

1 | 文章收录的是公众号: 大数据公羊说 的 面试题总结. |
本文目录概览
- 面试题:你在生产环境中碰到哪些问题会导致反压?
- 面试题:反压有哪些危害?
- 面试题: 状态、状态后端、Checkpoint 三者之间的区别及关系?
- 面试题 : 把状态后端从 FileSystem 变为 RocksDB 后,Flink 任务状态存储会发生那些变化?
- 面试题: 什么样的业务场景你会选择 filesystem,什么样的业务场景你会选 rocksdb 状态后端?
- 面试题: Flink SQL API State TTL 的过期机制是 onCreateAndUpdate 还是onReadAndWrite?
- 面试题: watermark 到底是干啥的?应用场景?
- 面试题: 一个 Flink 任务中可以既有事件时间窗口,又有处理时间窗口吗?
- 面试题: window 后面跟 aggregate 和 process 的两个窗口计算的区别是什么?
- 面试题: 为什么 Flink DataStream API 在函数入参或者出参有泛型时,不能使用 lambda 表达式?
- 面试题: Flink 为什么强调 function 实现时,实例化的变量要实现 serializable 接口?
- 面试题: Flink 的并行度可以通过哪几种方式设置,优先级关系是什么?
- 面试题: 你是怎么合理的评估 Flink 任务的并行度?
- 面试题: 你是怎么合理评估任务最大并行度?
- 面试题:operator state 和 keyed state 两者的区别?最大并行度和这两种 state 的关系?举个例子,当用户停止任务、更新代码逻辑并且改变任务并发度时,两种 state 都是怎样进行恢复的?
- 面试题:你们公司是通过什么样的监控及保障手段来保障实时指标的质量?比如事前事中事后是怎么做的?
- 面试题:在实时数仓的分层设计中,你是怎么兼顾时效性和通用性的?具体的分层设计方案是怎样的?
- 面试题:你们公司的实时数仓用到的维表都有哪些类型?分别是通过什么样的方式构建的?
- 面试题:你是怎么避免或者缓解数据倾斜的?
- 面试题:你们公司在遇到大促时是怎么估算 flink 任务资源的,有没有成体系的方案?flink任务压测又是怎么做的,有没有工具支持?
- 面试题:Flink 配置 State TTL 时都有哪些配置项?每种配置项的作用?Flink State TTL 是怎么做到数据过期的?
- 面试题:我们都知道 flink 任务 failover 之后,可能会重复写出数据到 sink 中,你们公司是怎么做到端对端 exactly-once 的?
面试题:你在生产环境中碰到哪些问题会导致反压?
- 数据倾斜:比如当前算子的每个并发只能处理 1w qps 的数据,而由于数据倾斜,这个算子平均 1s 需要处理 2w 条数据,因此倾斜的算子处理压力大,从而反压
- 算子性能问题:比如下游整个整个算子的处理性能差,上游是 1w qps,当前整个算子算下来平均只能处理 1k qps,因此就有反压的情况
面试题:反压有哪些危害?
