

数据仓库概述
数据仓库概念
数据仓库是一个为数据分析而设计的企业级数据管理系统。数据仓库可集中、整合多个信息源的大量数据,借助数据仓库的分析能力,企业可从数据中获得宝贵的信息进而改进决策。同时,随着时间的推移,数据仓库中积累的大量历史数据对于数据科学家和业务分析师也是十分宝贵的。
数据仓库核心架构

数据仓库建模概述
数据仓库建模的意义
如果把数据看作图书馆里的书,我们希望看到它们在书架上分门别类地放置;如果把数据看作城市的建筑,我们希望城市规划布局合理;如果把数据看作电脑文件和文件夹,我们希望按照自己的习惯有很好的文件夹组织方式,而不是糟糕混乱的桌面,经常为找一个文件而不知所措。
数据模型就是数据组织和存储方法,它强调从业务、数据存取和使用角度合理存储数据。只有将数据有序的组织和存储起来之后,数据才能得到高性能、低成本、高效率、高质量的使用。
高性能:良好的数据模型能够帮助我们快速查询所需要的数据。
低成本:良好的数据模型能减少重复计算,实现计算结果的复用,降低计算成本。
高效率:良好的数据模型能极大的改善用户使用数据的体验,提高使用数据的效率。
高质量:良好的数据模型能改善数据统计口径的混乱,减少计算错误的可能性。
数据仓库建模方法论
ER模型


