

Flink的状态编程概述
在我们的Flink中,他默认就是有状态的.他和spark的一个本质的区别.有状态,但是他的状态是如何分布的呢?
状态分为两类: 算子状态(operator state)和键控状态(keyed state)
算子状态:
是由Flink每一个子任务自己把任务运行过程中的一些业务或者逻辑或者数据,由自己来保存的或者说由自己来管理的,这样的状态称为算子状态.
所以算子状态的作用范围是限定为当前的算子任务的.
什么叫算子任务啊?
比如如下图:
如图所示: sum()就是一个算子.这个算子里面在真正运行的过程中要看你这里写的并行度是多少.假设我这里定义的并行度setParallelism(2)是2.如图所示:

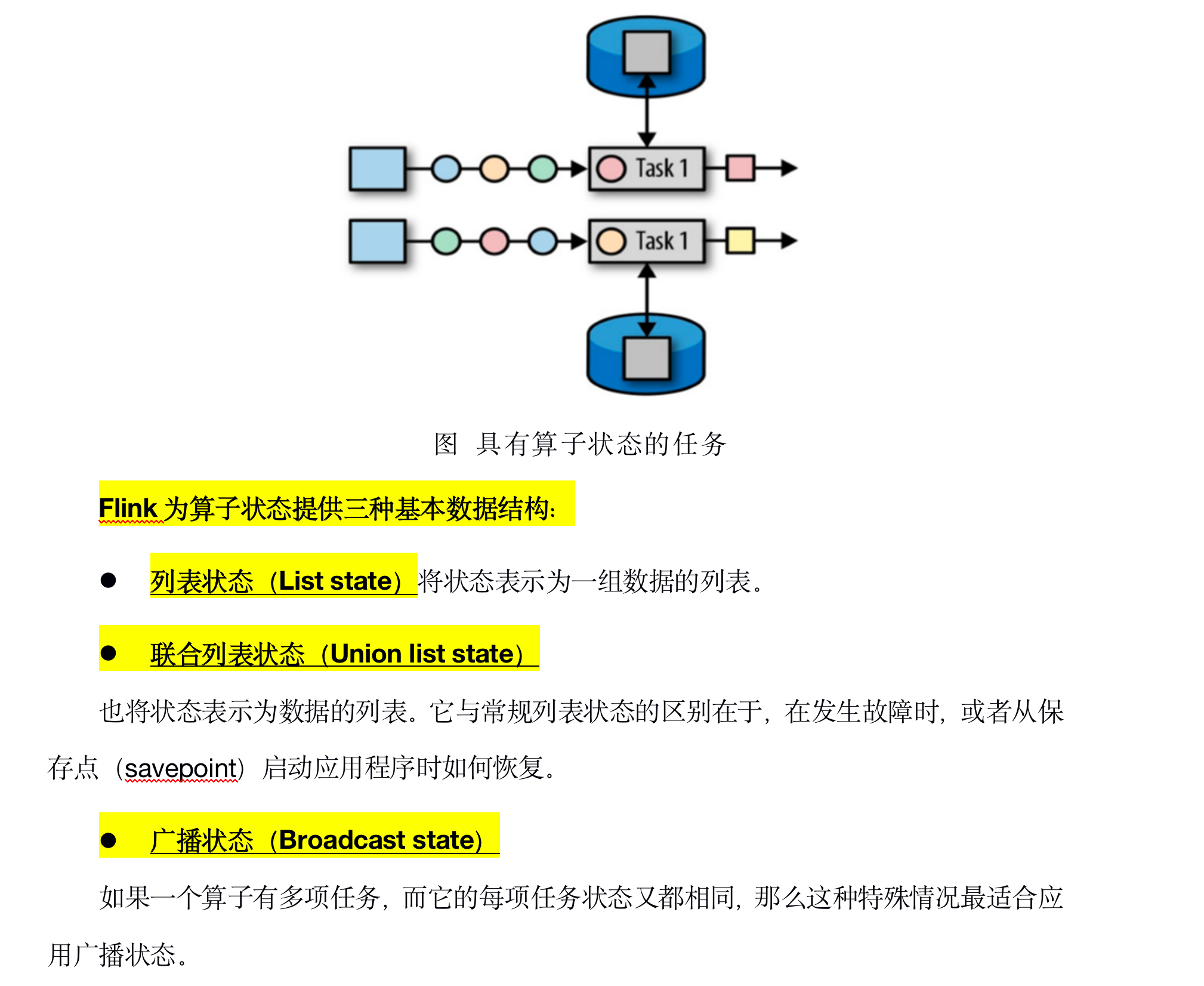
如图所示:图上这句话的意思就是表示,我的这个sum()算子他有两个子任务.因为他有两个并行度.所以他就有两个子任务.这意味着由同一并行任务所处理的所有数据都可以访问到相同的状态,状态对于同一任务而言是共享的。但是算子状态不能由相同或不同算子的另一个任务访问。这是什么意思呢?如下图所以:就以下图sum()为例,因为我们知道下图这个sum()一定是用到状态了.

