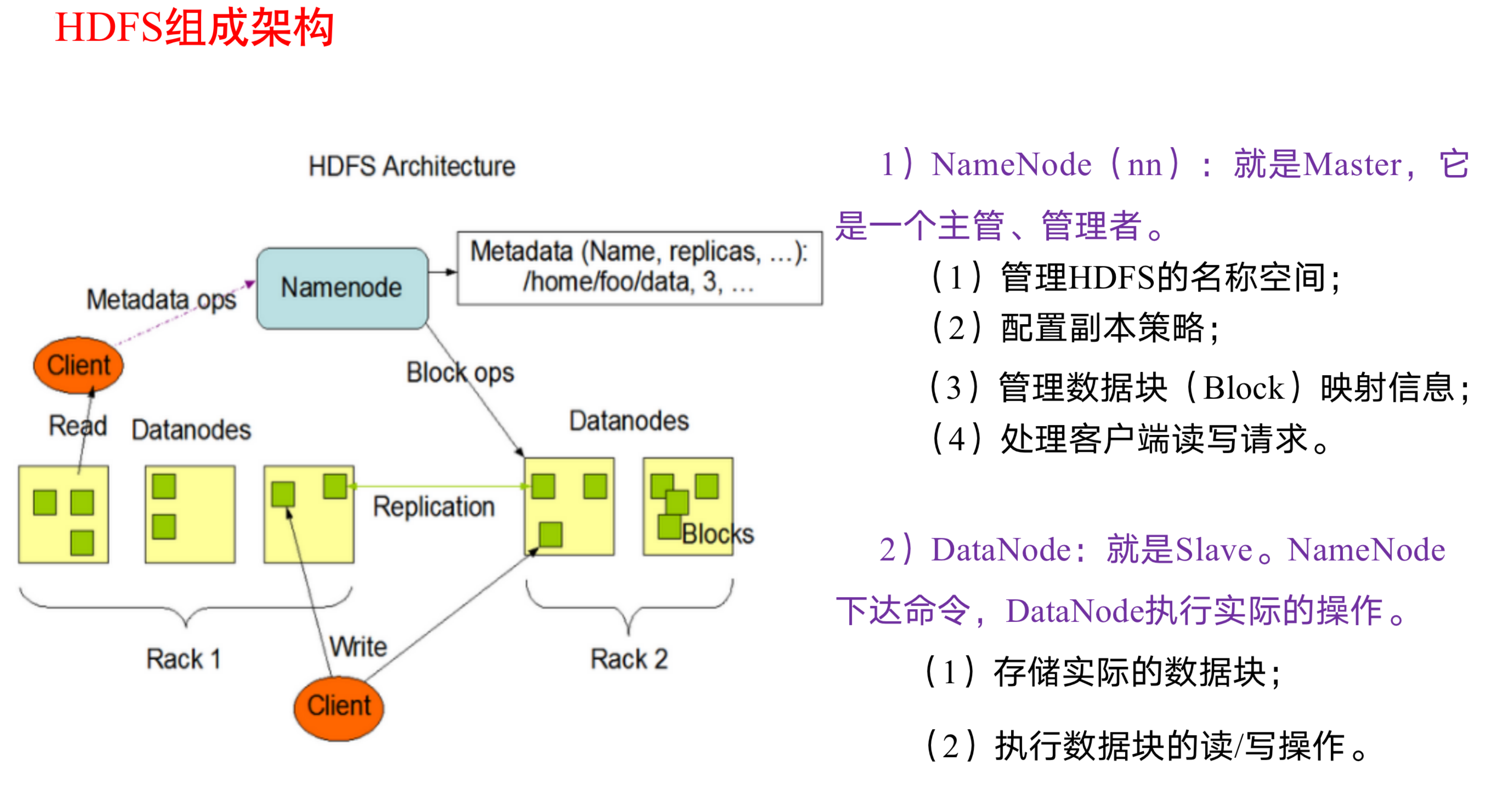
Client: 就是客户端
1 | (1)文件切分。文件上传HDFS的时候,Client将文件切分成个个的Bock,然后进行上传; |
SecondaryNameNode: 并非 NameNode的热备。当 NameNode挂掉的时候,它并不能马上替换 NameNode并提供服务
1 | (1)辅助 NameNode,分担其工作量,比如定期合并 Fsimage和Edits,并推送给 NameNode; |
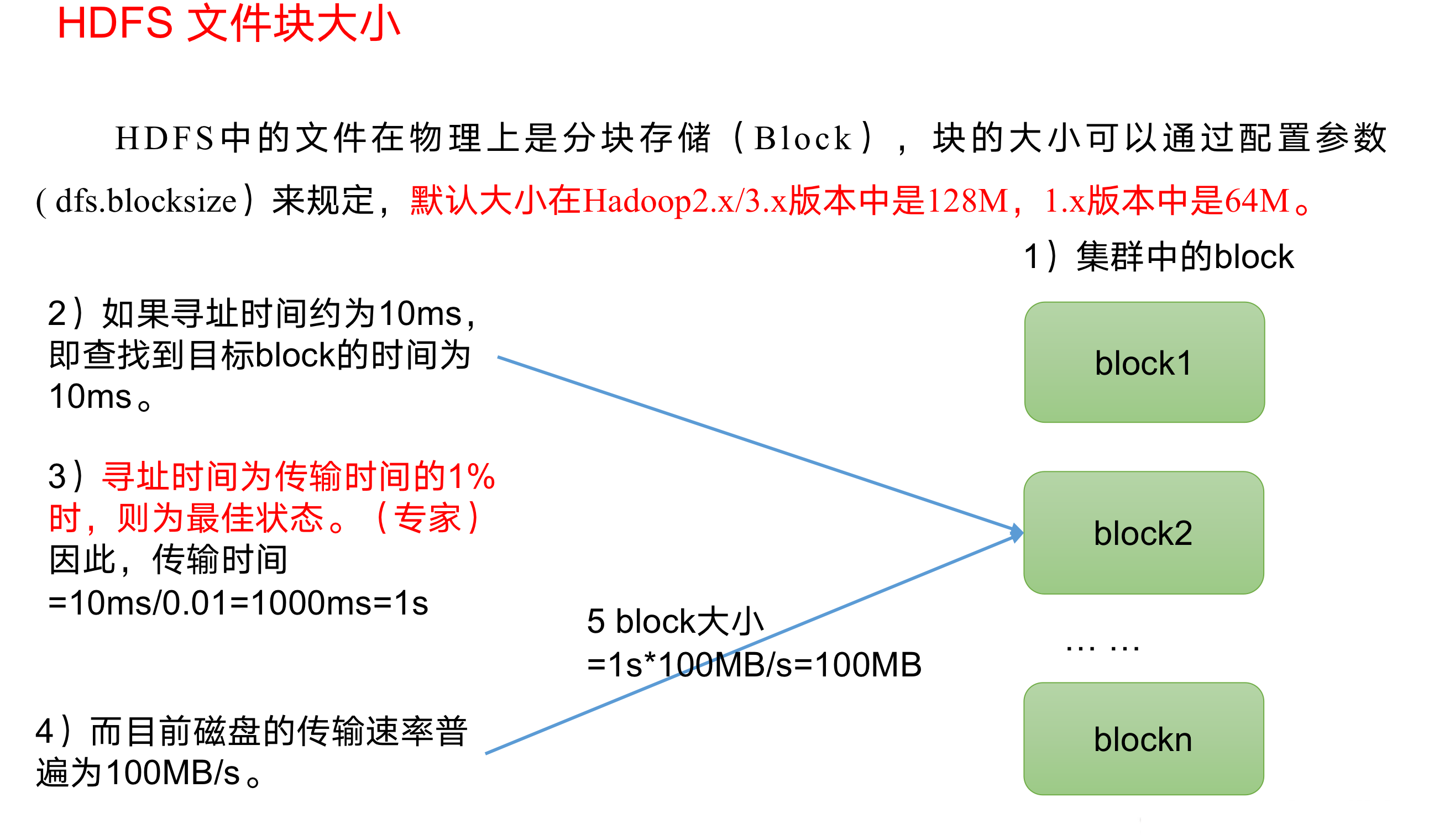
HDFS文件块大小
注意在HDFS当中他的文件单位是以块(Block)为单位的
所以 这个这个文件分成几块存到HDFS,一般一块是128M. 如果你的文件是300M,那么他会分成128M+128M+44M. 这三块.
这三块存到hadoop的HDFS上,可能存在了不同的服务器上.

HDFS的Shell操作
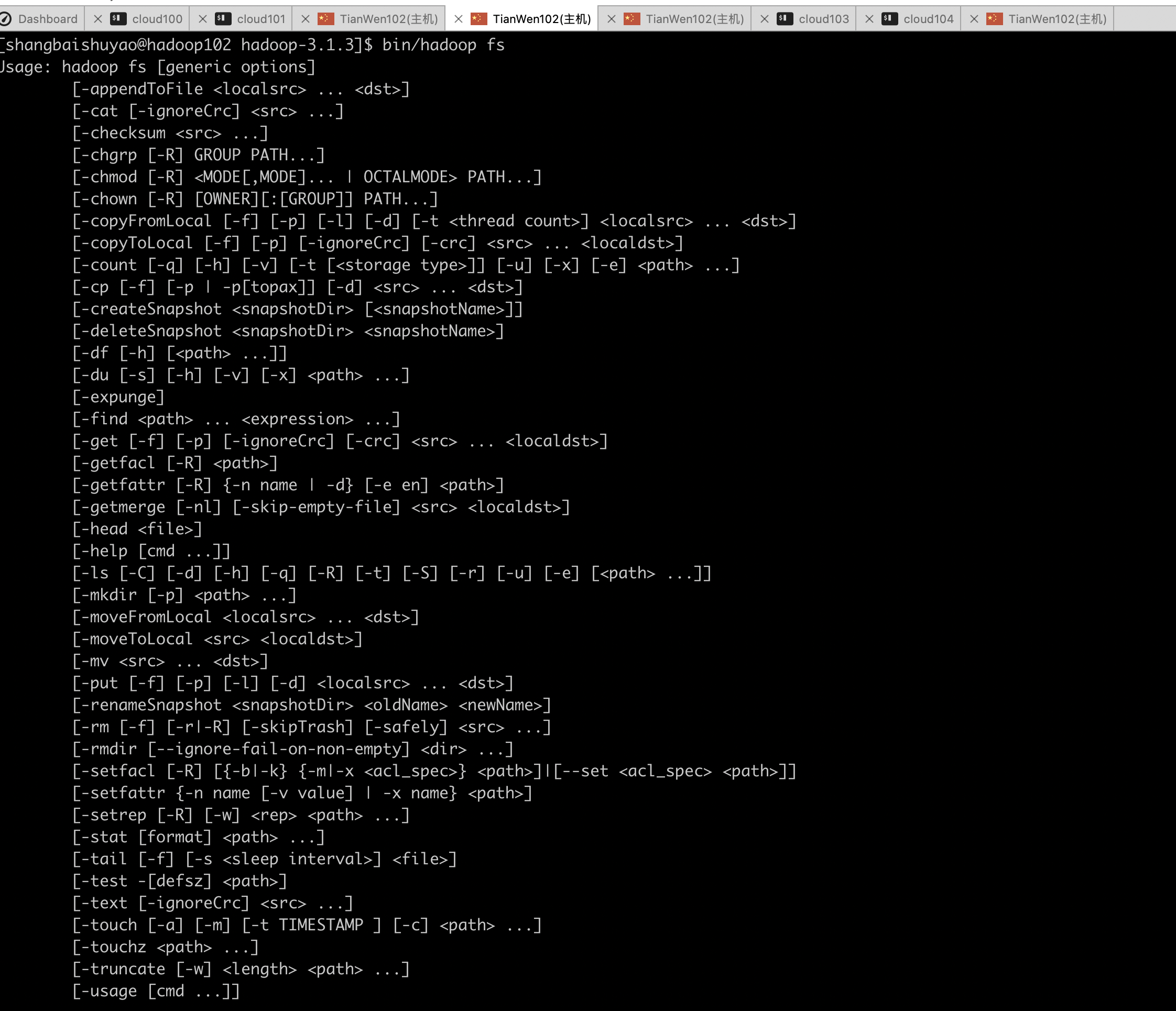
Hadoop命令查看
1 | [shangbaishuyao@hadoop102 hadoop-3.1.3]$ bin/hadoop fs |
图示:
Hadoop常用命令实操
启动类命令
| 功能说明 | 命令脚本 |
|---|---|
| 启动hdfs集群 | sbin/start-dfs.sh |
| 启动yarn | sbin/start-yarn.sh |
hadoop fs/hdfs dfs 命令
| 功能说明 | 命令 |
|---|---|
| 创建目录 | hdfs dfs -mkdir -p /data/flink |
| 显示目录 | hdfs dfs -ls / |
| 从HDFS拷贝到本地 | hdfs dfs -copyToLocal /data/data.txt ./ |
