

什么是Spark SQL
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了2个编程抽象:DataFrame和DataSet,并且作为分布式SQL查询引擎的作用。
我们已经学习了Hive,它是将Hive SQL转换成MapReduce然后提交到集群上执行,大大简化了编写MapReduc的程序的复杂性,由于MapReduce这种计算模型执行效率比较慢。所有Spark SQL的应运而生,它是将Spark SQL转换成SparkCore来运行,然后提交到集群执行,执行效率非常快!
Spark SQL其实和hive替代MapReduce一样的.
Spark SQL的特点
1)易整合

1 | 集成 |
2)统一的数据访问方式
1 | 以前我们读hive,读JDBC,读Json都是要创建对象的,现在我们统一有一个对象 |

1 | 统一的数据访问 |
3)兼容Hive
1 | spark内置hive的数据库是der, 所以我们换成外部的hive,用外部的hive也比较简单,我不需要告诉他计算引擎MR在哪,只需要告诉他元数据信息就可以了,你能让spark通过元数据找到实际数据所在地就行了,元数据在hive当中存在哪呢?在mysql当中,hive不是天生就存在mysql当中的,是有一个配置文件告诉他的,如果说你的spark sql想用之前hive里面的数据很简单,你把配置文件hive-site.xml配置给他移到spark.conf里面就够了,然后你一打开他就完成了之前和你hive数据的对接了 |
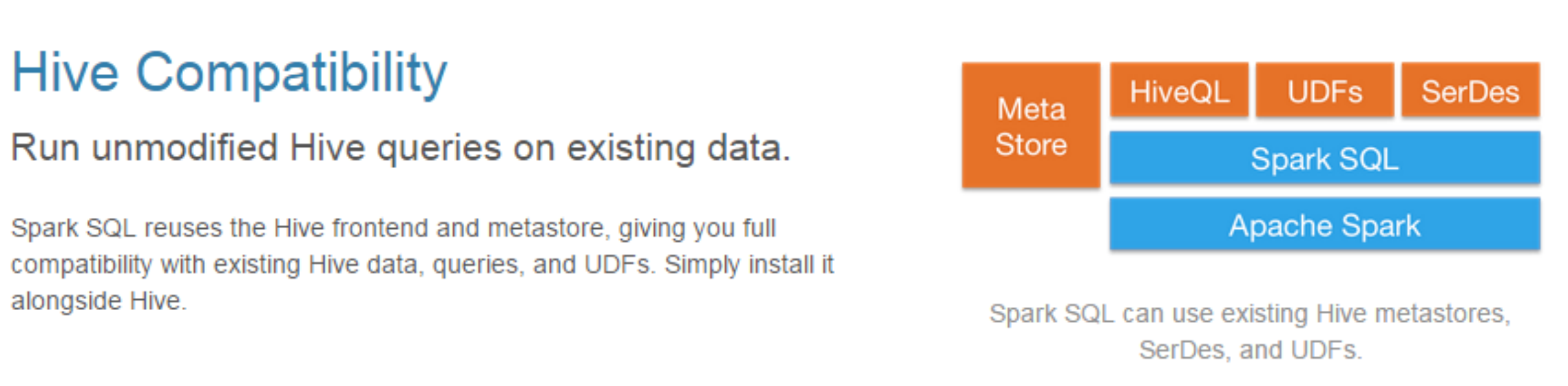
1 | 具有和Hive的兼容性 |
4)标准的数据连接

1 | 标准的连接 |
什么是DataFrame(数据框)
1 | 在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。 |
1 | ataFrame也是懒执行的,但性能上比RDD要高,主要原因:高在哪呢?主要就是他有优化器 |

1 | ResultSet():这个方法很恶心,就是编译期不做类型校验,但是你一运行就会报类型转换异常 |
什么是DataSet
1 | DataSet是分布式数据集合。DataSet是Spark 1.6中添加的一个新抽象,是DataFrame的一个扩展。它提供了RDD的优势(强类型,使用强大的lambda函数的能力)以及Spark SQL优化执行引擎的优点。而对于SparkSQl的Setframe来说,我们可以说DataFrame是弱类型的.因为他在编译期间不做类型检查.这就给用户带来很不舒服. 而dataSet是可以放一个泛型为具体的样例类.痛过样例类来获取他的一个属性.那这个类型在编译期间是一定能够检查的. |



- 本文作者: xubatian
- 本文链接: http://xubatian.cn/Spark原理与实现-SparkSQL的概述/
- 版权声明: 本博客所有文章除特别声明外均为原创,采用 CC BY 4.0 CN协议 许可协议。转载请注明出处:https://www.xubatian.cn/
 故人的博客
故人的博客
 IT周的博客
IT周的博客
 大胖胖的笔记
大胖胖的笔记
 常瑞的部落落
常瑞的部落落
 Fortune博客
Fortune博客
 星空下的YZY
星空下的YZY
 BOBL技术博客
BOBL技术博客