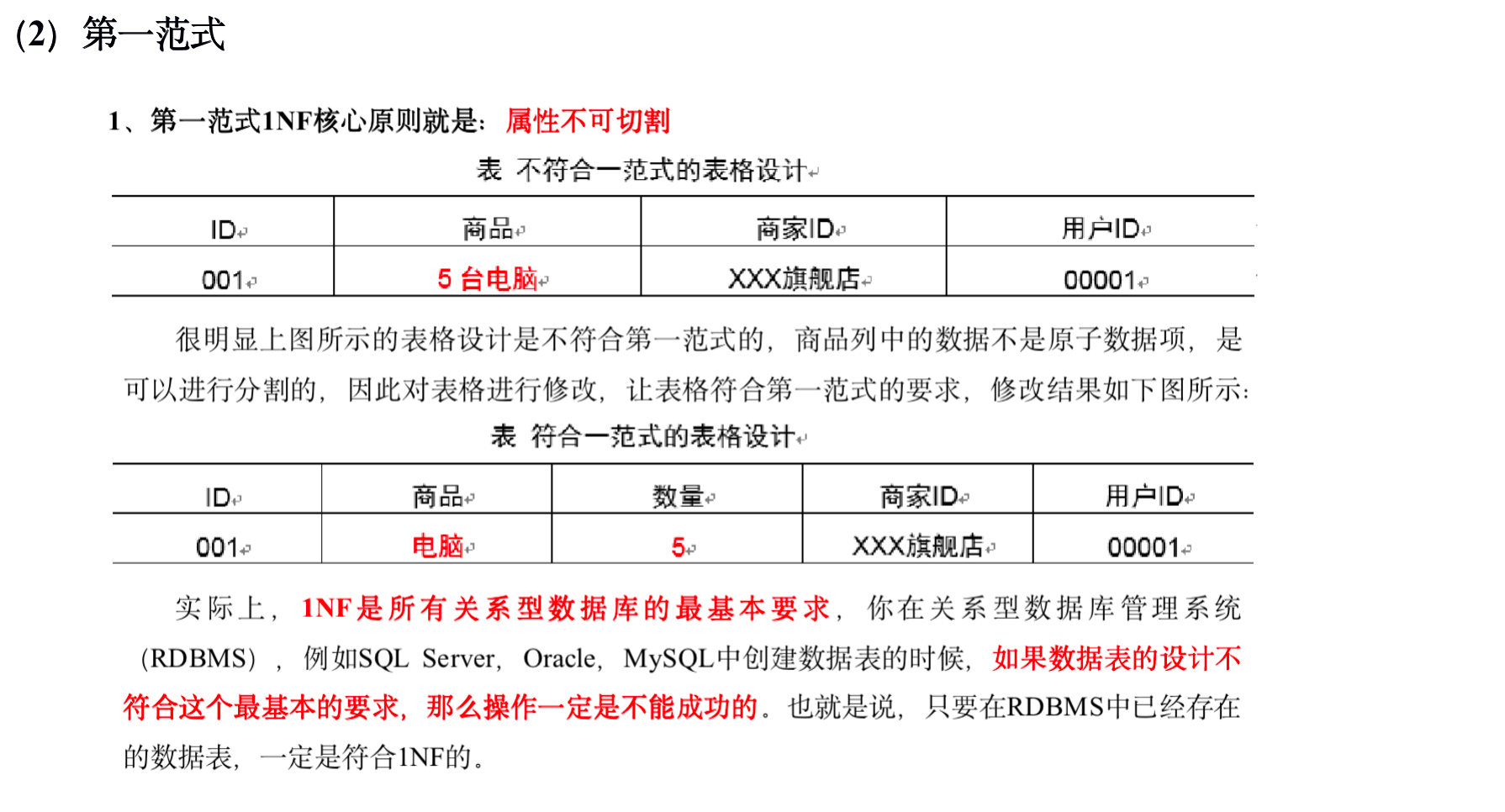
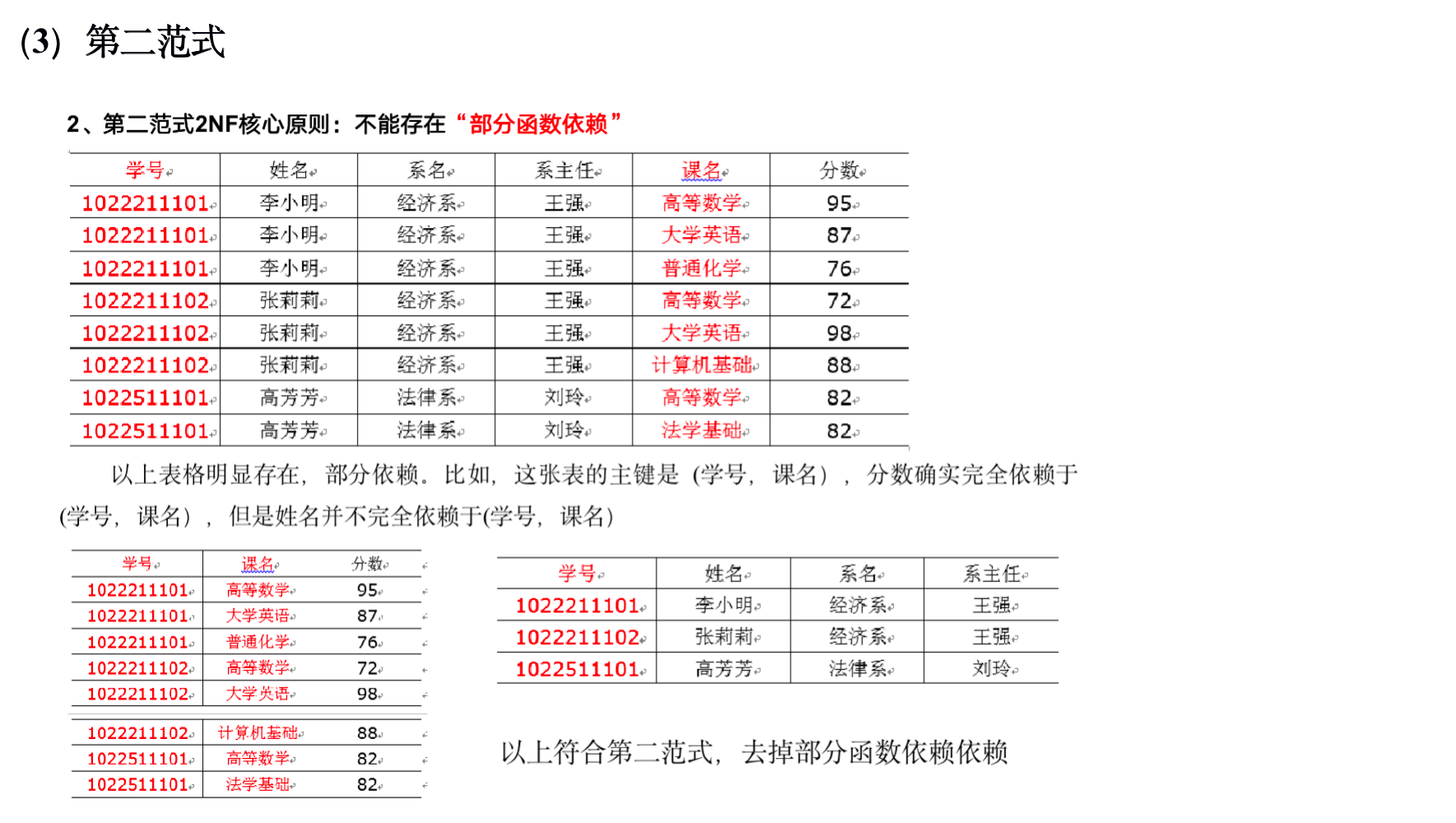