| 文件上传到集群(从本地) | hhdfs dfs -copyFromLocal data.txt / |
| 文件下载 | hdfs dfs -get /data/flink |
| 删除集群的文件 | hdfs dfs -rm /data/flink |
| 删除文件夹 | hdfs dfs -rm -r -skipTrash /data |
| 从本地剪切粘贴到HDFS | hdfs dfs -moveFromLocal data.txt /data/ |
| 追加一个文件到已经存在的文件末尾hdfs dfs -appendToFile data1.txt /data/data.txt | |
| 显示文件内容 | hdfs dfs -cat data.txt |
| 修改文件所属权限 | hdfs dfs -chmod 777 xxx.sh |
| 修改文件所属用户组 | hdfs dfs -chown root:root data.txt |
| 从HDFS的一个路径拷贝到HDFS的另一个路径 | hdfs dfs -cp data.txt /data1.txt |
| 在HDFS目录中移动文件 | hdfs dfs -mv data.txt /opt/ |
| 合并下载多个文件 | hdfs dfs -getmerge /data/* ./data_merge.txt |
| hadoop fs -put | 等同于copyFromLocal |
| 显示一个文件的末尾 | hdfs dfs -tail data.txt |
| 删除文件或文件夹 | hdfs dfs -rm /data/data.txt |
| 删除空目录 | hdfs dfs -rmdir /data |
| 统计文件夹的大小信息 | hdfs dfs -s -h /data |
| 统计文件夹下的文件大小信息 | hdfs dfs -h /data |
