

Flink具体如何保证exactly-once呢? 它使用一种被称为”检查点”(checkpoint)的特性,在出现故障时将系统重置回正确状态。下面通过简单的类比来解释检查点的作用。
假设你和两位朋友正在数项链上有多少颗珠子,如下图所示。你捏住珠子,边数边拨,每拨过一颗珠子就给总数加一。你的朋友也这样数他们手中的珠子。当你分神忘记数到哪里时,怎么办呢? 如果项链上有很多珠子,你显然不想从头再数一遍,尤其是当三人的速度不一样却又试图合作的时候,更是如此(比如想记录前一分钟三人一共数了多少颗珠子,回想一下一分钟滚动窗口)。

于是,你想了一个更好的办法: 在项链上每隔一段就松松地系上一根有色皮筋,将珠子分隔开; 当珠子被拨动的时候,皮筋也可以被拨动; 然后,你安排一个助手,让他在你和朋友拨到皮筋时记录总数。用这种方法,当有人数错时,就不必从头开始数。相反,你向其他人发出错误警示,然后你们都从上一根皮筋处开始重数,助手则会告诉每个人重数时的起始数值,例如在粉色皮筋处的数值是多少。
Flink检查点的作用就类似于皮筋标记。数珠子这个类比的关键点是: 对于指定的皮筋而言,珠子的相对位置是确定的; 这让皮筋成为重新计数的参考点。总状态(珠子的总数)在每颗珠子被拨动之后更新一次,助手则会保存与每根皮筋对应的检查点状态,如当遇到粉色皮筋时一共数了多少珠子,当遇到橙色皮筋时又是多少。当问题出现时,这种方法使得重新计数变得简单。
Flink的检查点算法
Flink检查点:
①隔一段时间(程序员设置),由JobManager来触发CheckPoint.
②CheckPoint保存在JobManager内存里面.
保存CheckPoint之后就意味着我们程序有一份快照了.比如source5,sum奇数9,偶数6.保存了
某个子任务挂掉造成整个Job挂掉.重启Job,需要保证状态一致.
一致性分为三种级别: ①最多一次②至少一次③精确一次
如何保证精确一次? 从上一个检查点开始恢复.从source5,sum奇数9,偶数6.开始恢复.
由于你offset是5,那就从5开始重新读.
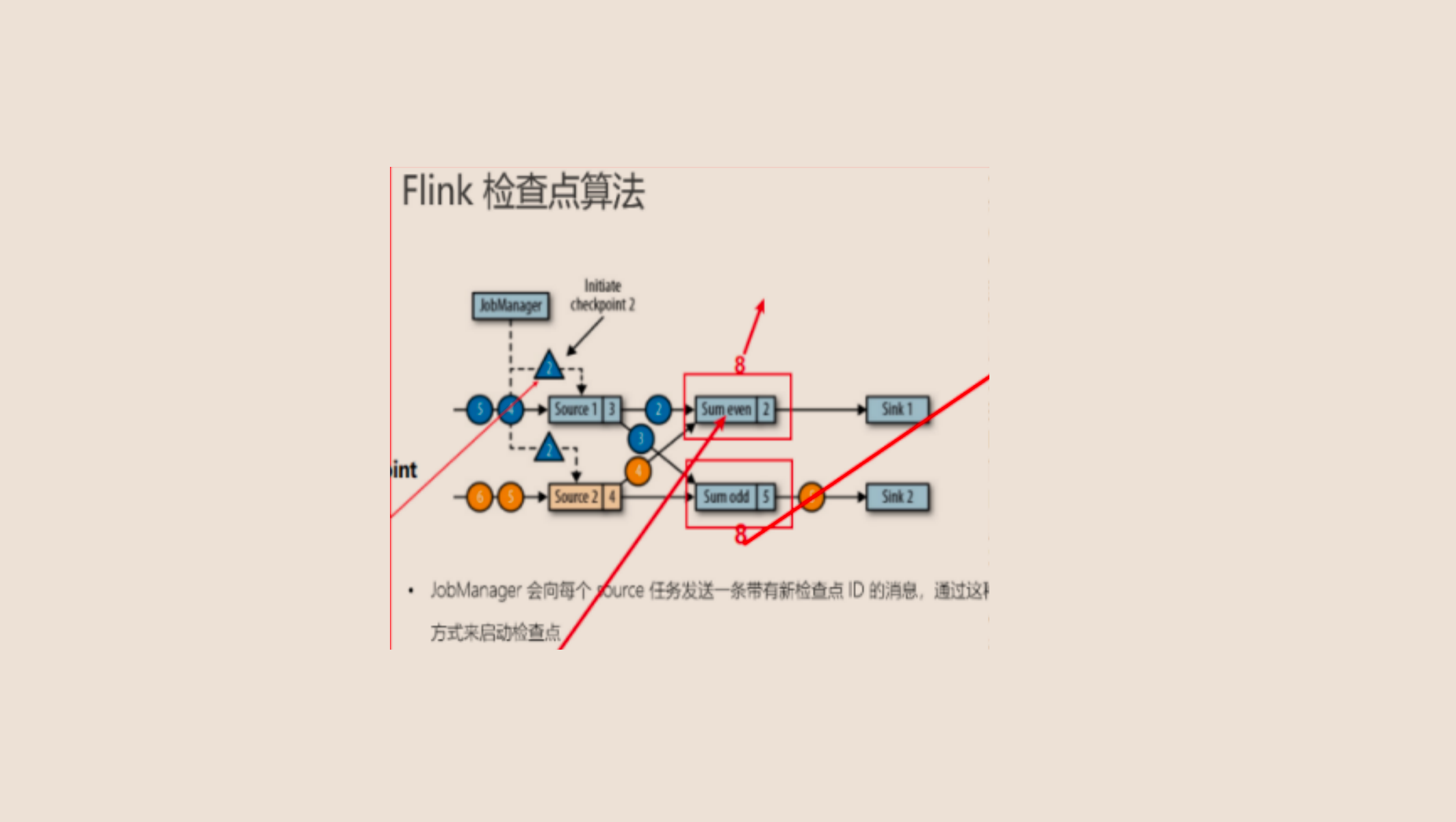
Jobmanger发送Barrier,Barrier里面封装id号, JobManager将barrier发送给每一个source.
只是将Barrier发送到原来source流里面的数据中了.只是将Barrier插入到流里面了.
