

骑假马练不出真演技。流量转瞬即逝,常量才能长青。 ——人民日报

前言
上文 对mapreduce的概述 简单了解什么是MapReduce?
MapReduce是hadoop解决大数据计算问题的而落地的一个计算引擎. 他是一个计算框架.
mapreduce如何做到海量数据的计算的呢?
mapreduce的流程是什么样子的呢?
mapreduce的有哪些部分组成的的?
图示:
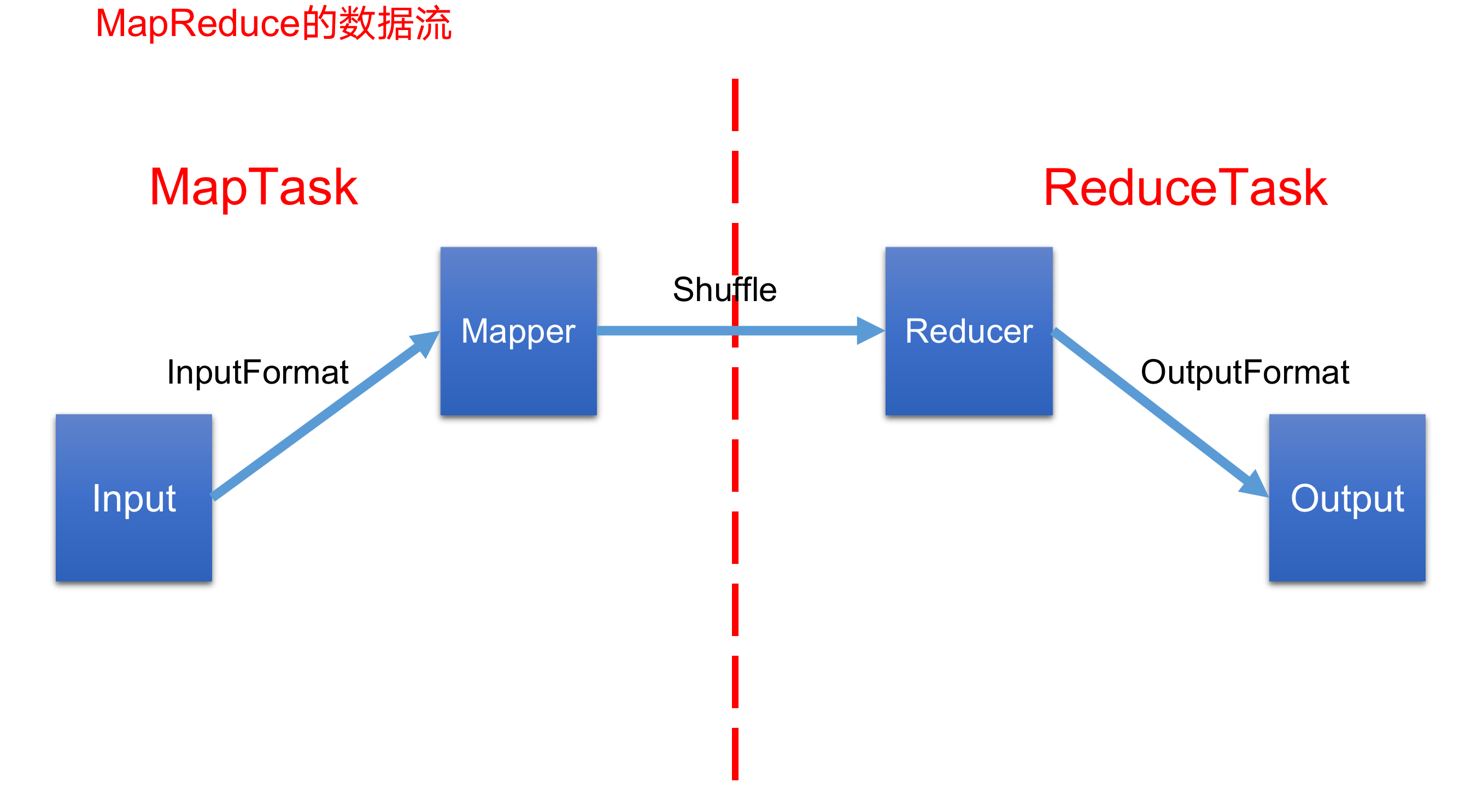
如上图所示, 这就是完整的mapreduce 的数据流图.
首先我们知道了hadoop的hdfs是将海量的数据进行了存储. 而hadoop的mapreduce是将存储的海量数据进行计算得出我们想要的结果.
那么他要计算这些数据. 首先他得将数据输入到我们的计算引擎mapreduce当中, 即使用Inputformat将数据导入到mapreduce里面来, 然后通过mapTask将数据打散,即map任务, 再通过reduceTask任务将数据聚合,即reduce任务. 最后通过outputFormat将计算的结果输出到某个文件或者某个数据库中.
那么由此可知. 整个mapreduce是由. Inputformart输入数据. MapTask 打散数据. ReduceTask聚合数据. Outputformart输出结果.这几个部分组成的. 所以,要知道mapreduce的框架原理.需要学习组成mapreduce的四个环节.
那么这四个环节分别叫什么呢?
InputFormat数据输入—–>MapTask工作机制,Shuffle工作机制,ReduceTask工作机制—>OutputFormat数据输出.
着整个过程成为 mapreduce过程. 内容分这几个部分. 当然,这几部分也是很笼统的. 里面设计具体的很多概念.
