

附录算子俯瞰图:
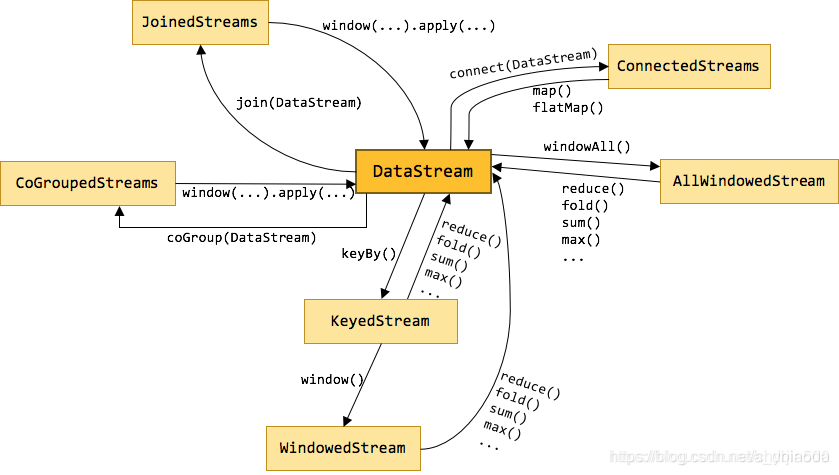
TimeWindow(时间窗口)
时间窗口有三种:滚动窗口,滑动窗口, 会话窗口
TimeWindow是将指定时间范围内的所有数据组成一个window,一次对一个window里面的所有数据进行计算。
注意:timeWindow函数必须在keyBy之后,timeWindowAll则不需要
不管你是三种窗口中的哪一种,如果你的窗口函数的后面没有加All的话,那就是基于我们的keyedStream的,加了All就是基于我们的DataStream的.
1.滚动窗口(Tumbling Window)
Flink默认的时间窗口根据Processing Time 进行窗口的划分,将Flink获取到的数据根据进入Flink的时间划分到不同的窗口中
1 | val minTempPerWindow = dataStream |
注意:
滚动窗口一定要在keyBy之后去调用.keyBy之后调用的话,由于它是滚动窗口.我们只需要传一个参数,就是窗口的长度就可以了.
如果你仔细想的话,你发现有一个问题: 就是假设我窗口的长度为15秒,那么当前某一个窗口他的起始的时间是怎么算的?是不是就是把你当前的时间除以15呀.直接除以15取模,取模之后的到一个什么?

时间间隔可以通过Time.milliseconds(x)毫秒,Time.seconds(x)秒,Time.minutes(x)分钟,等其中的一个来指定。
TimeWindow()实际上就是设置我们的窗口.窗口设置好之后,要么做聚合要么做其他操做,一般来说就是做聚合.
2.滑动窗口(SlidingEventTimeWindows)
滑动窗口和滚动窗口的函数名是完全一致的,只是在传参数时需要传入两个参数,一个是window_size,一个是sliding_size。
下面代码中的sliding_size设置为了5s,也就是说,窗口每5s就计算一次,每一次计算的window范围是15s内的所有元素。
1 | val minTempPerWindow: DataStream[(String, Double)] = dataStream |
时间间隔可以通过Time.milliseconds(x),Time.seconds(x),Time.minutes(x)等其中的一个来指定。

CountWindow(计数窗口)
**CountWindow(计数窗口)**也有所谓的滚动窗口和滑动窗口,但是他只有这两个,没有所谓的会话窗口
CountWindow根据窗口中相同key元素的数量来触发执行,执行时只计算元素数量达到窗口大小的key对应的结果。
注意:CountWindow的window_size指的是相同Key的元素的个数,不是输入的所有元素的总数。
1.滚动窗口(Tumbling Window)
默认的CountWindow是一个滚动窗口,只需要指定窗口大小即可,当元素数量达到窗口大小时,就会触发窗口的执行。
1 | val minTempPerWindow: DataStream[(String, Double)] = dataStream |
2.滑动窗口(SlidingEventTimeWindows)
滑动窗口和滚动窗口的函数名是完全一致的,只是在传参数时需要传入两个参数,一个是window_size,一个是sliding_size。
下面代码中的sliding_size设置为了2,也就是说,每收到两个相同key的数据就计算一次,每一次计算的window范围是5个元素。
1 | val keyedStream: KeyedStream[(String, Int), Tuple] = dataStream.map(r => (r.id, r.temperature)).keyBy(0) |
window function(窗口函数)
window function(窗口函数) : 这里面有增量聚合函数和全窗口函数
window function 定义了要对窗口中收集的数据做的计算操作,主要可以分为两类:
1.增量聚合函数(incremental aggregation functions)
每条数据到来就进行计算,保持一个简单的状态。典型的增量聚合函数有ReduceFunction, AggregateFunction。
2.全窗口函数(full window functions)
先把窗口所有数据收集起来,等到计算的时候会遍历所有数据。
ProcessWindowFunction和ProcessAllWindowFunction就是一个全窗口函数。
Apply也是全量的.
其它可选API
.trigger() —— 触发器
定义 window 什么时候关闭,触发计算并输出结果
.evitor() —— 移除器
定义移除某些数据的逻辑
.allowedLateness() —— 允许处理迟到的数据
.sideOutputLateData() —— 将迟到的数据放入侧输出流
.getSideOutput() —— 获取侧输出流
什么叫允许处理迟到的数据?
这个时候就得考虑,我们的开窗的规则.他到底是按照什么时间来确定的.如果你开窗的规则不是按照执行时间,而是按照数据生成的时间.那就有可能出现所谓迟到的数据.举例:假设我数据的产生是在2:05分产生的.产生数据之后通过kafka再到我们的flink里面.中间是不是有一个过程呀?中间可能隔离一分钟等时间.然后到了我们的FlinkJob里面之后,Flink Job默认情况下他不是探讨你的数据生成的时间,而是探讨执行时间.执行时间肯定是按照顺序来的.但有没有可能是2:05产生的数据先来,下一条数据是2:04分生成的数据呢?当然有可能.所以假设以后要做这个流处理,要严格按照这个数据的生成时间,那这个时候就会出现所谓的迟到的数据.比如说2:05分的数据来了之后发现2:04分的数据还没来.他是真正执行完之后可能下一个窗口才来.那这个就叫所谓的迟到的数据.如果你要严格按照时间顺序的话,你就需要将2:05分的数据等一下.就要想办法让2:04分的这个迟到的数据放到2:05分的数据之前处理.那有什么解决办法呢?

**这三个操作就是其中一个解决方法.就是把迟到的数据单独放到一个分支流数据中.叫侧输出流.放到侧输出流中,我们还得取到侧输出流中的数据.这就是一个不太好的办法.**这个实际上也没法做到实时性.而且你也不知道到底哪个是迟到的数据.什么样的数据才算做迟到的数据.没有一个标准.所以这种处理迟到数据的办法不是最好的.只是他是其中一种.当然还有其他的一些参数,这里只介绍到这里.



- 本文作者: xubatian
- 本文链接: http://xubatian.cn/Flink-原理与实现-Flink中的Window-API/
- 版权声明: 本博客所有文章除特别声明外均为原创,采用 CC BY 4.0 CN协议 许可协议。转载请注明出处:https://www.xubatian.cn/
 故人的博客
故人的博客
 IT周的博客
IT周的博客
 大胖胖的笔记
大胖胖的笔记
 常瑞的部落落
常瑞的部落落
 Fortune博客
Fortune博客
 星空下的YZY
星空下的YZY
 BOBL技术博客
BOBL技术博客