算子接收到Barrier之后马上进行CheckPoint, 即将Barrier之前的offset保存到CheckPoint中. 保存在哪里呢? 保存在状态中,或者说保存在JobManager的内存中.
接收到Barrier之后,将offset保存到状态中,同时还要将Barrier以广播的形式发送出去.下面的几个节点都发. 下面的节点,如果有个source的情况下, 其中一个算子接收到Barrier之后,这个算子先暂停工作,将barrier后的数据缓存起来, 到了第二个source的Barrier来了之后在进行CheckPoint.即将offset保存到状态中.


①CheckPoint的Barrier检查点机制确实可以做到Flink内部算子的精确一致. 但是无法做到端到端的一致.
如果想要保证端到端的一致就要考虑,source是哪一种source. 比如: source支不支持重置offset. Kafka可以,kafka是支持offset重置的. 如果是kafka, 再结合CheckPoint就能做到end-to-end,即端到端的精确一致.
我们到底把CheckPoint保存在哪里?
checkPoint数据保存在哪里是由状态后端(state backend)的机制决定的.
Flink有三种状态后端.
实际上有两种情况:
没有checkPoint的本地状态保存在TaskManager内存中
CheckPoint之后由TaskManager内存上转移到JobManager内存中.
即Flink的默认状态保存在TaskManager的JVM内存上, 而CheckPoint的状态保存在JobManager的JVM内存 上. 这是默认情况.
第一: memoryStateBackend(内存级状态后端) ,保存内存中, 将键控状态作为内存中的对象进行管理. 一开始键控状态是存储在TaskManager的JVM堆内存中.
因为TaskManager才真正执行任务. 当触发CheckPoint的时候, 他会将键控状态保存到JobManager的JVM内存中. 所以说内存级状态后端是保存在JobManager内存中的.
第二:FsStateBackend(持久化到远程文件系统中,最常用的是HDFS文件系统).
第三:RocksDBStateBackend(RockDB 数据库的状态后端)
我们用是内存级状态后端比较多,虽然存储在状态中不稳定,但是因为我们JobManager使用zookeeper做了高可用.还有另外一台JobManager存放CheckPoint呀.