MapReduce框架原理之InputFormat数据输入
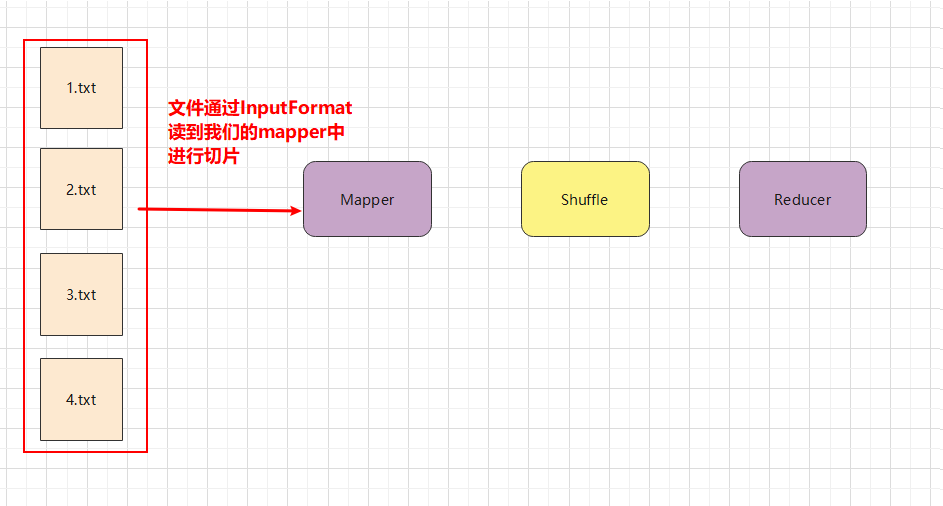
InputFormat, 这个是整个MapReduce里面非常关键的一个对象.
什么是InputFormat呢? 就是你输入到这个mapper里面的数据其实就是由InputFormat来负责的. 比如我怎么从文件里面去读这个数据. 这里还涉及到是否要切片这个概念.
MapReduce数据流是比较简单的.一个是mapper阶段. 一个是reduce阶段. 在mapper阶段前面就有一个InputFormat帮我们去读数据. 在Reducer后面有一个OutPutFormat帮我们去写数据.在mapper与reducer中间就是我们讲的shuffle过程.大部分工作都是在shuffle里面做的.
那么 InputFormat他又是如何拿数据呢? 这涉及到了切片机制. 那么什么是切片呢?
我数据是按照块(block)的的方式去存到HDFS上的. 那么既然他是按照块存储的. 假设配置文件设置128M为一块,一个300M文件分成了三个块.可能存到不同的服务器上. 那么我mapreduce也是按照块为单位去拿数据吗? 不是的, 他是将这128M的块, 按照我们配置的配置文件的切片大小去获取数据. 比如 我们设置100M 为一个切片. 那么这个128M的块, 就会有两个切片.即100M 和 28M. mapreduce启动job任务去拿数据他是并行的, 所以一个mapTask只会获取一个切片,所以,他会启动两个mapTask同时去拿这两个切片.
注意: 切片不是物理上将块切开的,而是逻辑上切开的.
总结: 切片和InputFormat有啥联系呢?是在切片信息的时候涉及到. 要知道我们的切片是由我们InputFormat来负责的.
既然 切片是由Inputformat负责的,所以需要了解什么是切片.
切片与MapTask并行度决定机制
切片不从物理上切开,比如说,我有一个两百兆的文件.我上传到HDFS以后. 假如说的我一块的大小是128M. 那么这个200M的文件上传到HDFS以后被切成了两块了.
第一块128M,第二块72M. 到此为止只是块的概念.
接下来我就要通过map来分析你这个数据了.正常情况下,其实你的一个块的数据要交给mapTask去处理.但是严格意义上并不是这样的.而是一个切片要交给一个mapTask来处理.
那么这个切片是怎么来的呢?
切片和块的大小有点关系,但是我们可以自己去设置有多大. 比如假设我设置我的切片大小是64M. 那么对于128M块大小的数据在真正进入到map要处理的时候.会把这个128M的块的数据从逻辑上切成两片.
第一片交给一个mapTask去处理.
第二片也交给一个mapTask去处理.
所以说,严格来说不是一个块的数据交给mapTask.而是一个切片的数据交给一个mapTask.
72M的也是切成两片.
这里我们所说的切只是逻辑上的,这个块还是整个的一个块,128M.他是不会从物理上给你切开的. 只是逻辑上的.
一个切片,一个mapTask. 注意: 默认情况下切片的大小和块的大小是一样的.
也就意味着不自己设置的情况下.他的一个切片的大小也是128M. 正好我的默认情况下块的大小是一样的.
那么问题来了, 我是不是一个切片越大,mapTask越多,我并行能力越强,是否我的性能就越高呢?
问题引出
MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个Job的处理速度。
思考:1G的数据,启动8个MapTask,可以提高集群的并发处理能力。那么1K的数据,也启动8个MapTask,会提高集群性能吗?MapTask并行任务是否越多越好呢?哪些因素影响了MapTask并行度?