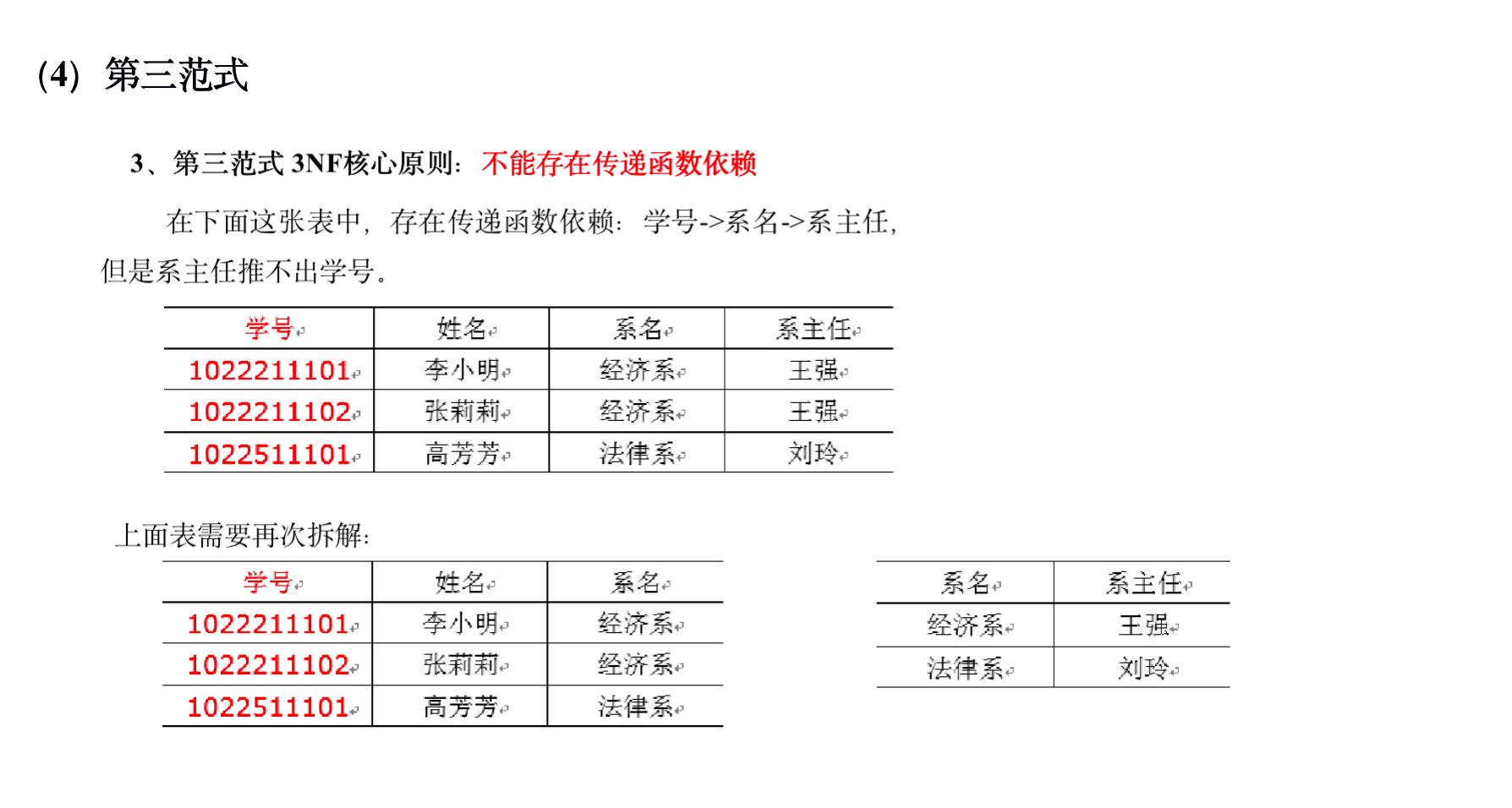
下图为一个采用Bill Inmon倡导的建模方法构建的模型,从图中可以看出,较为松散、零碎,物理表数量多。