如果你认为这种还要风险的话,那就使用第二种,存放在文件系统中.
内存级状态后端和文件系统状态状态后端
共同点:
他们的算子状态和键控状态都保存在TaskManager的堆内存上.
不同点:
当触发checkPoint时,内存级状态后端保存在JobManager内存上; 而文件系统状态后端保存在文件系统上.
注意: checkPoint之后,TaskManager内存上的还有状态的, 他不会动原来的状态,只是又存了一份而已. 可以理解为存了两份状态.
但是RockDB状态后端就不保存在TaskManager的内存上了,而是直接保存在RockDB数据库中. RockDB是键值对数据库,类似redis,有Flink自己维护.





总结CheckPoint原理
首先CheckPoint是由JobManager来发起来开始CheckPoint.由他来发起的话,他就将Barrier发到流里面去.把Barrier发给流.比如:如果当且这个Barrier就插在3的后面4的前面. 而且所有的流都可以插.所以这里暂时不用考虑两个流的情况.因为两个流和一个流实际上是一样的.如下图:
直接当Source2不存在就可以了.然后我们也暂时不考虑分组.就直接每一个数据我们做聚合累加.就做这么一个简单的事情.我们就先将一下这个简单的过程.将他讲清楚.如下图:
现在我们是这种情况:我们不做奇偶的分组了.而是来一个数据就累加,来一个数据就累加.所以这个sum直接做累加.他不是什么累加偶数,累加奇数什么的.而是来一条数据就累加,来一条数据就累加.
假设JobManager触发了一个CheckPoint,然后他就把这个三角形的Barrier插到数据里面去即插到流里面去.source1呢,刚刚把3收到了.并且把3发出去了.假设把3发出去了.这个之后就收到了一个三角形即Barrier了.
收到这个三角形(Barrier)之后呢,马上把当前状态中保存的Offset,再把它保存到CheckPoint里面去.实际上就是把这个Offset保存到CheckPoint里面.
保存完了之后,他需要做两件事情.
第一件事情就是把Barrier往外广播.往下一步广播.
第二件事情就是告诉通知我们的JobManager,我当前Source的这个CheckPoint结束了.
然后由于他往外广播了,那这个barrier可能是不是又被这个Sum 算子收到了呢?(sum even )那么请问这个Sum算子收到的Barrier一定是在那一条数据后面才能收到的.因为这里不考虑奇偶,所以一定是在3后面才能收到.所以,一开始他收到3的时候他直接做累加.1+2+3=6所以他的状态就是6.如下图所示:
因为3进来之后就是1+2+3=6 ,所以状态就是6. 收到3之后马上是不是收到一个Barrier呀.收到Barrier之后.他把这个6(这个6本来就在状态里面了)
也是CheckPoint一下.保存到我们的状态后端.然后也是一样.做两件事情.第一件事情:对外广播.第二件事情:通知我的JobManager,我的Sum聚合算子完成了CheckPoint.
那这里可能会有疑问,就是这个sum这个节点正在做CheckPoint的时候这个source1又有数据来了,即4过来了.4来了怎么办呢?
他会把这个4缓存起来.因为我这个CheckPoint还没有做完,所以他把4缓存起来.缓存到哪里呢?缓存到map集合中.那么这个map集合保存到哪里呢?当然是保存到JVM的内存里面.除非这个sum节点的CheckPoint完成了.完成之后呢.他就会从缓存中去把4读进来,再次做聚合.做4的聚合.那你可能会问,这时候5也来了呀?他是按照队列来的,先拿4,再拿5. 5那完之后再次从source里面拿下一个.以此类推.那接下来开始 写到sink里面.写到Sink他也是一样的.他也是按照上面所说的这个过程.一直到所有的节点CheckPoint都完成了最后一次通知我这个JobManager之后,如下图:
最后一次通知我这个JobManager之后.我这个JobManager就知道了,整个过程的CheckPoint就已经结束了.也就是说,ID为2的这个CheckPoint就已经结束了.就是这么一个过程.所以两条流和一条流实际上都是一样的.