MapTask并行度决定机制
数据块:Block是HDFS物理上把数据分成一块一块。
数据切片:数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。(逻辑上对数据块进行划分,让多个mapTask并行处理数据块的不同切片部分)
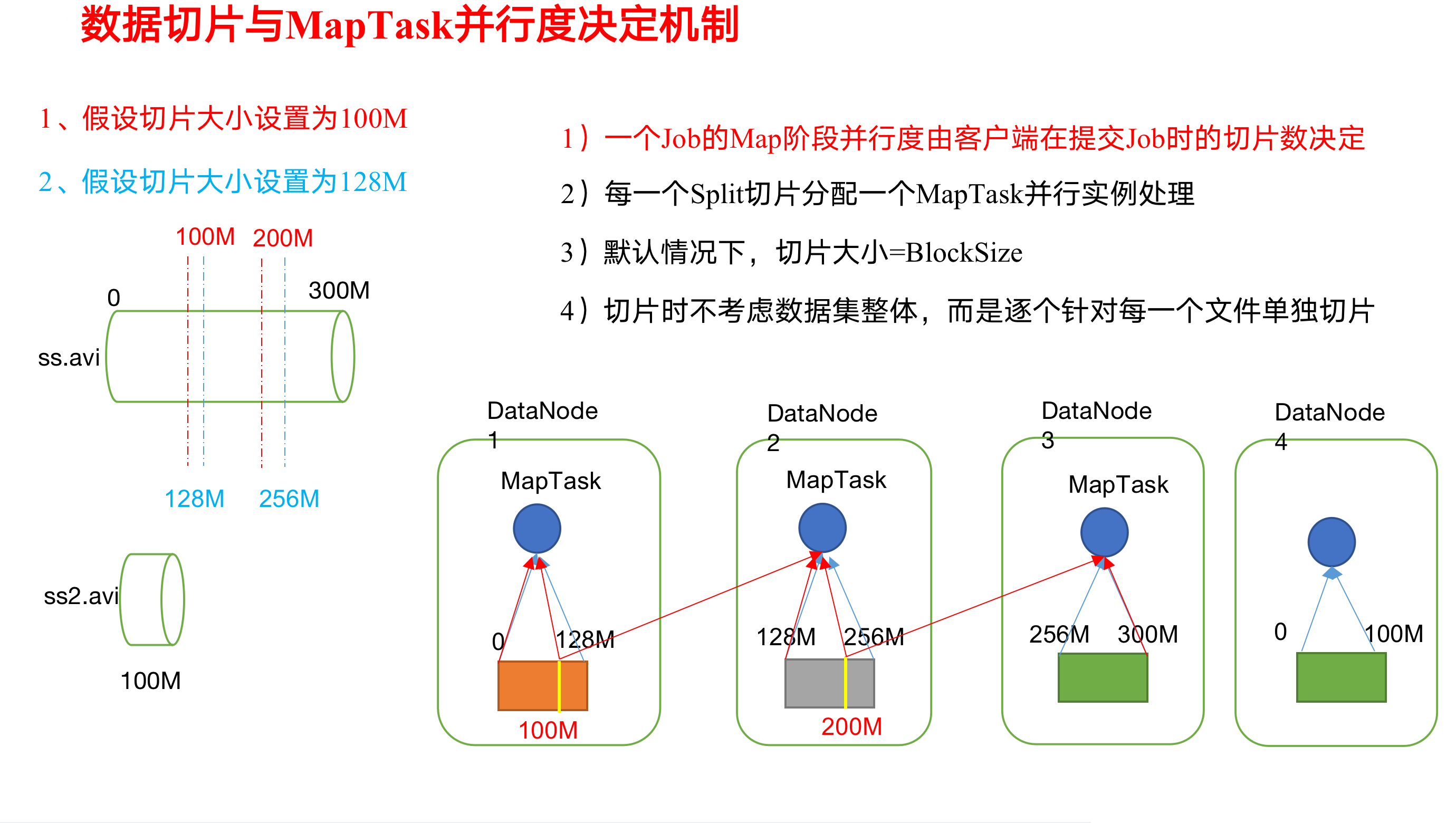
假如我有300M的数据.假设切片大小我设置为100M. 块大小设置为128M. 那么这个300M的文件将来我存到dataNode上面的时候,如上图. 128M一块 ,128M一块, 44M一块.
块大小还是按照128M. 但是我的切片大小是100M. 那么将来我在处理我128M的数据的时候,那我就要从逻辑上将我的128M块 切片分成100M 和 28M. 其中这100M我交给mapTask去处理. 那么我剩下的28M怎么办呢? 他不是在往后面找72M数据合起来. 他有一个切片的概念. 切片他是不考虑数据的整体性. 正常情况下他是以块来作为一个单位来切的. 所以hadoop他默认就是按照128M来切的.这样就不用了跨机器读你的数据了.
记住: 你有多少个切片,将来你就有多少个mapTask. 每一个切片都分配一个mapTask来进行并行处理. 默认情况下切片大小就是你的块大小.
通过源码查看切片机制
数据倾斜问题
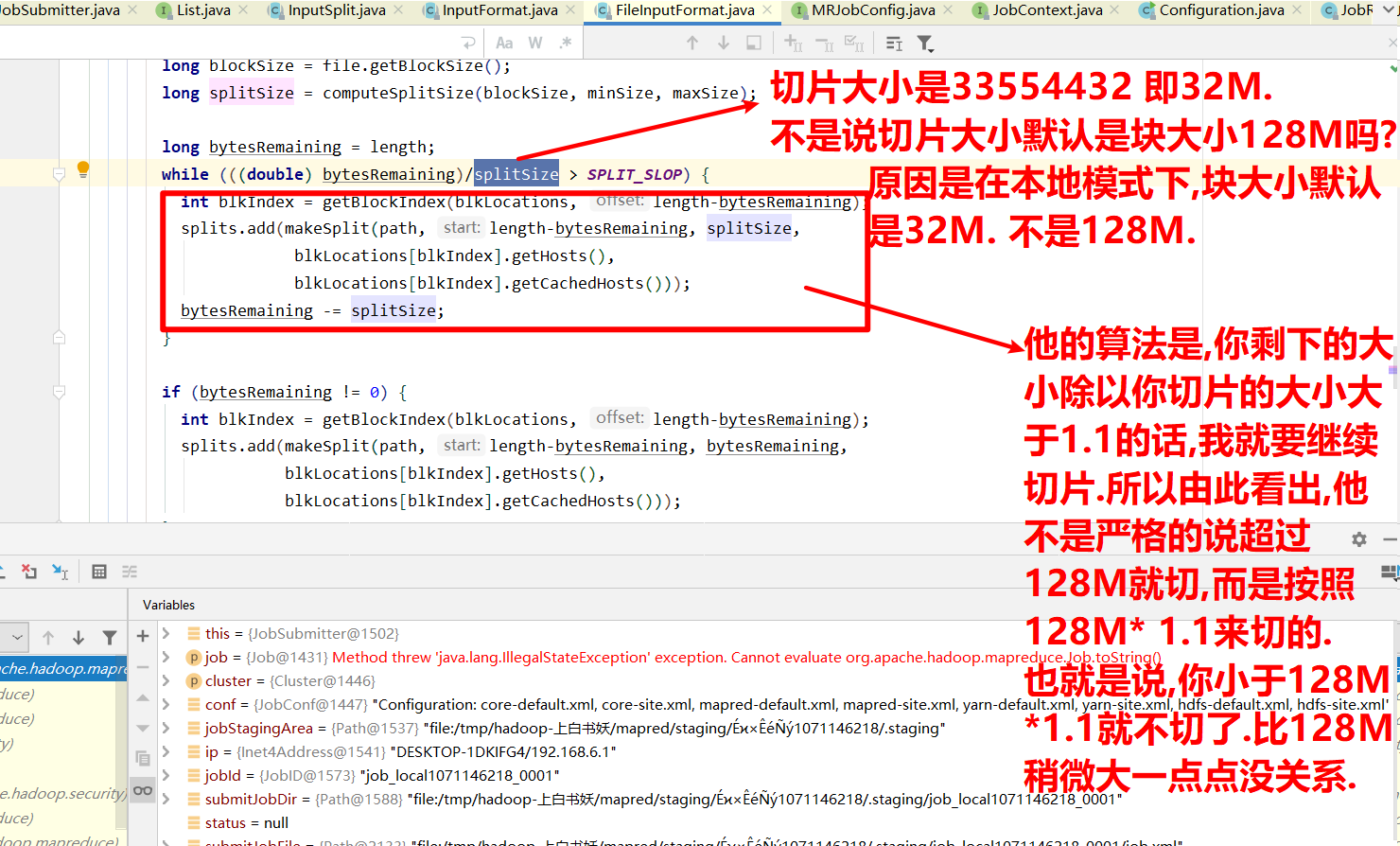
我切片,剩余的长度除以切片大小是大于1.1的,那我就接着去切. 如果是小于等于1.1就不切了,就是一块了. 假如我默认切片大小是128M,但是我的数据块是129M,这样我就不切了吗? 这就要看他是否大于默认切片大小(128M)的1.1倍了. 但是为什么不大于1.1我就不切了呢? 比如说我默认切片大小是32M,那么我32*1.1=35.2M 那就是只要我切片大小<=35.3 我就不切了. 比如说我有一个35.2M的数据,如果说没有这个切片大小<= 默认切片大小的1.1倍就不切的这个公式的话. 而是完全按照32M来切.那我就切出来一个32和一个3.2M的数据.这就是两个切片了. 两个切片将来就需要交给两个mapTask去处理. 那么负责处理32M切片的mapTask是负责3.2M切片的mapTask的数据的10倍. 这就导致一个mapTask负责数据量比较大,另一个负责数据量比较小.这就出现了数据倾斜的问题.
Job提交流程源码和切片源码详解