| 设置HDFS中文件的副本数量 | hdfs dfs -setrep 3 /data/data.txt |
yarn命令
| 功能说明 | 命令 |
|---|---|
| 查看正在运行的yarn任务列表 | yarn application -list appID |
| kill掉指定id的yarn任务 | yarn application -kill appID |
| 查看任务日志信息 | yarn logs -applicationId appID |
HDFS的API操作
1 | package com.alibaba.hdfs; |
HDFS的读写流程
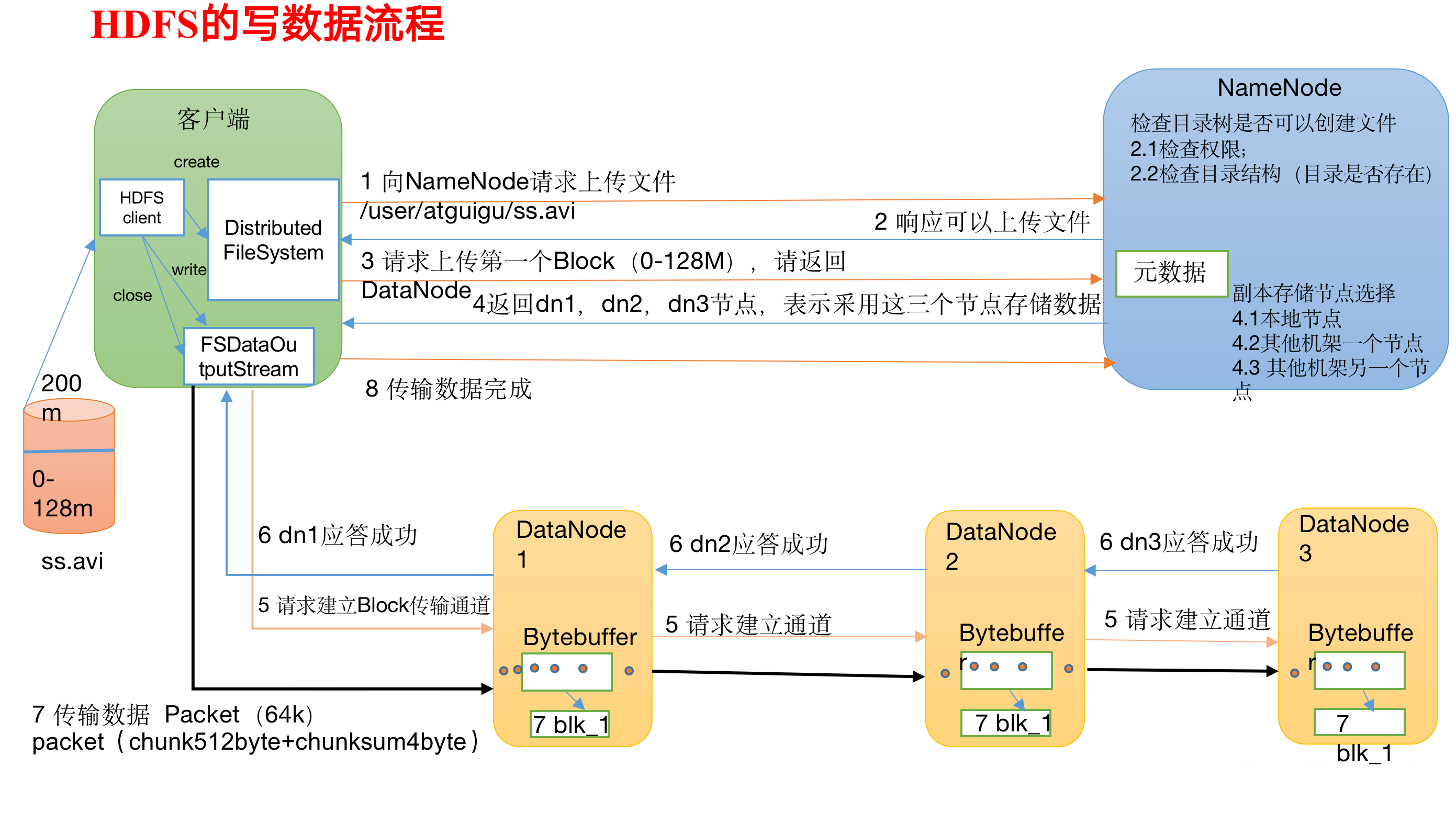
HDFS写数据流程(剖析文件写入)
Bytebuffer 缓存
1)客户端通过Distributed FileSystem(分布式文件系统)模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
2)NameNode返回是否可以上传。
3)客户端请求第一个 Block(块)上传到哪几个DataNode服务器上。
4)NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
5)客户端通过FSDataOutputStream(拿到输出流)模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。(FSDataOutputStream,这个类重载了很多write方法,用于写入很多类型的数据:比如字节数组,long,int,char等等。)
6)dn1、dn2、dn3逐级应答客户端。
