

闲适因为忙碌才获得意义。如果摸鱼成为常态,放松就失去了意义;如果划水占据人生,幸福就会失去方向。 ——人民日报

RDD编程
创建RDD ,RDD的转换, RDD的输出
编程模型
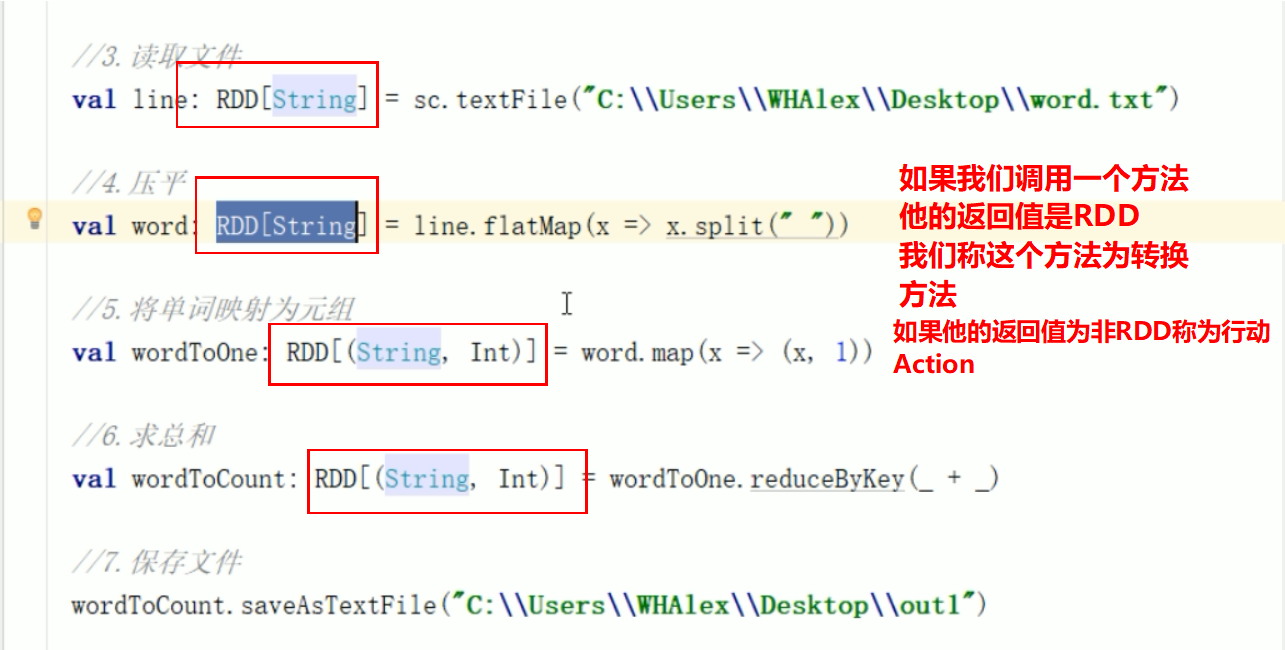
在spark中无论是Transformations方法还是Actions方法,我们都要把他们称作算子
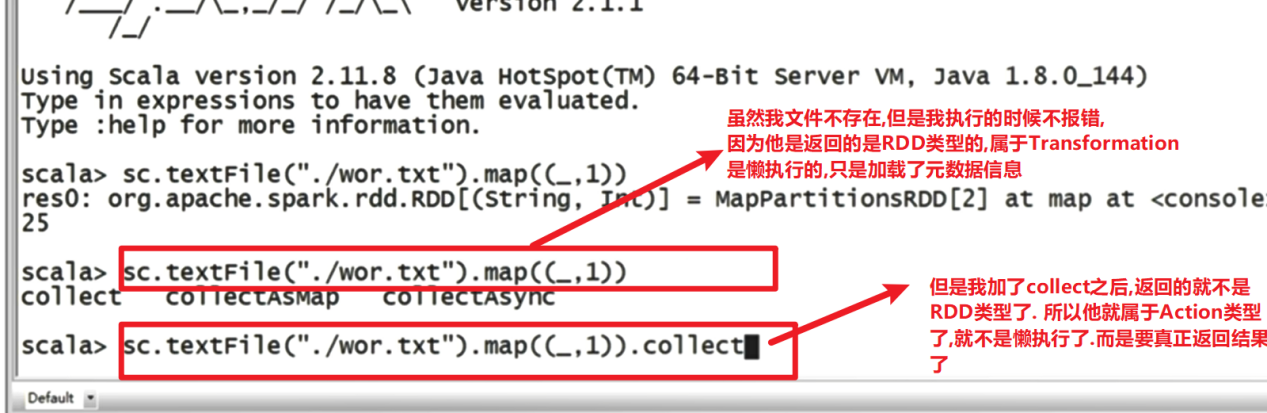
在Spark中,RDD被表示为对象,通过对象上的方法调用来对RDD进行转换。经过一系列的Transformations(转换)定义RDD之后,就可以调用Actions(行动)触发RDD的计算,Action可以是向应用程序返回结果(count, collect等),或者是向存储系统保存数据(saveAsTextFile等)。在Spark中,只有遇到Action,才会执行RDD的计算(即延迟计算),这样在运行时可以通过管道的方式传输多个转换。