所谓的Job提交流程就是当我们这个job提交之后,它后续做了哪些事情?
即,我们提交job之后,MapTask执行之前.我们程序都做了什么.
1 | Job提交流程(MapTask执行之前): |
Job提交流程源码详解
1 | waitForCompletion() |
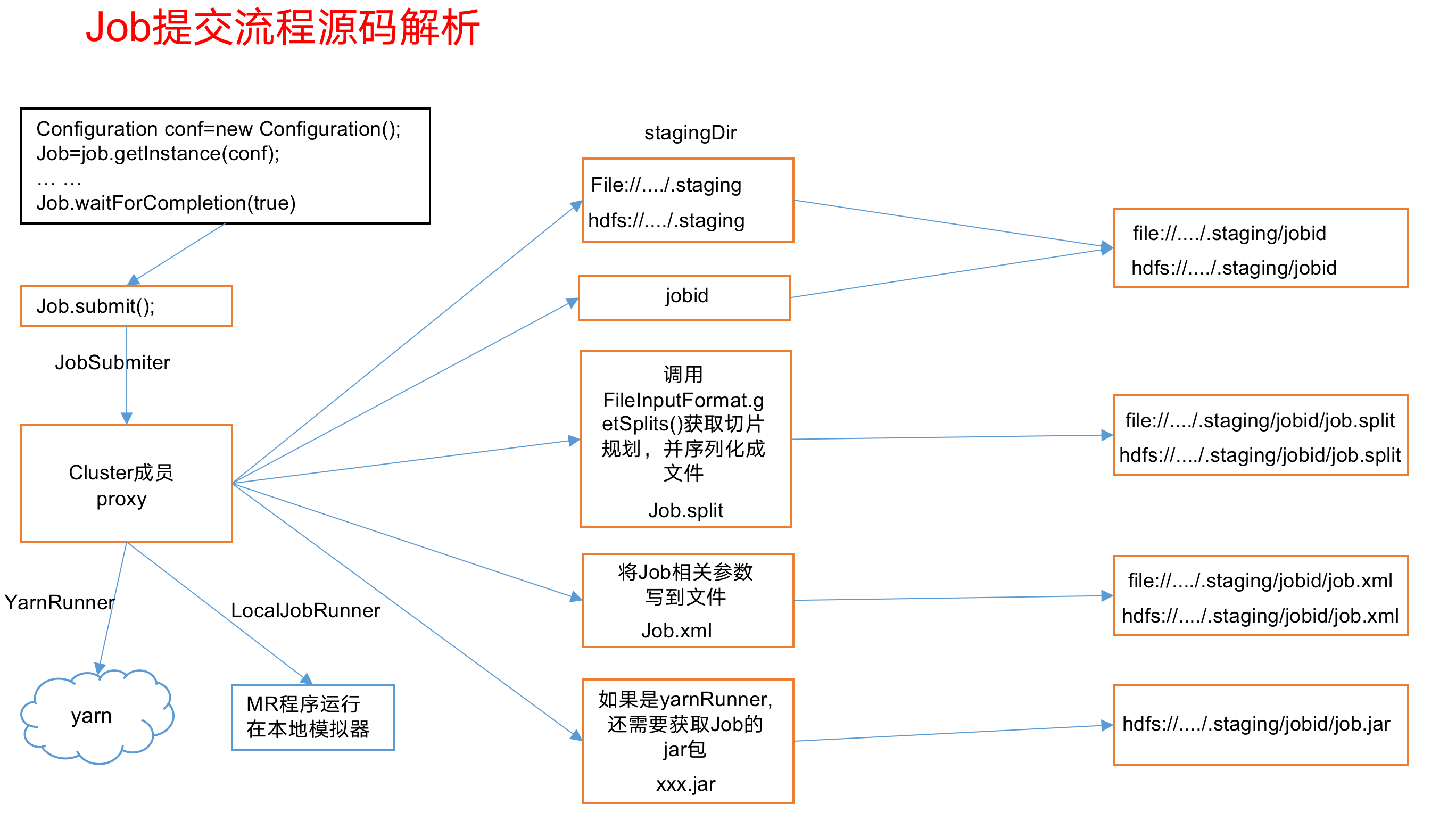
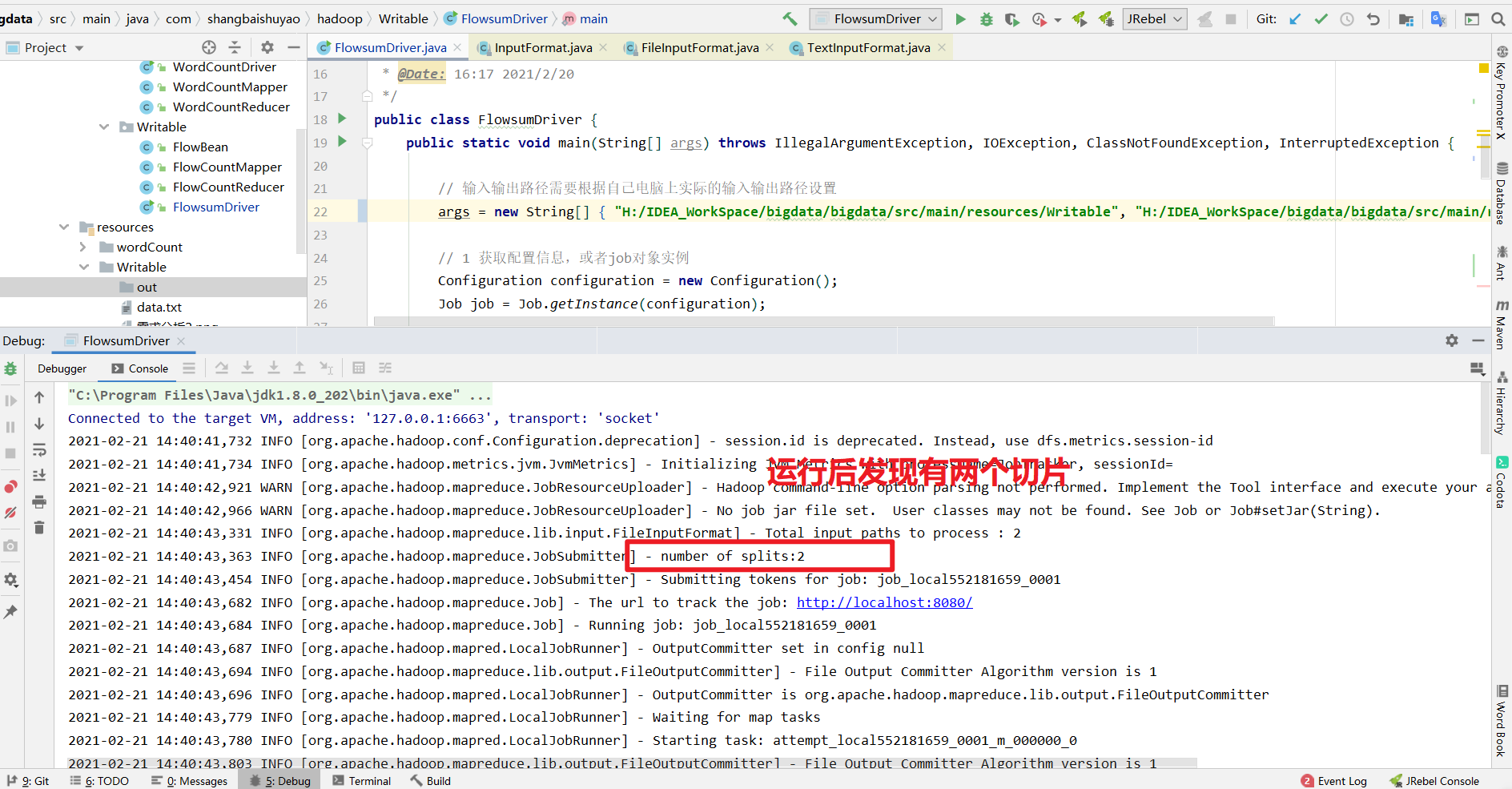
FileInputFormat切片源码解析(input.getSplits(job))
(1)程序先找到你数据存储的目录。
(2)开始遍历处理(规划切片)目录下的每一个文件
(3)遍历第一个文件ss.txt
a)获取文件大小fs.sizeOf(ss.txt)
b)计算切片大小
computeSplitSize(Math.max(minSize,Math.min(maxSize,blocksize)))=blocksize=128M
c)默认情况下,切片大小=blocksize
d)开始切,形成第1个切片:ss.txt—0:128M 第2个切片ss.txt—128:256M 第3个切片ss.txt—256M:300M
(每次切片时,都要判断切完剩下的部分是否大于块的1.1倍,不大于1.1倍就划分一块切片)
e)将切片信息写到一个切片规划文件中
f)整个切片的核心过程在getSplit()方法中完成
g)InputSplit只记录了切片的元数据信息,比如起始位置、长度以及所在的节点列表等。
(4)提交切片规划文件到YARN上,YARN上的MrAppMaster就可以根据切片规划文件计算开启MapTask个数。
FileInputFormat切片机制
1、切片机制
(1)简单地按照文件的内容长度进行切片
(2)切片大小,默认等于Block大小
(3)切片时不考虑数据集整体,一个文件单独切片
2、案例分析
(1)输入数据有两个文件:
filel.txt 320M
file2.txt 10M
(2) 经过FileInputFormat的切片机制运算后,形成的切片信息如下:
filel.txt.split2– 128256320
file1.txt.split3– 256
file2.txt.split1- 0~10M
FileInputFormat切片大小的参数配置
(1)源码中计算切片大小的公式
Math.max(minSize,Math.min(maxSize,blockSize));