如图所示: 如果我给这个sum()的并行度设置为2.就意味着这个sum()这个算子有两个subtask即子任务.他是这样子的: 就是他每一个subtask(子任务)都有各自所管理的算子状态.
就算你这两个subtask(子任务)都属于同一个算子.他也是不能够相互访问的.他是不能访问另外一个的.所以所谓的作用范围其实就是限定当前算子的子任务的.如下图所示:

而我们这样的算子状态呢,他有三种基本数据的存储结构.这所说的是算子管理的这些状态有三个存储方式.
第一种是列表状态(List state):就是说我们的算子状态中的数据是使用列表的方式.是存在一个列表里面的.把整个算子的所有数据以一组列表的方式存储起来.
第二种是联合列表状态(Union List State):他也是以列表来存放算子状态的所有的数据.他和前面列表状态的区别是: 在发生故障时,或者从保存点启动应用程序去恢复数据的时候,他的运行代码不同.
第三种是广播状态(Broadcast state):广播状态的意思就是说.我现在有一个算子.这个算子里面呢,他有一些数据或者说有一些逻辑,这个逻辑呢,其他的算子也是会用得到这个逻辑的.或者说这个数据,其他的算子也会用得到.那怎么办呢? 我们前面讲过,算子和算子之间的任务是不能共享的.这个时候呢,我们可以把这个状态存为一种广播状态,存为广播状态的话,这种情况下,他会把状态数据往其他的子任务上去发.这样的话,其他任务上也会有这个所谓的状态数据了.
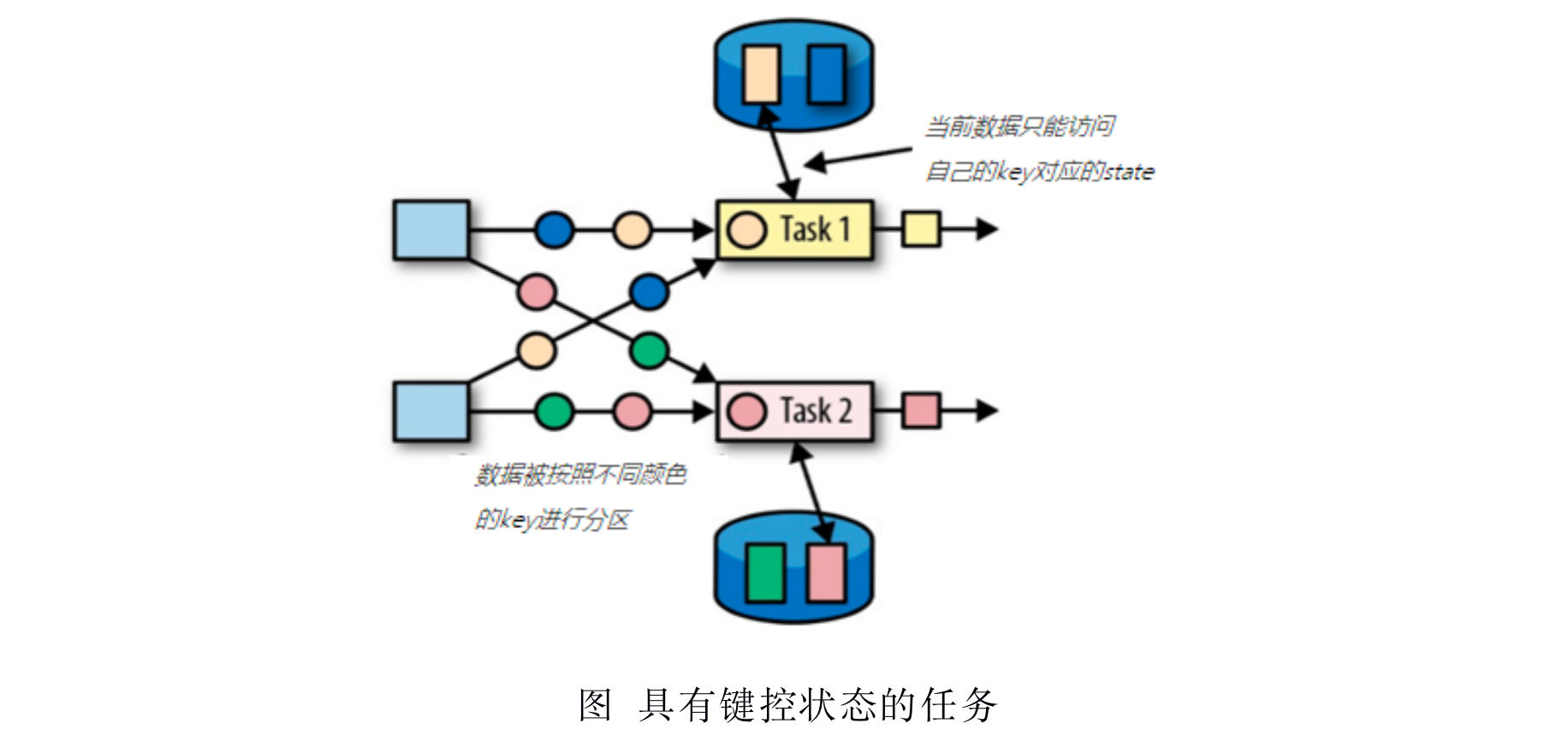
