

通用加载/保存方法
注意:sparkSQL可以读Json文件,但是一整行必须是一个完整的文件,如下图

加载数据 (read 直接加载 / format 指定加载数据类型)
1)read直接加载数据(读数据)
1 | scala> spark.read. |
注意:加载数据的相关参数需写到上述方法中。如:textFile需传入加载数据的路径,jdbc需传入JDBC相关参数。
2)format指定加载数据类型
1 | scala> spark.read.format("…")[.option("…")].load("…") |
用法详解:
(1)format(“…”):指定加载的数据类型,包括”csv”、”jdbc”、”json”、”orc”、”parquet”和”textFile”。
(2)load(“…”):在”csv”、”orc”、”parquet”和”textFile”格式下需要传入加载数据的路径。
(3)option(“…”):在”jdbc”格式下需要传入JDBC相应参数,url、user、password和dbtable
保存数据 (write 直接保存数据 / format指定保存数据类型)
1)write直接保存数据
注意:要知道我们读数据使用spark调用的,但是我们保存数据不是使用Spark调用了.RDD的创建一般是从SparkContext开始的. DataFrame的创建一般是从spark开始的. 保存是将RDD保存出去,所以是DataFrame或者dataset,所以应该拿DataFrame去调用保存方法.因为你要保存的是当前的数据集.
1 | scala> df.write. |
注意:保存数据的相关参数需写到上述方法中。如:textFile需传入加载数据的路径,jdbc需传入JDBC相关参数。
2)format指定保存数据类型
1 | scala> df.write.format("…")[.option("…")].save("…") |
用法详解:
(1)format(“…”):指定保存的数据类型,包括”csv”、”jdbc”、”json”、”orc”、”parquet”和”textFile”。
(2)save (“…”):在”csv”、”orc”、”parquet”和”textFile”格式下需要传入保存数据的路径。
(3)option(“…”):在”jdbc”格式下需要传入JDBC相应参数,url、user、password和dbtable
3)文件保存选项
可以采用SaveMode执行存储操作,SaveMode定义了对数据的处理模式。SaveMode是一个枚举类,其中的常量包括:
(1)Append:当保存路径或者表已存在时,追加内容;
(2)Overwrite: 当保存路径或者表已存在时,覆写内容;
(3)ErrorIfExists:当保存路径或者表已存在时,报错;
(4)Ignore:当保存路径或者表已存在时,忽略当前的保存操作。
使用详解:
1 | df.write.mode(SaveMode.Append).save("… …") |
默认数据源
Spark SQL的默认数据源为Parquet格式。数据源为Parquet文件时,Spark SQL可以方便的执行所有的操作。修改配置项Spark.sql.sources.default,可修改默认数据源格式。
1)加载数据
1 | val df = spark.read.load("examples/src/main/resources/users.parquet") |
2)保存数据
1 | df.select("name", " color").write.save("user.parquet") |
JSON文件
Spark SQL 能够自动推测 JSON数据集的结构,并将它加载为一个Dataset[Row] Dataset意思为数据集. 可以通过SparkSession.read.json()去加载一个 一个JSON 文件。
注意:这个JSON文件不是一个传统的JSON文件,每一行都得是一个JSON串。格式如下:
1 | {"name":"Michael"} |
1)导入隐式转换
1 | import spark.implicits._ |
2)加载JSON文件
1 | val path = "examples/src/main/resources/people.json" |
3)创建临时表
1 | peopleDF.createOrReplaceTempView("people") |
4)数据查询
1 | val teenagerNamesDF = spark.sql("SELECT name FROM people WHERE age BETWEEN 13 AND 19") |
MySQL
Spark SQL可以通过JDBC从关系型数据库中读取数据的方式创建DataFrame,通过对DataFrame一系列的计算后,还可以将数据再写回关系型数据库中。
可在启动shell时指定相关的数据库驱动路径,或者将相关的数据库驱动放到spark的类路径下。
1)启动spark-shell
1 | bin/spark-shell --master spark://hadoop102:7077 [--jars mysql-connector-java-5.1.27-bin.jar] |


2)定义JDBC相关参数配置信息
1 | val connectionProperties = new Properties() |
3)使用read.jdbc加载数据
1 | val jdbcDF2 = spark.read.jdbc("jdbc:mysql://hadoop102:3306/rdd", "rddtable", connectionProperties) |
4)使用format形式加载数据
1 | val jdbcDF = spark.read.format("jdbc").option("url", "jdbc:mysql://hadoop102:3306/rdd").option("dbtable", " rddtable").option("user", "root").option("password", "xww2018").load() |
5)使用write.jdbc保存数据
1 | jdbcDF2.write.jdbc("jdbc:mysql://hadoop102:3306/mysql", "db", connectionProperties) |
6)使用format形式保存数据
1 | jdbcDF.write |
Hive

内嵌Hive应用 (基本不用)
如果要使用内嵌的Hive,什么都不用做,直接用就可以了。
可以修改其数据仓库地址,参数为:–conf spark.sql.warehouse.dir=./wear
注意:如果你使用的是内部的Hive,在Spark2.0之后,spark.sql.warehouse.dir用于指定数据仓库的地址,如果你需要是用HDFS作为路径,那么需要将core-site.xml和hdfs-site.xml 加入到Spark conf目录,否则只会创建master节点上的warehouse目录,查询时会出现文件找不到的问题,这是需要使用HDFS,则需要将metastore(元数据 )删除,重启集群。
外部Hive应用 (正常用外置的hive )
如果想连接外部已经部署好的Hive,需要通过以下几个步骤。
1)将Hive中的hive-site.xml拷贝或者软连接到Spark安装目录下的conf目录下。