mapreduce.input.fileinputformat.split.minsize=1 默认值为1
mapreduce.input.fileinputformat.split.maxsize= Long.MAXValue 默认值Long.MAXValue
因此,默认情况下,切片大小=blocksize。
(2)切片大小设置
maxsize(切片最大值):参数如果调得比blockSize小,则会让切片变小,而且就等于配置的这个参数的值。
minsize(切片最小值):参数调的比blockSize大,则可以让切片变得比blockSize还大。
(3)获取切片信息API
// 获取切片的文件名称
String name = inputSplit.getPath().getName();
// 根据文件类型获取切片信息
FileSplit inputSplit = (FileSplit) context.getInputSplit();
有哪些形式的InputFormat
思考:在运行MapReduce程序时,输入的文件格式包括:基于行的日志文件二进制格式文件、数据库表等。那么,针对不同的数据类型,MapReduce是如何读取这些数据的呢?
针对不容类型,不同场景,我们做一些实现类,自己写代码.
这里有最常见的,写好的实现类.
FileInputFormat 常 见 的 接 口 实 现 类 包 括:
TextInputFormat、KeyValueTextInputFormat、NLineInputFormat、CombineTextInputFormat和自定义InputFormat等。



KeyValueTextInputFormat使用案例
keyValueTextInputFormat他读取文件的时候还是按照行来读取. 但是他读取进来时候如何去切分他, 他只会将文件切分成两份,切完后,左边是key, 右边就是value.
所以我们得带驱动类Driver中设置我们的分割符, 那些是key ,哪些是value.
NLineInputFormat使用案例
NLineInputFormat 表什么呢? N表示数字. Line表示行. 表达的意思是n行的InputFormat. 他是按照你指定的行号进行切片的. 比如说我有一个文件. 我希望你将来对我文件进行处理的时候是每三行, 或者说每四行进行处理. 这个N 是你具体指定的. 就是按照行数来进行切片.
所以NLineInputFormat改变的是你的切片的规则, 比如说我有三十一行数据,n为3表示每三行生成一个切片,最终我三十一行生成11个切片.