7)客户端开始往dn1上传第一个Block(128M)(先从磁盘读取数据放到一个本地内存缓存),他不可能一次性传128M,他是以Packet(数据包)为单位的形式传,(丢包就是这种形式,有部分数据没收到),dn1收到一个Packet就会先放进他的缓存里面然后落盘,存到内存的目的是因为他还要传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答,假如我成功收到了,我放在队列当中的东西会被响应的。
8)当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)。
HDFS读数据流程
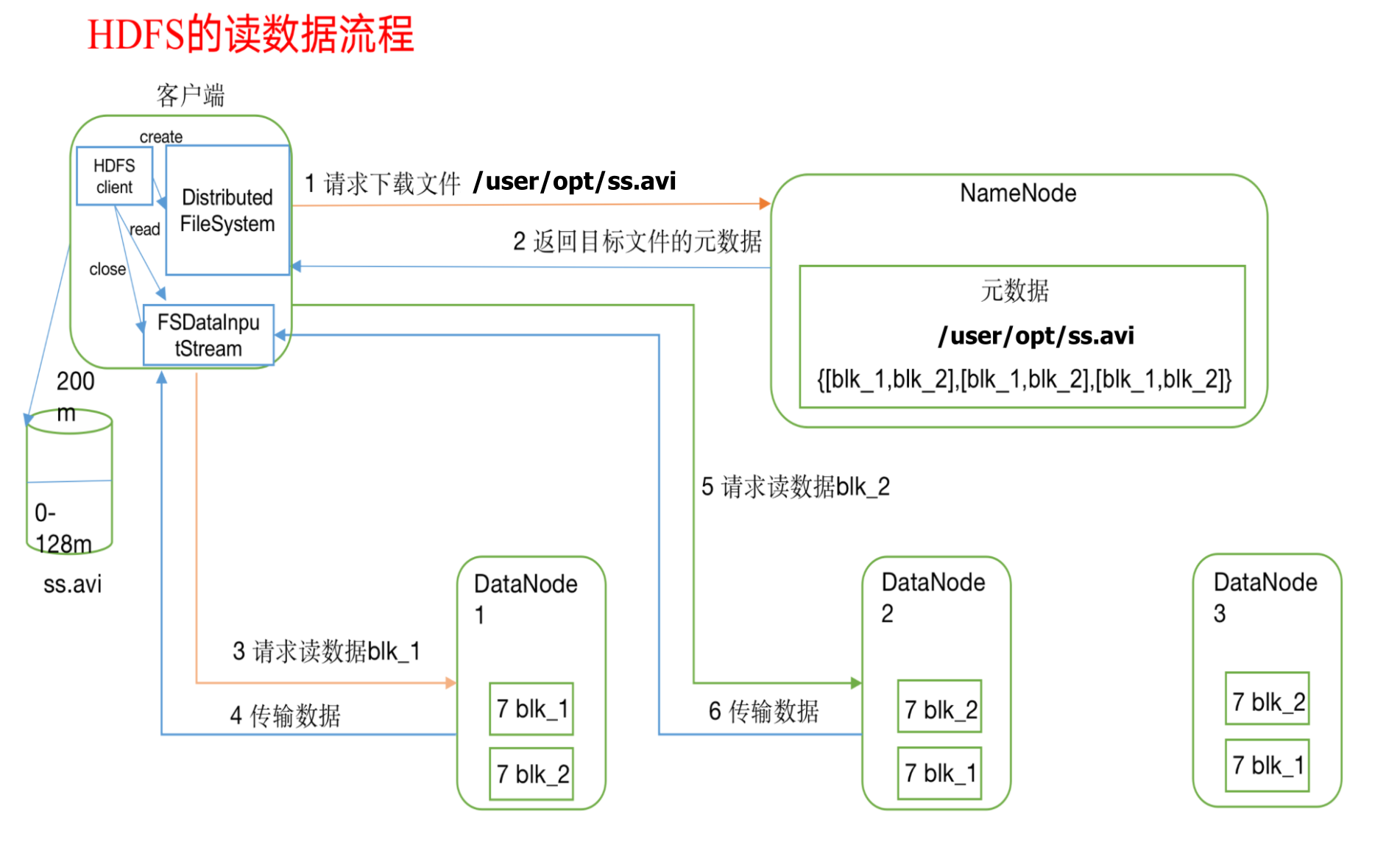
1)客户端通过Distributed FileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
2)挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
3)DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet(数据包)为单位来做校验)。
4)客户端以Packet(数据包)为单位接收,先在本地缓存,然后写入目标文件。
NameNode和SecondaryNameNode
对于现在hadoop升级到3.x之后,其实现在namenode已经不太是重点了. 在早期的版本当中很重要,因为在早期的版本中namenode存在一个单点故障. 早期的版本中没有很好的解决方案,只能有secondarynamenode来进行恢复大部分的数据.
但是对于现在来说并不是特别重要了. 因为我们有了一个高可用.即hadoopHA.他解决了namenode的一个单点故障的问题. 实际上我们有了高可用之后我们的secondarynamenode我们已经不需要再用他了.
NameNode和SecondaryNameNode工作机制
思考:NameNode中的元数据是存储在哪里的?