注释掉Tez引擎,因为你是用的是Spark作为引擎了.
启动hadoop集群
2)打开spark shell,注意带上访问Hive元数据库的JDBC客户端
1 | bin/spark-shell --master spark://hadoop102:7077 --jars mysql-connector-java-5.1.27-bin.jar |
注意:启动时指定JDBC jar包路径很麻烦,我们可以选择将JDBC的驱动包放置在spark的lib目录下,一劳永逸。


创建的这个表是一个非临时表

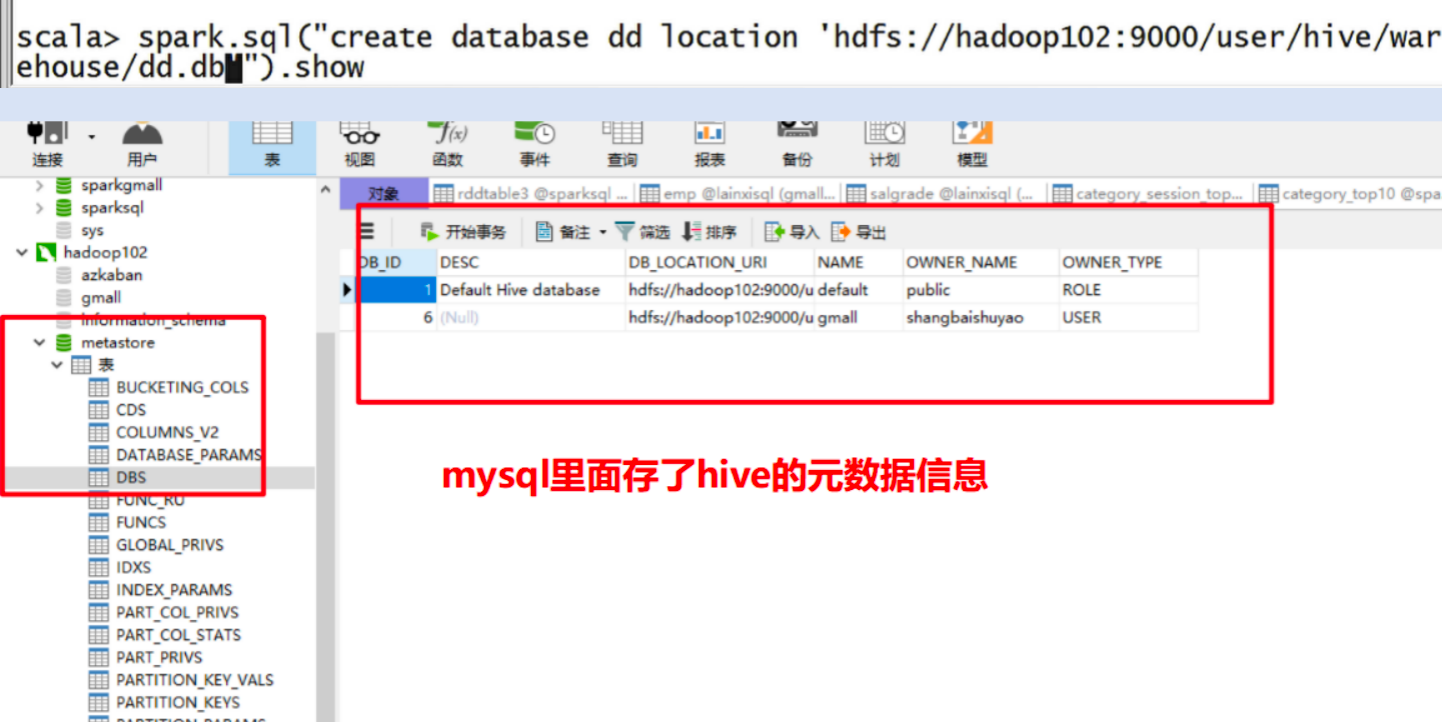

运行Spark SQL CLI
Spark SQL CLI可以很方便的在本地运行Hive元数据服务以及从命令行执行查询任务。在Spark目录下执行如下命令启动Spark SQL CLI,直接执行SQL语句,类似一Hive窗口。
1 | /bin/spark-sql |
代码中操作Hive
1)添加依赖
1 | <dependency> |
2)代码实现
1 | //创建SparkSession |


- 本文作者: xubatian
- 本文链接: http://xubatian.cn/Spark原理与实现-Spark-SQL编程之Spark-SQL数据的加载与保存/
- 版权声明: 本博客所有文章除特别声明外均为原创,采用 CC BY 4.0 CN协议 许可协议。转载请注明出处:https://www.xubatian.cn/
 故人的博客
故人的博客
 IT周的博客
IT周的博客
 大胖胖的笔记
大胖胖的笔记
 常瑞的部落落
常瑞的部落落
 Fortune博客
Fortune博客
 星空下的YZY
星空下的YZY
 BOBL技术博客
BOBL技术博客