CombineTextInputFormat切片机制
如果说我们使用框架默认的TextInputFormat切片机制是对任务按文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个MapTask,这样如果有大量小文件,就会产生大量的MapTask,处理效率极其低下。
比如说我有5个文件, 第一个是1M,第二个是2M,3M,4M,5M. 因为他们都小于我们的块大小128M. 所以说按照单个文件来去切的话, 每个文件都是一个切片, 最终生成5个切片. 且我的每一个切片都是对应一个mapTask, 但是这么小的切片对应我的mapTask不是杀鸡用牛刀吗?它都不值得我去启动一次mapTask.因为你数据量太小了.所以对于小文件来说我就不能使用TextInputFormat了, 我必须对你做一个处理.
比如接下来说的CombineTextInputFormat.
他是用的场景就是小文件过多的情况下.他的思想是什么呢?
首先我们使用CombineTextInputFormat的时候得先设置虚拟存储切片的最大值. 具体设置多大按照实际情况来定. 假如说我把虚拟存储最大值设置为4M ,那么他会根据这个4M进行判断,我这个文件到底要不要去切. 然后最终我怎么去帮你生成切片.所以CombineTextInputFormat也是可以避免数据倾斜问题.

如上图所示:
我们设置虚拟存储的文件大小(setMaxInputSplitSize)为4M. 比如说我们有几个文件(如上图) 这些小文件. 因为我们设置虚拟存储大小是4M. 在虚拟存储过程中有一个算法,就是如果你的文件的大小小于你虚拟存储的最大值(即4M). 那么对于你这个文件来说就将你划分成一块.这一块是虚拟的.不是真正划分的. 但是如果你实际文件大小是大于你设置的文件最大值的(4M) , 但是他又小于两倍的最大值. 即大于4M 小于8M. 在这种情况下我就将你这个文件一分为2. 如上面的两块的2.55M .最后生成最终存储的文件即虚拟文件. 接下来他就按照这个规划帮你进行切片. 生成切片的过程中他会判断你虚拟存储的文件大小是否大于我们设置的值(4M). 如果大于则单独形成一个切片. 如果你虚拟存储的大小不大于4M. 那么他就会和你下一个虚拟存储文件进行合并, 共同形成一个切片. 如上图的1.7M+2.55M 形成一个切片. 最终形成3个切片. 三个切片不会差太多.这就规避了数据倾斜问题.