首先,我们做个假设,如果存储在NameNode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低。因此,元数据需要存放在内存中。但如果只存在内存中,一旦断电,元数据丢失,整个集群就无法工作了。因此产生在磁盘中备份元数据的FsImage(镜像文件)。
这样又会带来新的问题,当在内存中的元数据更新时,如果同时更新FsImage,就会导致效率过低,但如果不更新,就会发生一致性问题,一旦NameNode节点断电,就会产生数据丢失。因此,引入Edits(修改记录)文件(只进行追加操作,效率很高)。每当元数据有更新或者添加元数据时,修改内存中的元数据并追加到Edits中。这样,一旦NameNode节点断电,可以通过FsImage和Edits的合并,合成元数据。
但是,如果长时间添加数据到Edits中,会导致该文件数据过大,效率降低,而且一旦断电,恢复元数据需要的时间过长。因此,需要定期进行FsImage和Edits的合并,如果这个操作由NameNode节点完成,又会效率过低。因此,引入一个新的节点SecondaryNamenode,专门用于FsImage和Edits的合并。
NameNode和SecondaryNameNode工作机制图示:
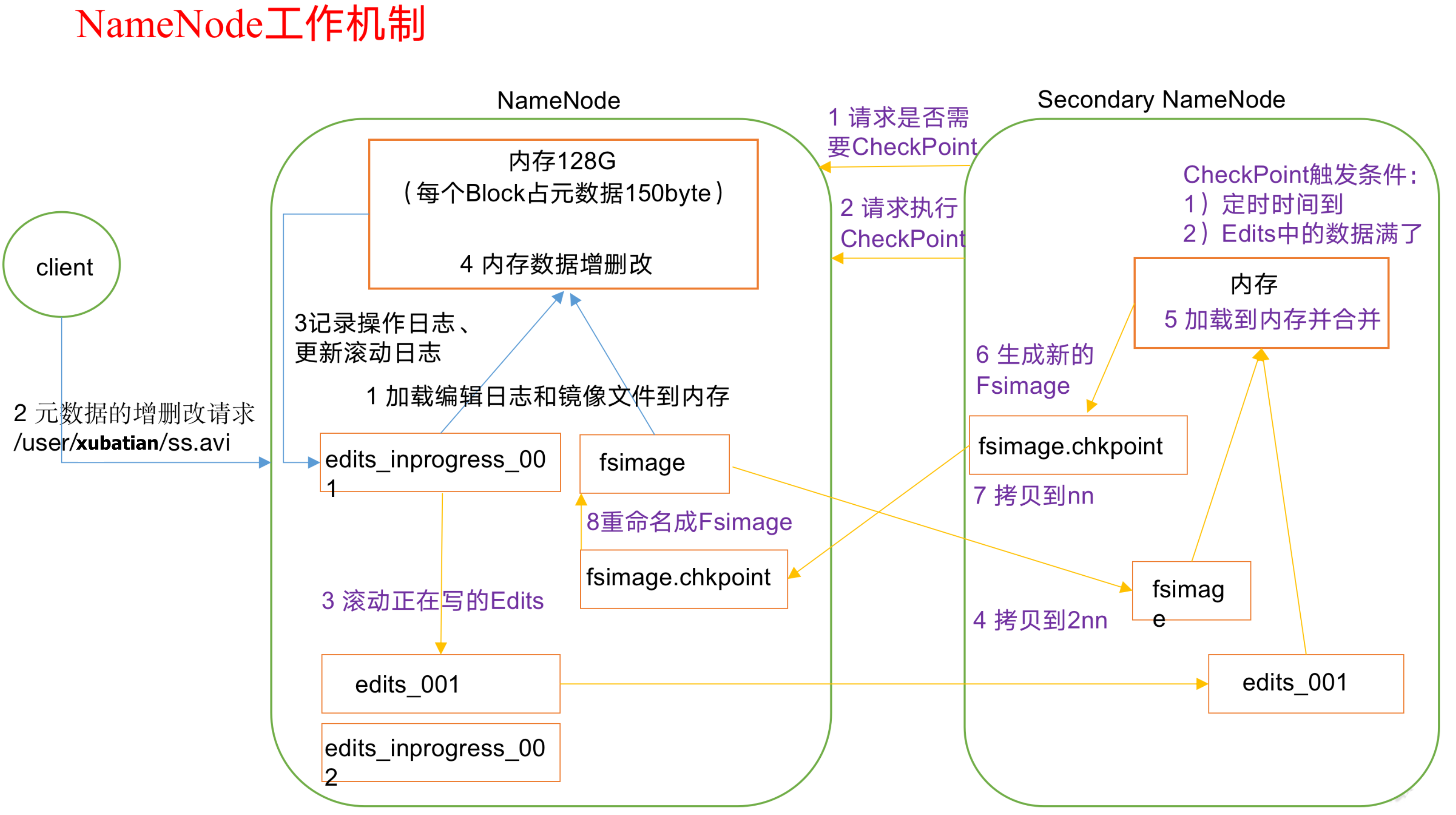
第一阶段:NameNode启动
(1)第一次启动NameNode格式化后,创建Fsimage和Edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求。
(3)NameNode记录操作日志,更新滚动日志。
(4)NameNode在内存中对元数据进行增删改。第二阶段:Secondary NameNode工作
(1)Secondary NameNode询问NameNode是否需要CheckPoint。直接带回NameNode是否检查结果。
(2)Secondary NameNode请求执行CheckPoint。
(3)NameNode滚动正在写的Edits日志。
(4)将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
(5)Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件fsimage.chkpoint。
(7)拷贝fsimage.chkpoint到NameNode。
(8)NameNode将fsimage.chkpoint重新命名成fsimage。NN和2NN工作机制详解:
1 | Fsimage:NameNode内存中元数据序列化后形成的文件。 |
总结NameNode和secondNameNode关系?
secondNameNode不是NameNode的热备. 因为他不能替换NameNode去干活. secondNameNode只是辅助namenode去工作. 比如说合并编辑日志. 所以说,当我的NameNode挂掉之后, 我的secondNameNode只是保证我的数据不丢失,不能保证我的机器能正常干活.
那我的高可用如何去解决这个问题呢? 那就是弄两个NameNode.
但是两个NameNode不能同时进行工作.