不管怎么说,这个算子状态一般情况下是不能由程序员来控制的.(这个我们只需要知道就OK了). 而真正能由程序员控制的状态是键控状态(Keyed state),所谓键控状态(Keyed State)就是说我们这个状态只会依赖于数据中的键来进行维护和存储的.这种称之为键控状态.那我们马上就想到,我们sum()这个算子里面存的每一个单词,存的每一个单词里面的数据,实际上就是一种键控状态.如图所示:

因为他是根据数据流中定义的键来进行维护和管理的,那我们访问的时候也是根据键来进行访问.Flink为每一个键值维护一个状态实例,让你每次可以修改或者你可以根据键去访问,当然删除实际上也是可以删除,删除实际上我们调用一下clear()就可以了.这样的一个键控状态(Keyed state )的数据有点类似于一个分布式的键值对(keyed-value)的map数据结构.为什么叫分布式的呢?因为我们有很多并行度,每个并行度很有可能一直在多个不同的slot上运行.slot是一个线程.那么这个slot这个线程所在的JVM里面就会保存这个状态信息.保存这个键控状态(Keyed state)的值.键控状态的值是以键值对进行存储的. 你的键就是你数据中定义的那个键. 你这个键在某一个JVM中存放了,他有可能还会在另外一个TaskManager的JVM上再存一个吗? 不会的.所以,其他的TaskManager上所存放的这些状态是可能有其他的键.那么对整个集群而言就是一个分布式的Key-Value数据结构.而且是惟一的Key.就算是分布式的也是一个唯一的Key.刚才我们已经说了,一个key他只会在某一台TaskManager上的JVM所管理的内存里面存放的.至于这个数据存放,后面会说.