 “
“
1、应用场景:
CombineTextInputFormat用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个MapTask处理。
2、虚拟存储切片最大值设置
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);// 4m
注意:虚拟存储切片最大值设置最好根据实际的小文件大小情况来设置具体的值。
3、切片机制
生成切片过程包括:虚拟存储过程和切片过程二部分。
自定义InputFormat
在企业开发中,Hadoop框架自带的InputFormat类型不能满足所有应用场景,需要自定义InputFormat来解决实际问题。
自定义InputFormat步骤如下:
(1)自定义一个类继承FileInputFormat。
(2)改写RecordReader,实现一次读取一个完整文件封装为KV。
(3)在输出时使用SequenceFileOutPutFormat输出合并文件。
无论HDFS还是MapReduce,在处理小文件时效率都非常低,但又难免面临处理大量小文件的场景,此时,就需要有相应解决方案。可以自定义InputFormat实现小文件的合并。
比如说我有n多个小文件,我想将他存到HDFS中,之前的一种方式是使用har文件.
但是现在我想把我的n多个小文件最终存到一个文件里面.就是死将这n多个小文件里面的内容拿出来存到一个文件里面,存成一个稍微大一点的文件. 但是我不能简单存成一个txt文件. 因为这样的话就会乱了.就揉到一起了. 我还是希望你存到这大文件里面以后他们之间还是有一个很明确的划分的. 所以这一次我会用到一个SequenceFlie. SequenceFile就是一个序列文件. 这个文件的格式比较特殊. 虽然是一个文件, 但是它里面也是以k,v 的形式来存的. k 可以是原来文件的路径.v是文件的内容 (D:/one.txt , 文件内容 ) . 虽然说我将多个文件存到一个文件当中, 但是这个文件里面他也是有明确的划分的. 将来我们去读的时候也是可以通过 k, v 的形式去读出来. 而且这种格式存起来特别的紧凑. 比如原先我n个小文件存起来是5M, 但是通过 SequenceFile这种方式存的话可能就 3M. 