所以我们一个是作为active活跃状态. 一个作为standby时刻准备着.
我们的active活跃状态的NameNode是正在对外提供服务的. 那就意味这将来客户端的读写请求操作都要经过active活跃状态的NameNode.
如果说我们一个写请求,正在操作活跃状态的NameNode, 但是突然挂掉了.另一台standby状态的NameNode如何和active状态的保持一致呢?
即 ,如何实现active状态的NameNode和standby状态的NameNode数据同步问题?
这个时候光靠两台NameNode,即一台active状态,一台standby状态. 已经不行了. 这时候就有一个叫journalNode来了. 它实际上也是一个进程. 他和NameNode,DataNode,secondNameNode一样的, 也是一个进程. 他就是用来完成一台active状态的NameNode和一台standby状态的NameNode,这来两台数据同步性的中间进程. 将来我客户端操作active(活跃)状态的NameNode时候, 不仅在内存中修改. 还会写自己的编辑日志, 并且要往journalNode中去写一份. 注意.active(活跃)状态的NameNode往journalnode中去写, standby状态的NameNode往journalName里面去读.这就解决数据同步性的问题.
假如说我这个active状态的NameNode性能超级强悍. 他一直都不会出现问题. 这个时候我们客户端一致对Actvie状态的NameNode做修改的操作. 那么他的编辑日志会越来越大. 当你达到一定程度, 我们是不是得合并编辑日志呢. 我们合并编辑日志是secondNameNode做的. 但是在hadoopHA高可用情况下, 有了standby状态的NameNode时候,就不需要配置secondNameNode了. 因为我们的standby状态的NameNode就可以完成合并编辑日志的功能.而且当active状态的NameNode出现故障的时候, 我们standby状态的NameNode立马能提供服务.
实际上,NameNode,secondNameNode,等都是对应的一个java类.
Fsimage和Edits解析
Fsimage和Edits概念

oiv查看Fsimage文件
(1)查看oiv和oev命令,查看镜像文件用oiv,查看编辑日志用oev
1 | [shangbaishuyao@hadoop102 current]$ hdfs |
(2)基本语法
hdfs oiv -p 文件类型 -i镜像文件 -o 转换后文件输出路径
思考:可以看出,Fsimage中没有记录块所对应DataNode,为什么?
在集群启动后,要求DataNode上报数据块信息,并间隔一段时间后再次上报。
oev查看Edits文件
1)基本语法
hdfs oev -p 文件类型 -i编辑日志 -o 转换后文件输出路径
2)案例实操
1 | [shangbaishuyao@hadoop102 current]$ hdfs oev -p XML -i edits_0000000000000000012-0000000000000000013 -o /opt/module/hadoop-2.7.2/edits.xml |
思考:NameNode如何确定下次开机启动的时候合并哪些Edits?
CheckPoint(检查点)时间设置
1)通常情况下,SecondaryNameNode每隔一小时执行一次。
[hdfs-default.xml]
1 | <property> |
2)一分钟检查一次操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次。
1 | <property> |
NameNode故障处理
NameNode故障后,可以采用如下两种方法恢复数据。
方法一:将SecondaryNameNode中数据拷贝到NameNode存储数据的目录;
kill -9 NameNode进程
删除NameNode存储的数据(/opt/module/hadoop-2.7.2/data/tmp/dfs/name)
1 | [shangbaishuyao@hadoop102 hadoop-2.7.2]$ rm -rf /opt/module/hadoop-2.7.2/data/tmp/dfs/name/* |
- 拷贝SecondaryNameNode中数据到原NameNode存储数据目录
1 | [shangbaishuyao@hadoop102 dfs]$ scp -r atguigu@hadoop104:/opt/module/hadoop-2.7.2/data/tmp/dfs/namesecondary/* ./name/ |