这种建模方法的出发点是整合数据,其目的是将整个企业的数据进行组合和合并,并进行规范处理,减少数据冗余性,保证数据的一致性。这种模型并不适合直接用于分析统计。
维度模型


维度建模以数据分析作为出发点,为数据分析服务,因此它关注的重点的用户如何更快的完成需求分析以及如何实现较好的大规模复杂查询的响应性能。
维度建模理论之事实表
事实表概述现在无症状,感染者多。估计政府很快就会实行。全体免疫毕竟控制还得控制的。

事实表特点
事实表通常比较“细长”,即列较少,但行较多,且行的增速快。
事实表分类

事务型事实表
概述

设计流程

不足

周期型快照事实表
概述

设计流程

事实类型

累计型快照事实表
概述

设计流程

维度建模理论之维度表
维度表概述

维度表设计步骤

维度设计要点
规范化与反规范化



维度变化

(1)什么是拉链表

(2)为什么要做拉链表

(3)如何使用拉链表

拉链表的形成过程
拉链表制作过程图

拉链表制作过程

步骤1:制作当日变动数据(包括新增,修改)每日执行

步骤2:先合并变动信息,再追加新增信息,插入到临时表中
1)建立临时表

2)导入脚本

步骤3:把临时表覆盖给拉链表
1)导入数据
1 | hive (gmall)> |
2)查询导入数据
1 | hive (gmall)> select * from dwd_order_info_his; |
整理为每日脚本
多值维度

多值属性

数据仓库设计
数据仓库分层规划
优秀可靠的数仓体系,需要良好的数据分层结构。合理的分层,能够使数据体系更加清晰,使复杂问题得以简化。以下是该项目的分层规划。

数据仓库构建流程
以下是构建数据仓库的完整流程。

数据调研



明确数据域

构建业务总线矩阵



后续的DWD层以及DIM层的搭建需参考业务总线矩阵。
明确统计指标





按照上述标准整理出的指标体系如下:
思维导图版
 从上述指标体系中抽取出来的所有派生指标见如下表格
从上述指标体系中抽取出来的所有派生指标见如下表格
派生指标

维度模型设计
维度模型的设计参照上述得到的业务总线矩阵即可。事实表存储在DWD层,维度表存储在DIM层
汇总模型设计

总结



- 本文作者: xubatian
- 本文链接: http://xubatian.cn/数仓建模设计理论及概念/
- 版权声明: 本博客所有文章除特别声明外均为原创,采用 CC BY 4.0 CN协议 许可协议。转载请注明出处:https://www.xubatian.cn/
 故人的博客
故人的博客
 IT周的博客
IT周的博客
 大胖胖的笔记
大胖胖的笔记
 常瑞的部落落
常瑞的部落落
 Fortune博客
Fortune博客
 星空下的YZY
星空下的YZY
 BOBL技术博客
BOBL技术博客