要使用Spark,开发者需要编写一个Driver程序,它被提交到集群以调度运行。Driver中定义了一个或多个RDD,并调用RDD上的Action,Executor则执行RDD分区计算任务。
Actions(行动)算子会真正的去触发job去执行
Transformation(转换)算子懒执行
所以返回值是RDD类型的是Transformation算子,返回值非RDD类型就是Action算子
RDD的创建
在Spark中创建RDD的创建方式可以分为三种:
从scala集合中创建RDD;
从外部存储创建RDD;
从其他RDD创建(这个其实讲的就是转换)。
从集合中创建
从集合中创建RDD,Spark主要提供了两种函数:parallelize(并行化)和makeRDD(创建RDD)
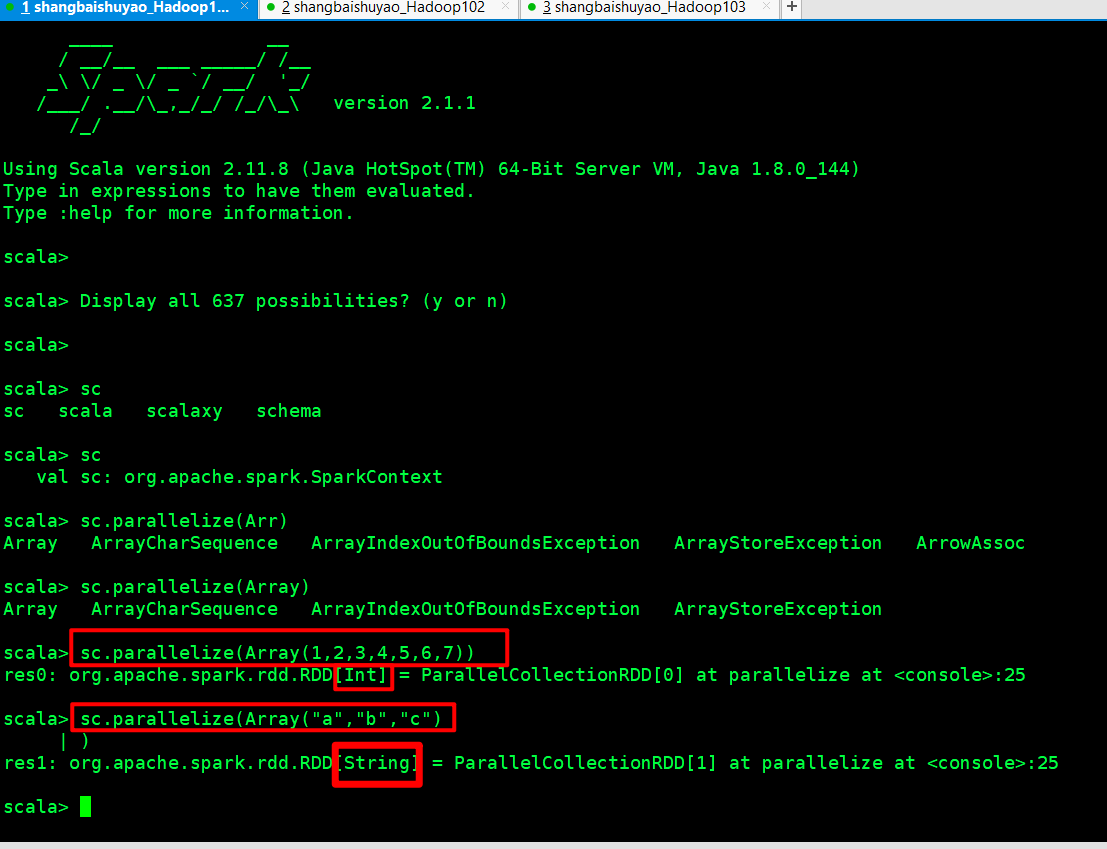
1)使用parallelize()从集合创建