- 重新启动NameNode
1 | [shangbaishuyao@hadoop102 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode |
方法二:使用-importCheckpoint选项启动NameNode守护进程,从而将SecondaryNameNode中数据拷贝到NameNode目录中。
1.修改hdfs-site.xml中的
1 | <property> |
kill -9 NameNode进程
删除NameNode存储的数据(/opt/module/hadoop-2.7.2/data/tmp/dfs/name)
1
[shangbaishuyao@hadoop102 hadoop-2.7.2]$ rm -rf /opt/module/hadoop-2.7.2/data/tmp/dfs/name/*
如果SecondaryNameNode不和NameNode在一个主机节点上,需要将SecondaryNameNode存储数据的目录拷贝到NameNode存储数据的平级目录,并删除in_use.lock文件
1
2
3
4
5
6[shangbaishuyao@hadoop102 dfs]$ scp -r atguigu@hadoop104:/opt/module/hadoop-2.7.2/data/tmp/dfs/namesecondary ./
[shangbaishuyao@hadoop102 namesecondary]$ rm -rf in_use.lock
[shangbaishuyao@hadoop102 dfs]$ pwd
/opt/module/hadoop-2.7.2/data/tmp/dfs
[shangbaishuyao@hadoop102 dfs]$ ls
data name namesecondary导入检查点数据(等待一会ctrl+c结束掉)
[shangbaishuyao@hadoop102 hadoop-2.7.2]$ bin/hdfs namenode -importCheckpoint启动NameNode
[shangbaishuyao@hadoop102 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode
Hadoop集群安全模式
概述:

基本语法:
集群处于安全模式,不能执行重要操作(写操作)。集群启动完成后,自动退出安全模式。
(1)bin/hdfs dfsadmin -safemode get (功能描述:查看安全模式状态)
(2)bin/hdfs dfsadmin -safemode enter (功能描述:进入安全模式状态)
(3)bin/hdfs dfsadmin -safemode leave (功能描述:离开安全模式状态)
(4)bin/hdfs dfsadmin -safemode wait (功能描述:等待安全模式状态)
NameNode多目录配置
NameNode的本地目录可以配置成多个,且每个目录存放内容相同,增加了可靠性
具体配置如下
1
2
3
4
5
(1) 在hdfs-site.xml文件中增加如下内容,引用了hdfs-core.xml的hadoop.tmp.dir配置
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///${hadoop.tmp.dir}/dfs/name1,file:///${hadoop.tmp.dir}/dfs/name2</value>
</property>
1
2
3
4
(2) 停止集群,删除data和logs中所有数据。
[shangbaishuyao hadoop-2.7.2]$ rm -rf data/ logs/
[shangbaishuyao hadoop-2.7.2]$ rm -rf data/ logs/
[shangbaishuyao hadoop-2.7.2]$ rm -rf data/ logs/
1
2
3
(3) 格式化集群并启动。
[shangbaishuyao hadoop-2.7.2]$ bin/hdfs namenode –format
[shangbaishuyao hadoop-2.7.2]$ sbin/start-dfs.sh
1
2
3
4
5
6
(4) 查看结果
[shangbaishuyao dfs]$ ll
总用量 12
drwx------. 3 shangbaishuyao shangbaishuyao 4096 12月 11 08:03 data