当然,我们的Key-Value(键控状态)也是有所谓的数据结构的.它存储的数据结构呢有这么几种:


流式计算分为无状态和有状态两种情况。无状态的计算观察每个独立事件,并根据最后一个事件输出结果。例如,流处理应用程序从传感器接收温度读数,并在温度超过90度时发出警告。有状态的计算则会基于多个事件输出结果。以下是一些例子。
所有类型的窗口。例如,计算过去一小时的平均温度,就是有状态的计算。
所有用于复杂事件处理的状态机。例如,若在一分钟内收到两个相差20度以上的温度读数,则发出警告,这是有状态的计算。
流与流之间的所有关联操作,以及流与静态表或动态表之间的关联操作,都是有状态的计算。
下图展示了无状态流处理和有状态流处理的主要区别。无状态流处理分别接收每条数据记录(图中的黑条),然后根据最新输入的数据生成输出数据(白条)。有状态流处理会维护状态(根据每条输入记录进行更新),并基于最新输入的记录和当前的状态值生成输出记录(灰条)。
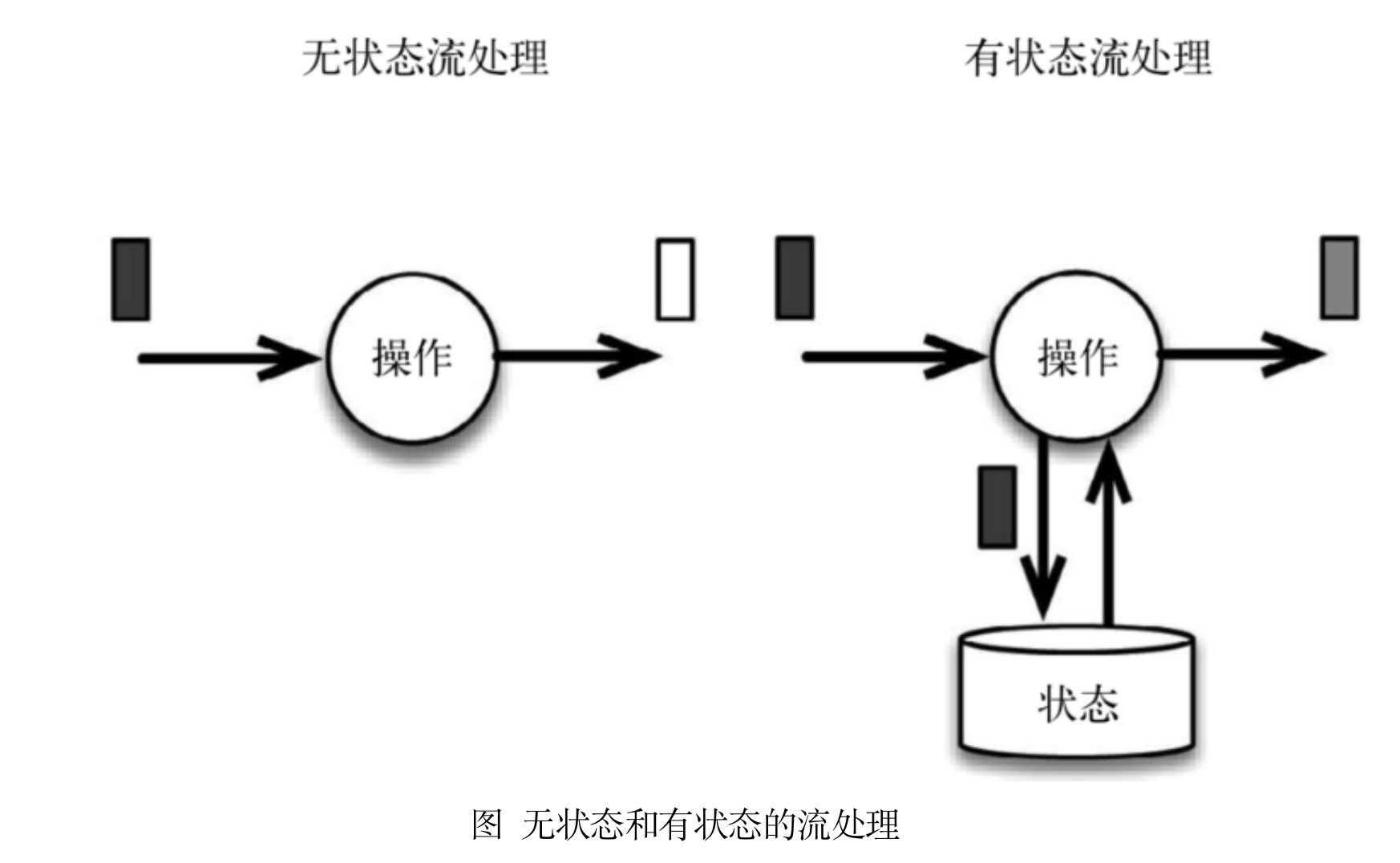
上图中输入数据由黑条表示。无状 态流处理每次只转换一条输入记录,并且仅根据最新的输入记录输出结果(白条)。有状态 流处理维护所有已处理记录的状态值,并根据每条新输入的记录更新状态,因此输出记录(灰条)反映的是综合考虑多个事件之后的结果。
尽管无状态的计算很重要,但是流处理对有状态的计算更感兴趣。事实上,正确地实现有状态的计算比实现无状态的计算难得多。旧的流处理系统并不支持有状态的计算,而新一代的流处理系统则将状态及其正确性视为重中之重。
有状态的算子和应用程序
Flink内置的很多算子,数据源source,数据存储sink都是有状态的,流中的数据都是buffer records,会保存一定的元素或者元数据。例如: ProcessWindowFunction会缓存输入流的数据,ProcessFunction会保存设置的定时器信息等等。
在Flink中,状态始终与特定算子相关联。总的来说,有两种类型的状态:
算子状态(operator state)
键控状态(keyed state)
算子状态(operator state)