1 | scala> val rdd = sc.parallelize(Array(1,2,3,4,5,6,7,8)) |
2)使用makeRDD()从集合创建
1 | scala> val rdd1 = sc.makeRDD(Array(1,2,3,4,5,6,7,8)) |
由外部存储系统的数据集创建
包括本地的文件系统,还有所有Hadoop支持的数据集,比如HDFS、Cassandra、HBase等,
1 | scala> val rdd2= sc.textFile("hdfs://hadoop102:9000/RELEASE") |
从其他RDD创建
下面都是…此处略
RDD的转换
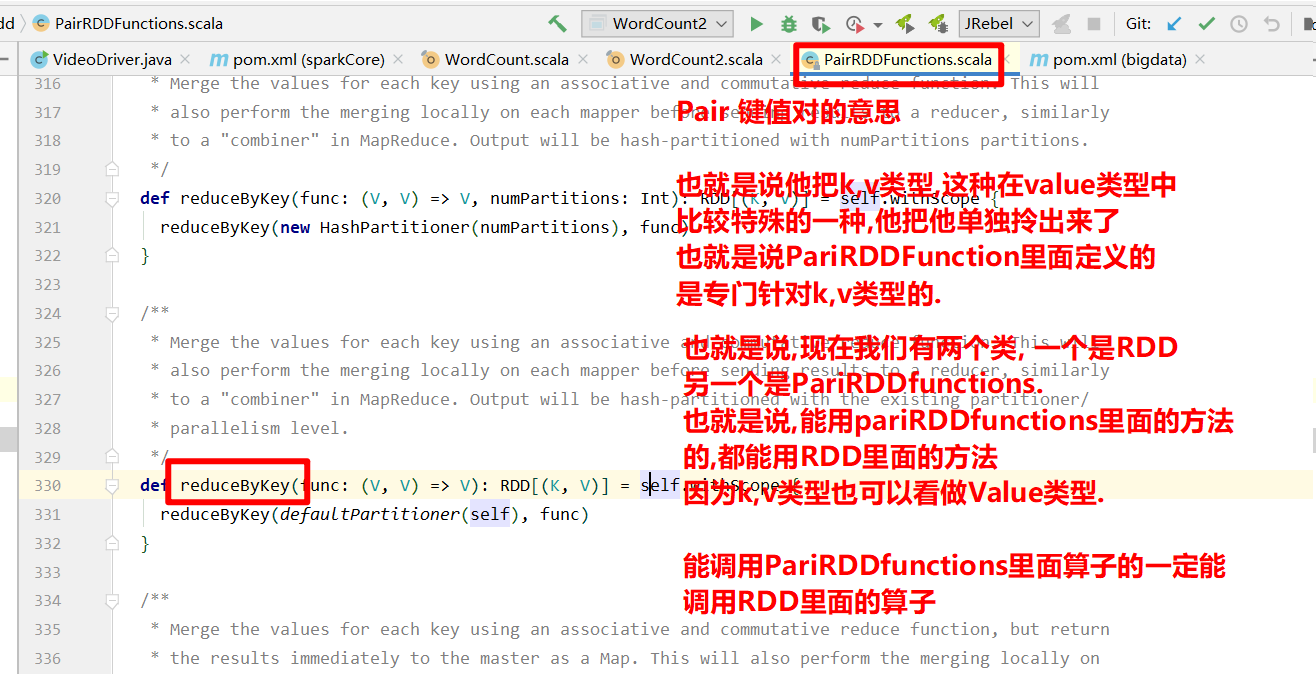
RDD整体上分为Value类型和Key-Value类型, K-V形式其实也是value类型
eg: (k,(k,v))是value, 是不是kv? 是,只不过value类型是二元组.