因为他是二进制的存储方式. sequenceFile这种文件的格式hadoop是支持的 , 但是我们得自己操作, 将小文件里面的内容读出来,以 k ,v 的形式给他写进去.这个过程需要我们自己做.所以我在读我们每一个小文件的时候希望一次性将文件里面的内容都读出来然后向sequenceFile中去放. 比如说k 就是我们小文件的路径加名字. v就是我文件的内容. 我一次性将这个k,v 写到sequenceFile中. 但是我们上面的InputFormat没有一次性读整个文件的. 都是一行一行读的. 所以这就需要我们自定义了.
具体案例: 略.
MapReduce工作流程
1.MapReduce工作流程:
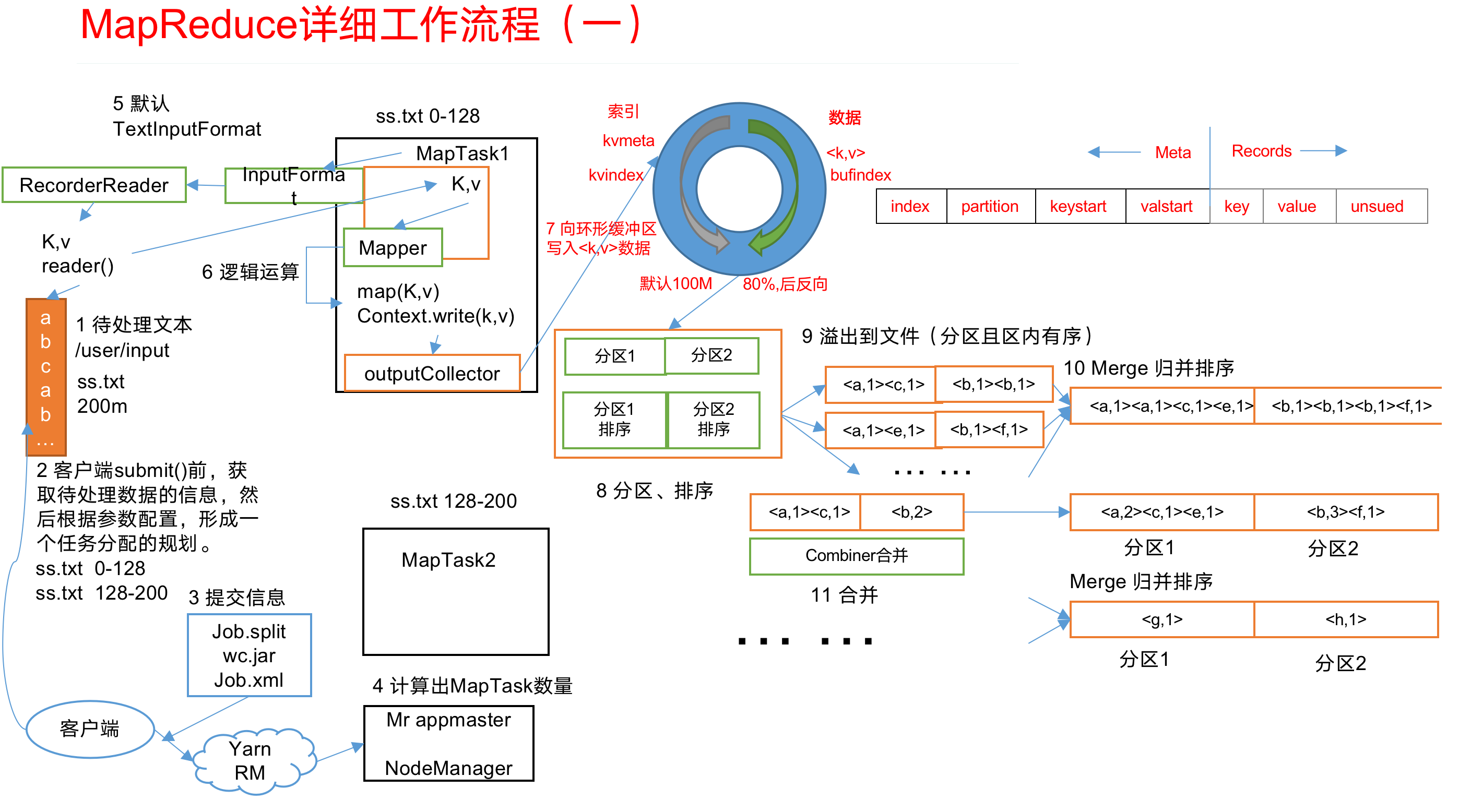 “
“
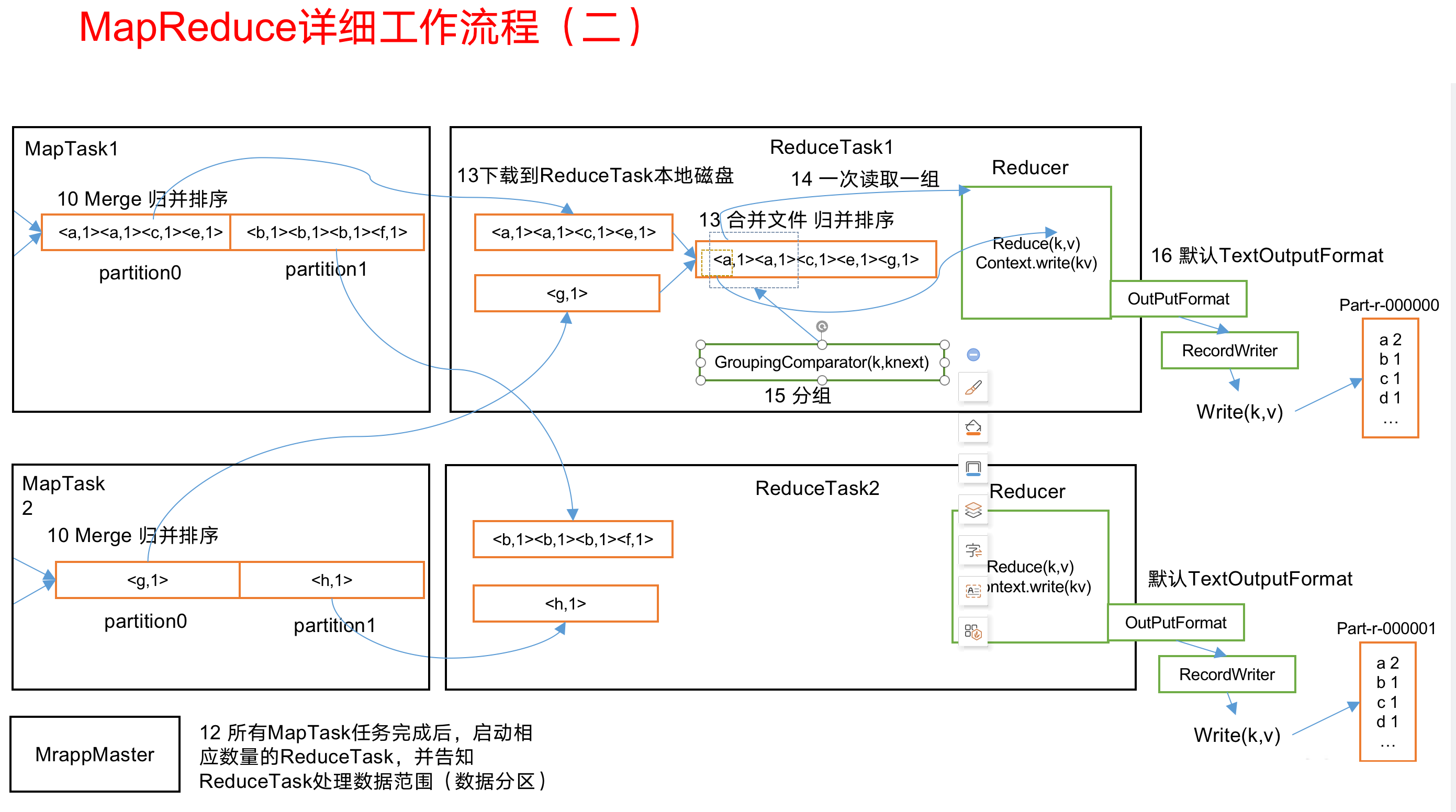
2.流程详解:
1 | 上面的流程是整个MapReduce最全工作流程,但是Shuffle过程只是从第7步开始到第16步结束,具体Shuffle过程详解,如下: |
整个mapreduce分为:
InputFormat数据输入—–>MapTask工作机制,Shuffle工作机制,ReduceTask工作机制—>OutputFormat数据输出.
此篇文章讲解了InputFormat数据输入, 下一篇就是 MapTask工作机制,Shuffle工作机制,ReduceTask工作机制.
Shuffle工作机制比较重要,单独记录. 下一篇是: hadoop组成模块之mapreduce的MapTask机制和reduceTask机制


- 本文作者: xubatian
- 本文链接: http://xubatian.cn/MapReduce框架原理之InputFormat数据输入/
- 版权声明: 本博客所有文章除特别声明外均为原创,采用 CC BY 4.0 CN协议 许可协议。转载请注明出处:https://www.xubatian.cn/
 故人的博客
故人的博客
 IT周的博客
IT周的博客
 大胖胖的笔记
大胖胖的笔记
 常瑞的部落落
常瑞的部落落
 Fortune博客
Fortune博客
 星空下的YZY
星空下的YZY
 BOBL技术博客
BOBL技术博客