Flink检查点的核心作用是确保状态正确,即使遇到程序中断,也要正确。记住这一基本点之后,我们用一个例子来看检查点是如何运行的。Flink为用户提供了用来定义状态的工具。例如,以下这个Scala程序按照输入记录的第一个字段(一个字符串)进行分组并维护第二个字段的计数状态。
1 | val stream: DataStream[(String, Int)] = ... |
该程序有两个算子: keyBy算子用来将记录按照第一个元素(一个字符串)进行分组,根据该key将数据进行重新分区,然后将记录再发送给下一个算子: 有状态的map算子(mapWithState)。map算子在接收到每个元素后,将输入记录的第二个字段的数据加到现有总数中,再将更新过的元素发射出去。下图表示程序的初始状态: 输入流中的6条记录被检查点分割线(checkpoint barrier)隔开,所有的map算子状态均为0(计数还未开始)。所有key为a的记录将被顶层的map算子处理,所有key为b的记录将被中间层的map算子处理,所有key为c的记录则将被底层的map算子处理。
图 按key累加计数程序初始状态
上图是程序的初始状态。注意,a、b、c三组的初始计数状态都是0,即三个圆柱上的值。ckpt表示检查点分割线(checkpoint barriers)。每条记录在处理顺序上严格地遵守在检查点之前或之后的规定,例如[“b”,2]在检查点之前被处理,[“a”,2]则在检查点之后被处理。
当该程序处理输入流中的6条记录时,涉及的操作遍布3个并行实例(节点、CPU内核等)。那么,检查点该如何保证exactly-once呢?
检查点分割线和普通数据记录类似。它们由算子处理,但并不参与计算,而是会触发与检查点相关的行为。当读取输入流的数据源(在本例中与keyBy算子内联)遇到检查点屏障时,它将其在输入流中的位置保存到持久化存储中。如果输入流来自消息传输系统(Kafka),这个位置就是偏移量。Flink的存储机制是插件化的,持久化存储可以是分布式文件系统,如HDFS。下图展示了这个过程。
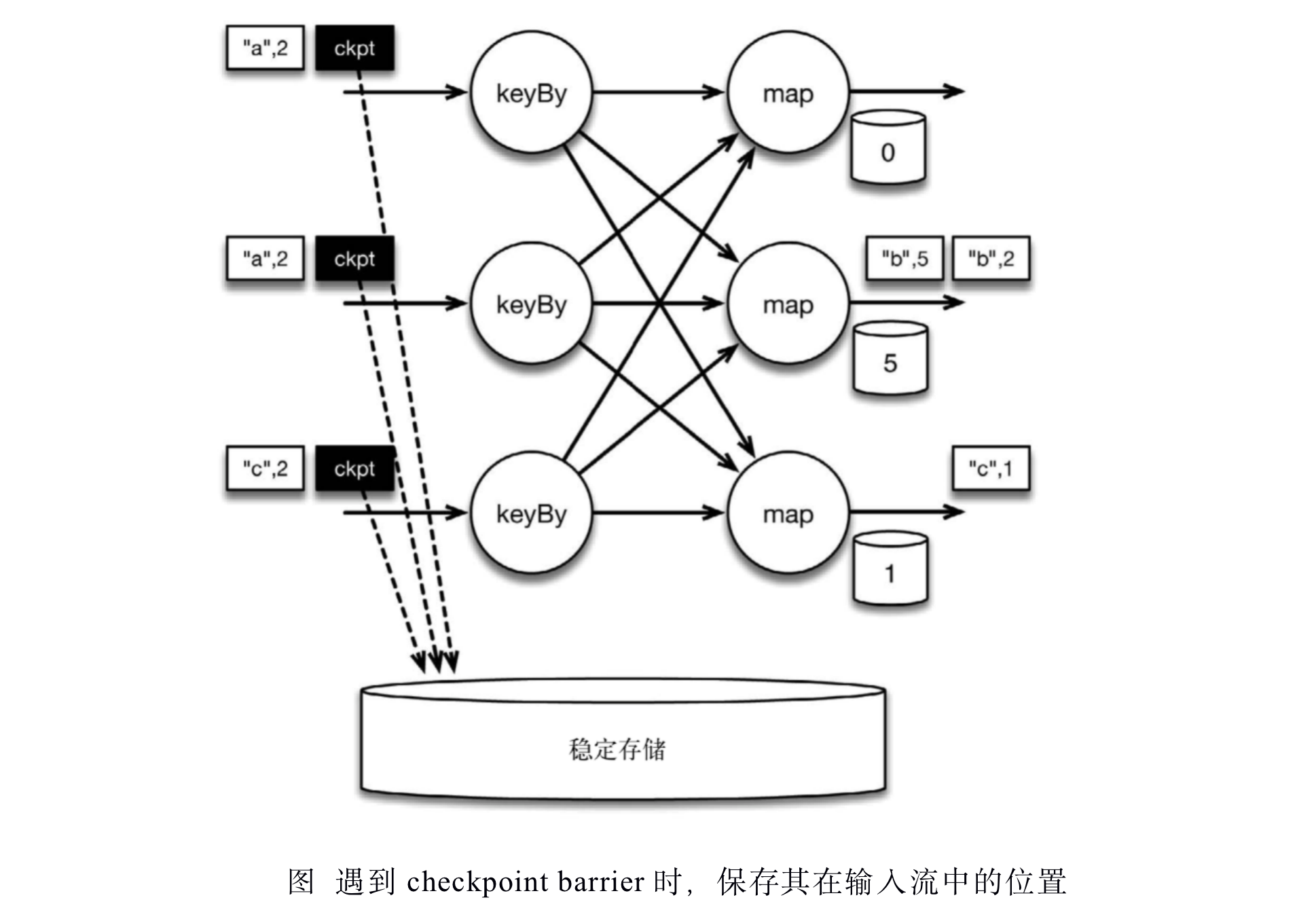
当Flink数据源(在本例中与keyBy算子内联)遇到检查点分界线(barrier)时,它会将其在输入流中的位置保存到持久化存储中。这让 Flink可以根据该位置重启。