算子状态的作用范围限定为算子任务。这意味着由同一并行任务所处理的所有数据都可以访问到相同的状态,状态对于同一任务而言是共享的。算子状态不能由相同或不同算子的另一个任务访问。
键控状态(keyed state)
键控状态是根据输入数据流中定义的键(key)来维护和访问的。Flink为每个键值维护一个状态实例,并将具有相同键的所有数据,都分区到同一个算子任务中,这个任务会维护和处理这个key对应的状态。当任务处理一条数据时,它会自动将状态的访问范围限定为当前数据的key。因此,具有相同key的所有数据都会访问相同的状态。Keyed State很类似于一个分布式的key-value map数据结构,只能用于KeyedStream(keyBy算子处理之后)。

1 | val sensorData: DataStream[SensorReading] = ... |
通过RuntimeContext注册StateDescriptor。StateDescriptor以状态state的名字和存储的数据类型为参数。
在open()方法中创建state变量。注意复习之前的RichFunction相关知识。
接下来我们使用了FlatMap with keyed ValueState的快捷方式flatMapWithState实现以上需求。
1 | val alerts: DataStream[(String, Double, Double)] = keyedSensorData |


- 本文作者: xubatian
- 本文链接: http://xubatian.cn/Flink 原理与实现: Flink的状态编程和容错机制之算子状态和键控状态/
- 版权声明: 本博客所有文章除特别声明外均为原创,采用 CC BY 4.0 CN协议 许可协议。转载请注明出处:https://www.xubatian.cn/
 故人的博客
故人的博客
 IT周的博客
IT周的博客
 大胖胖的笔记
大胖胖的笔记
 常瑞的部落落
常瑞的部落落
 Fortune博客
Fortune博客
 星空下的YZY
星空下的YZY
 BOBL技术博客
BOBL技术博客