如果是单个值, 是value, 如果是形如二元组是K,V. k,v形式是value类型, 我把整个k,v元组当成整体来看,他就是value类型. 他们两是包含的关系. 所有的RDD都可以看做是value类型, 只过不特殊的我们拎出来,如k-v等等
Value类型
什么叫做value类型呢?
因为他里面传的函数都是操作当前这个RDD里面的元素. 可能是单个元素, 可能是一个分区里面的元素.但是他操作的是里面的数据.
什么叫双value类型呢?
双value类型它里面传的参数是任意一个RDD.
Eg : RDD1.调用一个算子(RDD2)
以为之前提过, scala也好,spark也好,他是面向数据处理的. 那这个双value类型就是数学里面的,集合之间的关系. 集合里面有哪些关系呢? 并集, 交叉 ,笛卡尔集
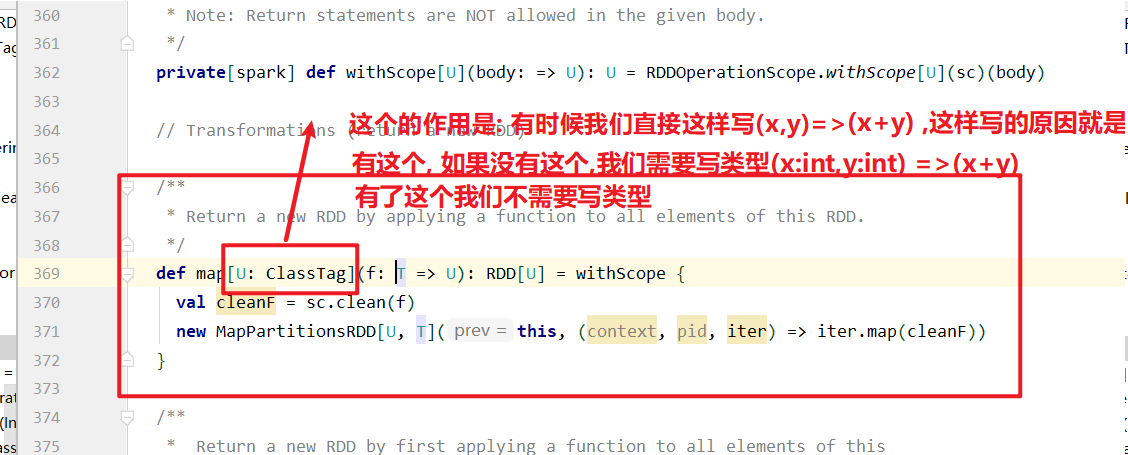
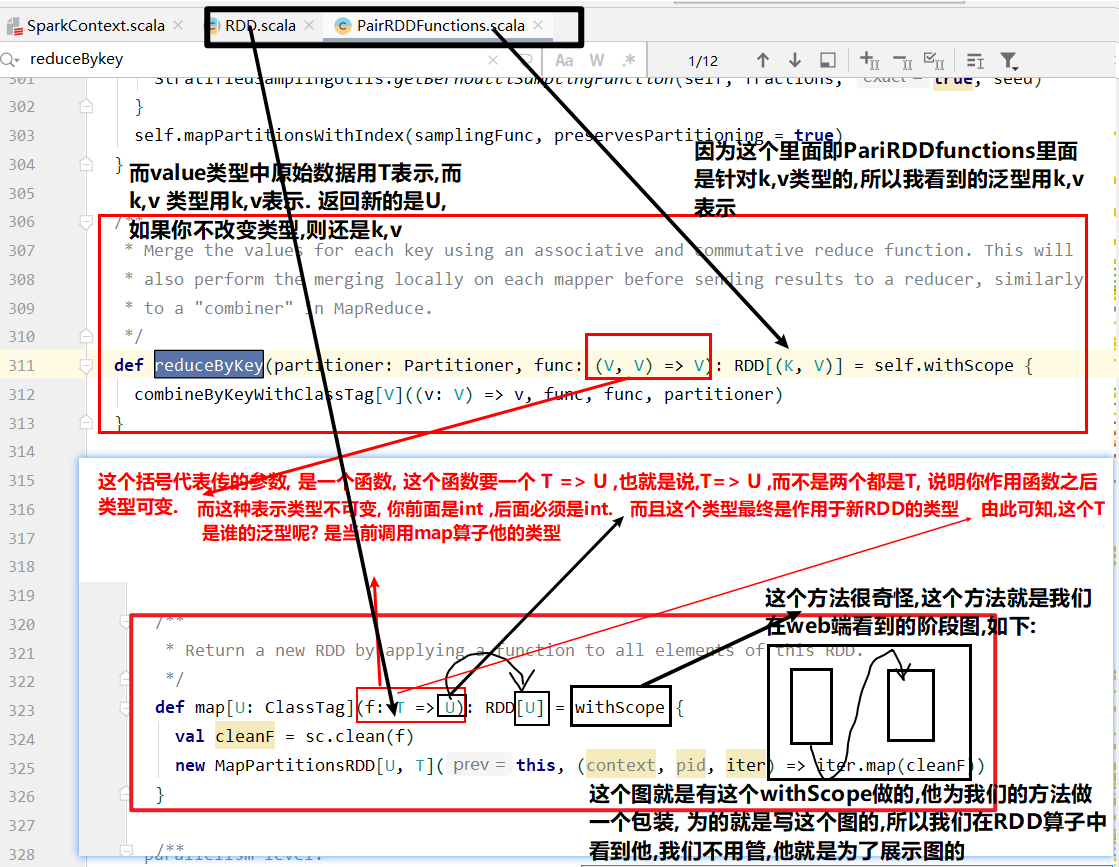
map(func)案例
1 | 1. 作用:返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成 |
(1) 创建
1 | scala> var source = sc.parallelize(1 to 10) |
(2)打印
1 | scala> source.collect() |
(3)将所有元素*2
1 | scala> val mapadd = source.map(_ * 2) |
(4)打印最终结果
1 | scala> mapadd.collect() |
双Value类型交互
以后慢慢写……
Key-Value类型
以后慢慢写……


- 本文作者: xubatian
- 本文链接: http://xubatian.cn/SparkCore之RDD编程的编程模型/
- 版权声明: 本博客所有文章除特别声明外均为原创,采用 CC BY 4.0 CN协议 许可协议。转载请注明出处:https://www.xubatian.cn/
 故人的博客
故人的博客
 IT周的博客
IT周的博客
 大胖胖的笔记
大胖胖的笔记
 常瑞的部落落
常瑞的部落落
 Fortune博客
Fortune博客
 星空下的YZY
星空下的YZY
 BOBL技术博客
BOBL技术博客