drwxrwxr-x. 3 shangbaishuyao shangbaishuyao 4096 12月 11 08:03 name1
drwxrwxr-x. 3 shangbaishuyao shangbaishuyao 4096 12月 11 08:03 name2
DataNode工作机制
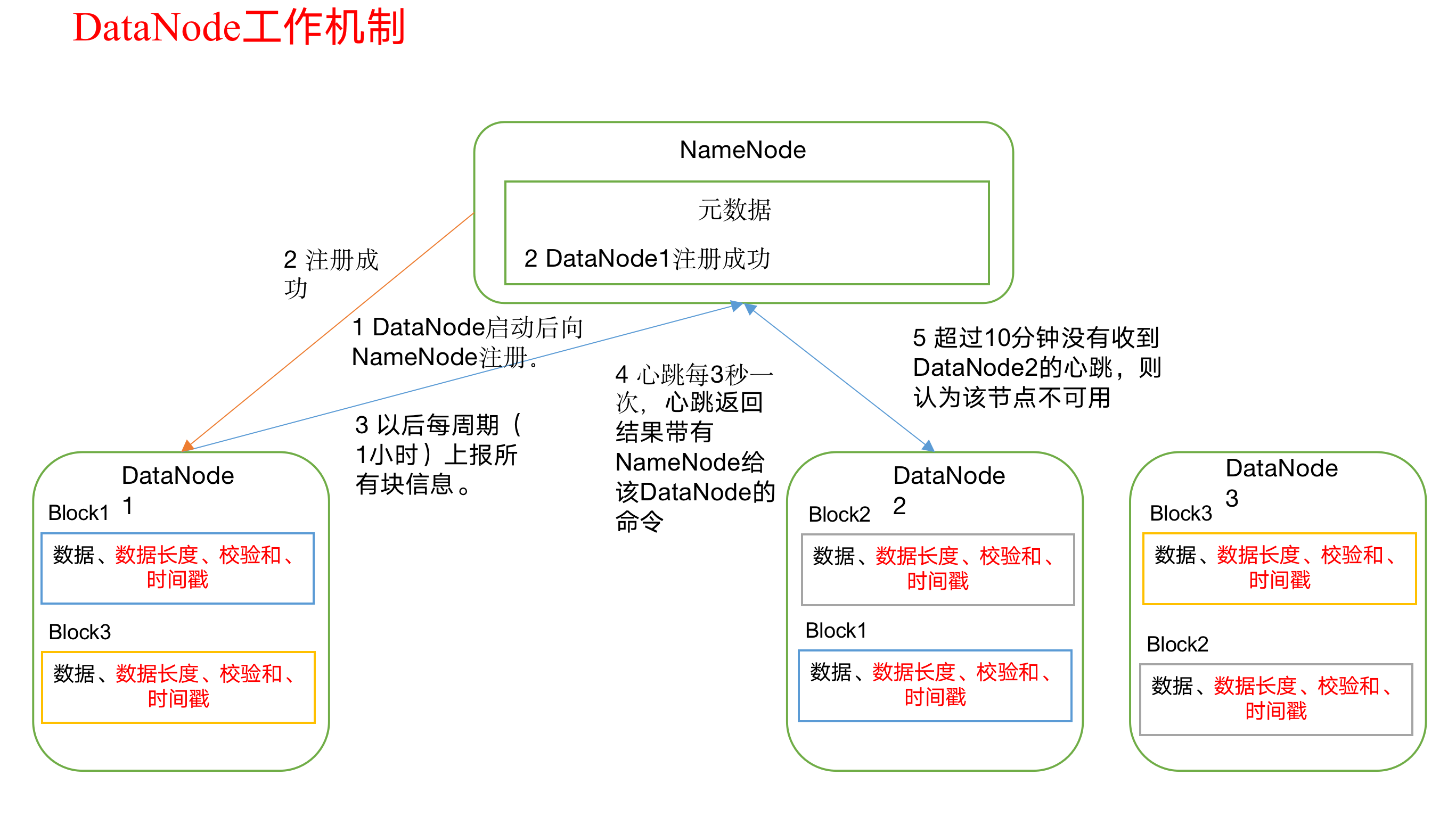
1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的 校验和,以及时间戳。
2)DataNode启动后向NameNode注册,通过后,周期性(1小时)的向NameNode上报所有的块信息。
3)心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟30秒没有收到某个DataNode的心跳,则认为该节点不可用。
4)集群运行中可以安全加入和退出一些机器。
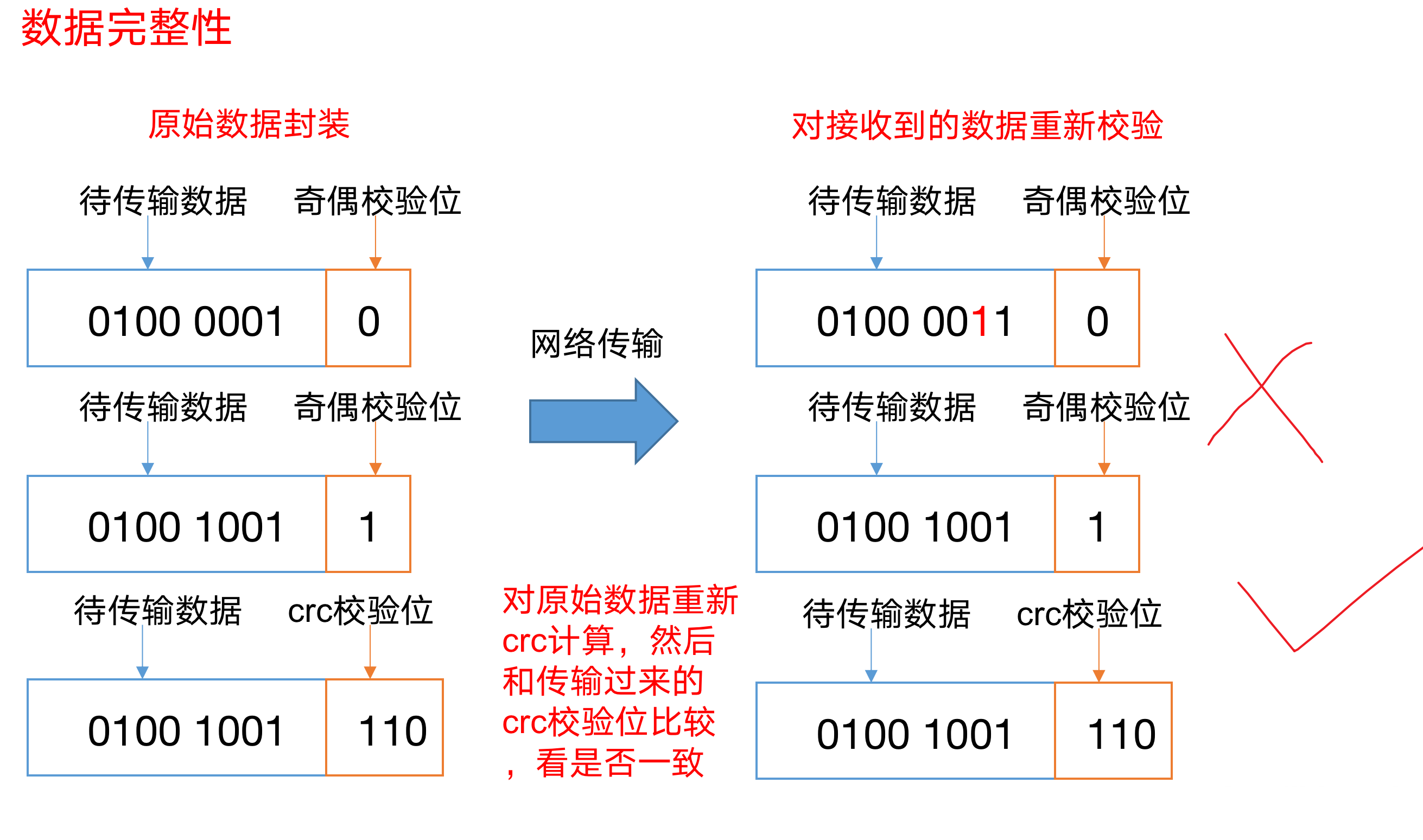
数据完整性(如何保存存储的数据是完整的?)
思考:如果电脑磁盘里面存储的数据是控制高铁信号灯的红灯信号(1)和绿灯信号(0),但是存储该数据的磁盘坏了,一直显示是绿灯,是否很危险?同理DataNode节点上的数据损坏了,却没有发现,是否也很危险,那么如何解决呢?
如下是DataNode节点保证数据完整性的方法。
1)当DataNode读取Block的时候,它会计算CheckSum(校验和)。校验和,就是经过一定的算法的到一个数据的结果,这个结果就是校验和; 一个数据在上传前经过算法变成校验盒,然后再把数据放到hdfs上,经过算法变成校验盒,如果前后两个校验盒相同,则说明数据完整,数据没发生破坏对于银行等机构,数据完整性是相当重要的
2)如果计算后的CheckSum,与Block创建时值不一样,说明Block已经损坏。
3)Client读取其他DataNode上的Block。
4)DataNode在其文件创建后周期验证CheckSum,如图所示。
掉线时限参数设置 10分钟30秒

需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval(心跳核查间隔)的单位为毫秒,dfs.heartbeat.interval的单位为秒。
1 | <property> |
HDFS Federation架构设计
NameNode架构的局限性(内存瓶颈, 毕竟是一台服务器嘛, 内存在高也就那么多)
(1)Namespace(命名空间)的限制
1 | 由于NameNode在内存中存储所有的元数据(metadata),因此单个NameNode所能存储的对象(文件+块)数目受到NameNode 所在JVM的heap size(堆大小)的限制。50G的heap(堆)能够存储20亿(200million)个对象,这20亿个对象支持4000个DataNode,12PB的存储(假设文件平均大小为40MB)。随着数据的飞速增长,存储的需求也随之增长。单个DataNode从4T增长到36T,集群的尺寸增长到8000个DataNode。存储的需求从12PB增长到大于100PB。 |
(2)隔离问题
1 | 由于HDFS仅有一个NameNode,无法隔离各个程序,因此HDFS上的一个实验程序就很有可能影响整个HDFS上运行的程序。 |
(3)性能的瓶颈
1 | 由于是单个NameNode的HDFS架构,因此整个HDFS文件系统的吞吐量受限于单个NameNode的吞吐量。 |
HDFS Federation架构设计,如图所示
能不能有多个NameNodeNameNode NameNode NameNode 元数据 元数据 元数据 Log machine 电商数据/话单数据
HDFS Federation架构设计图:

HDFS Federation应用思考
不同应用可以使用不同NameNode进行数据管理
图片业务、爬虫业务、日志审计业务
Hadoop生态系统中,不同的框架使用不同的NameNode进行管理NameSpace。(隔离性)


- 本文作者: xubatian
- 本文链接: http://xubatian.cn/hadoop组成模块之HDFS分布式存储详解/
- 版权声明: 本博客所有文章除特别声明外均为原创,采用 CC BY 4.0 CN协议 许可协议。转载请注明出处:https://www.xubatian.cn/
 故人的博客
故人的博客
 IT周的博客
IT周的博客
 大胖胖的笔记
大胖胖的笔记
 常瑞的部落落
常瑞的部落落
 Fortune博客
Fortune博客
 星空下的YZY
星空下的YZY
 BOBL技术博客
BOBL技术博客