检查点像普通数据记录一样在算子之间流动。当map算子处理完前3条数据并收到检查点分界线时,它们会将状态以异步的方式写入持久化存储,如下图所示
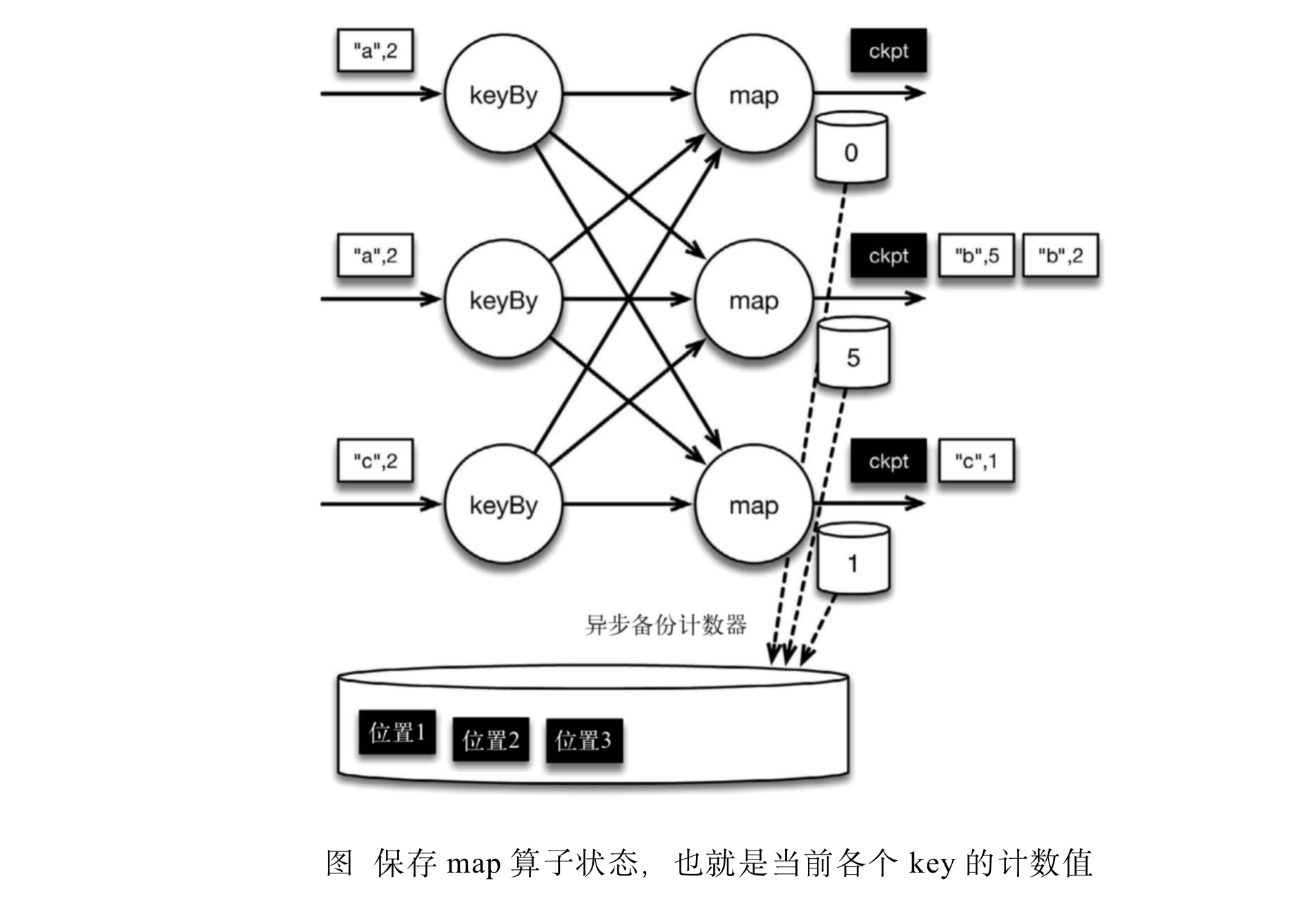
位于检查点之前的所有记录([“b”,2]、[“b”,3]和[“c”,1])被map算子处理之后的情况。此时,持久化存储已经备份了检查点分界线在输入流中的位置(备份操作发生在barrier被输入算子处理的时候)。map算子接着开始处理检查点分界线,并触发将状态异步备份到稳定存储中这个动作。
当map算子的状态备份和检查点分界线的位置备份被确认之后,该检查点操作就可以被标记为完成,如下图所示。我们在无须停止或者阻断计算的条件下,在一个逻辑时间点(对应检查点屏障在输入流中的位置)为计算状态拍了快照。通过确保备份的状态和位置指向同一个逻辑时间点,后文将解释如何基于备份恢复计算,从而保证exactly-once。值得注意的是,当没有出现故障时,Flink检查点的开销极小,检查点操作的速度由持久化存储的可用带宽决定。回顾数珠子的例子: 除了因为数错而需要用到皮筋之外,皮筋会被很快地拨过。
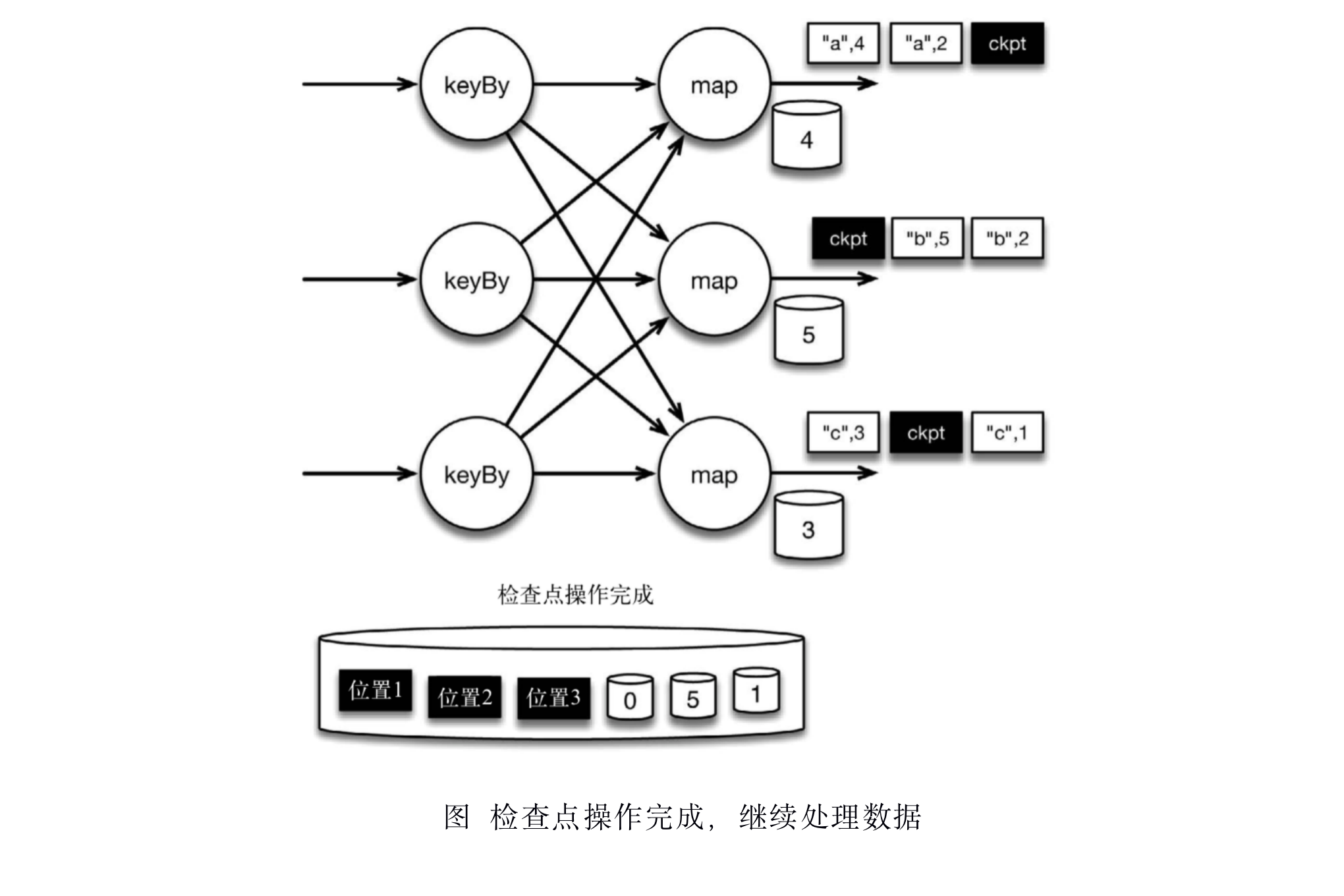
检查点操作完成,状态和位置均已备份到稳定存储中。输入流中的所有数据记录都已处理完成。值得注意的是,备份的状态值与实际的状态值是不同的。备份反映的是检查点的状态。
如果检查点操作失败,Flink可以丢弃该检查点并继续正常执行,因为之后的某一个检查点可能会成功。虽然恢复时间可能更长,但是对于状态的保证依旧很有力。只有在一系列连续的检查点操作失败之后,Flink才会抛出错误,因为这通常预示着发生了严重且持久的错误。
现在来看看下图所示的情况: 检查点操作已经完成,但故障紧随其后。
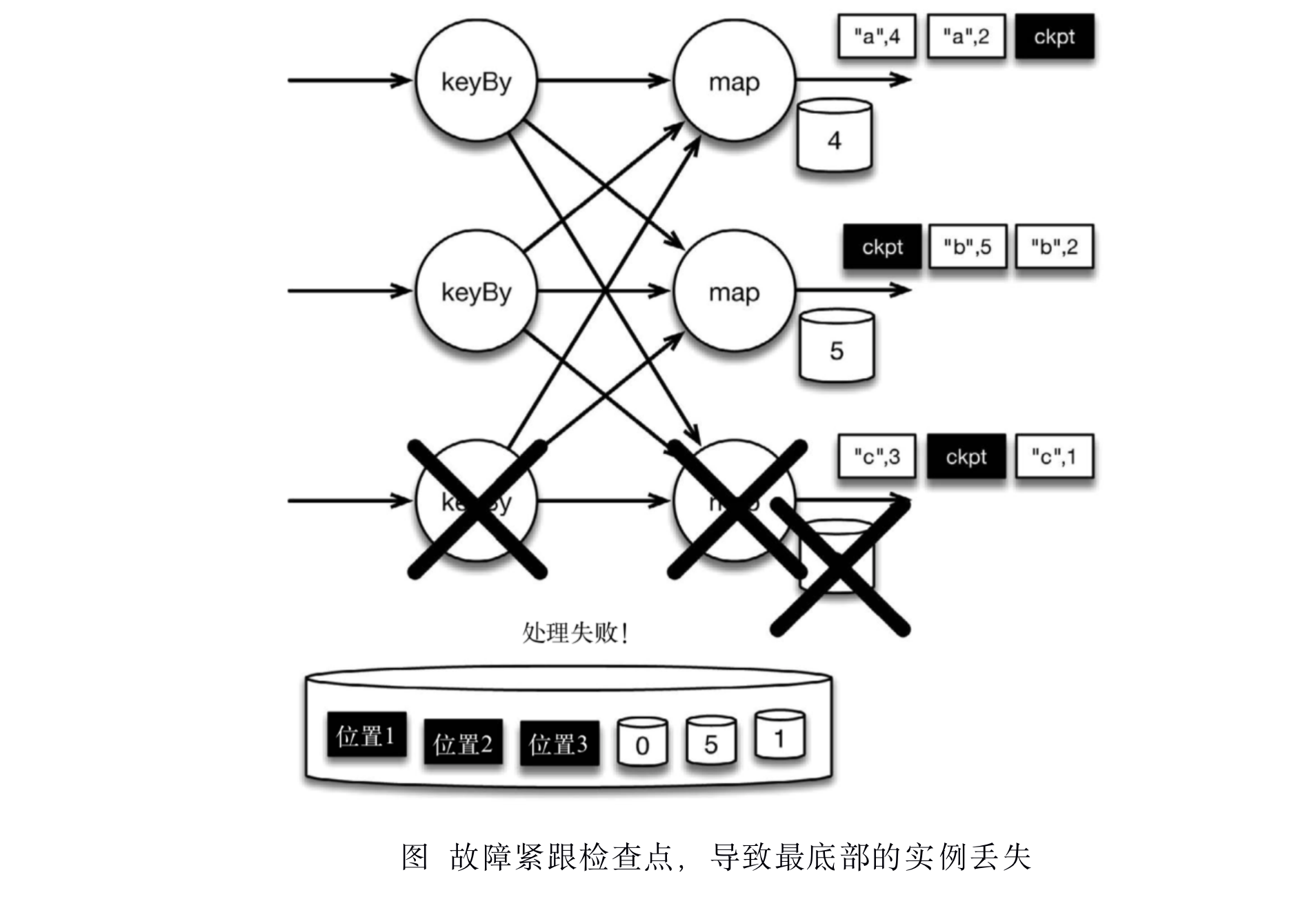
在这种情况下,Flink会重新拓扑(可能会获取新的执行资源),将输入流倒回到上一个检查点,然后恢复状态值并从该处开始继续计算。在本例中,[“a”,2]、[“a”,2]和[“c”,2]这几条记录将被重播。
下图展示了这一重新处理过程。从上一个检查点开始重新计算,可以保证在剩下的记录被处理之后,得到的map算子的状态值与没有发生故障时的状态值一致。

Flink将输入流倒回到上一个检查点屏障的位置,同时恢复map算子的状态值。然后,Flink从此处开始重新处理。这样做保证了在记录被处理之后,map算子的状态值与没有发生故障时的一致。
Flink检查点算法的正式名称是异步分界线快照(asynchronous barrier snapshotting)。该算法大致基于Chandy-Lamport分布式快照算法。
检查点是Flink最有价值的创新之一,因为它使Flink可以保证exactly-once,并且不需要牺牲性能。


- 本文作者: xubatian
- 本文链接: http://xubatian.cn/Flink-原理与实现-Flink的状态编程和容错机制之检查点(checkpoint)/
- 版权声明: 本博客所有文章除特别声明外均为原创,采用 CC BY 4.0 CN协议 许可协议。转载请注明出处:https://www.xubatian.cn/
 故人的博客
故人的博客
 IT周的博客
IT周的博客
 大胖胖的笔记
大胖胖的笔记
 常瑞的部落落
常瑞的部落落
 Fortune博客
Fortune博客
 星空下的YZY
星空下的YZY
 BOBL技术博客
BOBL技术博客