- CK 时间长或者失败。反压导致 barrier 需要花很长时间才能对齐。
- 整个任务完全卡住。比如在 TUMBLE 窗口算子的任务中,反压后可能会导致下游算子的 inputpool 和上游算子的 outputpool 满了,这时候如果下游窗口的 watermark 一直对不齐,窗口触发不了的话,下游算子就永远无法触发窗口计算了。整个任务卡住。
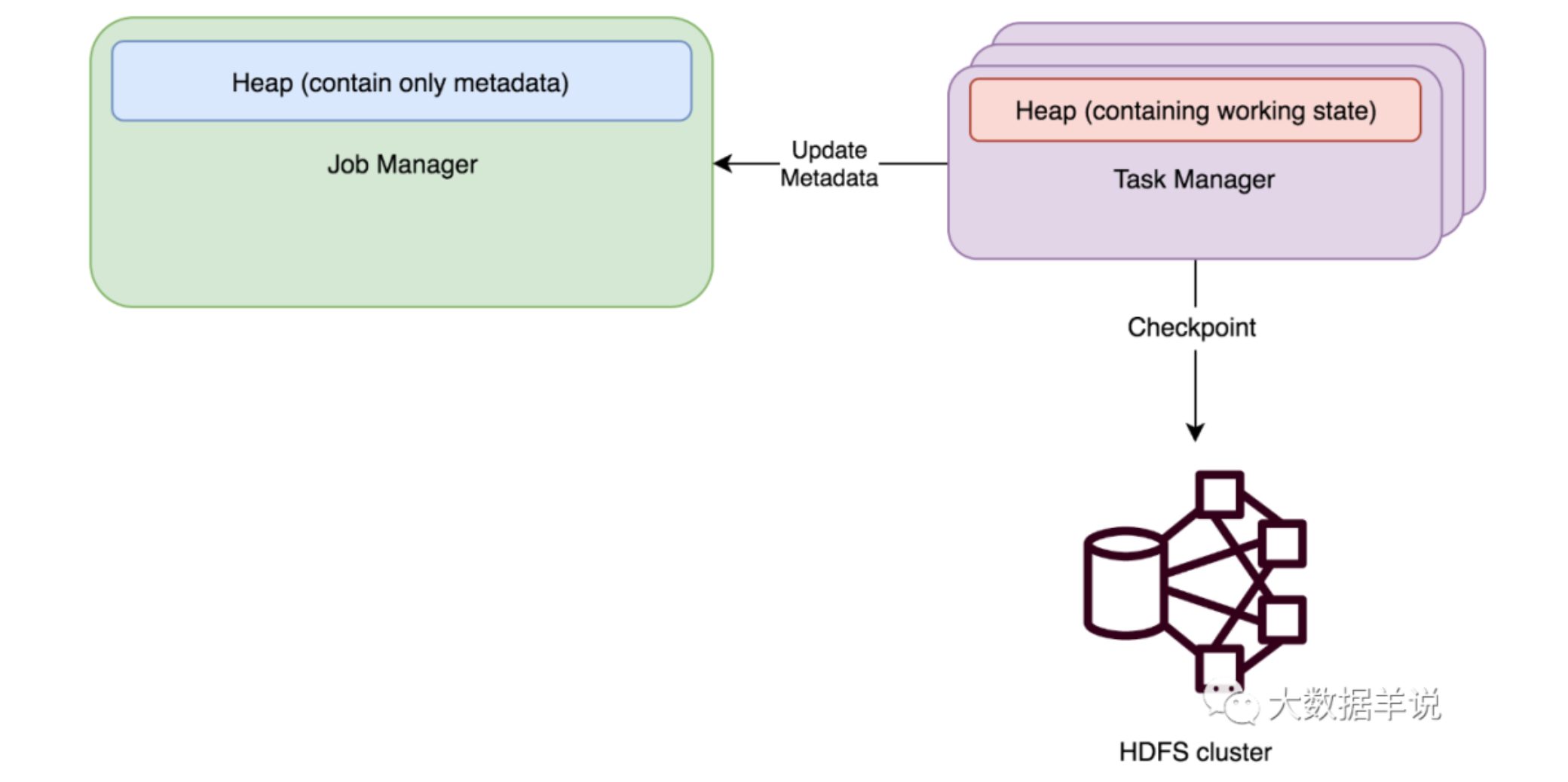
面试题: 状态、状态后端、Checkpoint 三者之间的区别及关系?
结论:拿五个字做比喻:”铁锅炖大鹅”,铁锅是状态后端,大鹅是状态,Checkpoint 是炖的动作。
- 状态:本质来说就是数据,在 Flink 中,其实就是 Flink 提供给用户的状态编程接口。比如 flink 中的 MapState,ValueState,ListState。
- 状态后端:Flink 提供的用于管理状态的组件,状态后端决定了以什么样数据结构,什么样的存储方式去存储和管理我们的状态。Flink 目前官方提供了 memory、filesystem,rocksdb 三种状态后端来存储我们的状态。
- Checkpoint(状态管理):Flink 提供的用于定时将状态后端中存储的状态同步到远程的存储系统的组件或者能力。为了防止 long run 的 Flink 任务挂了导致状态丢失,产生数据质量问题,Flink 提供了状态管理(Checkpoint,Savepoint)的能力把我们使用的状态给管理起来,定时的保存到远程。然后可以在 Flink 任务 failover 时,从远程把状态数据恢复到 Flink 任务中,保障数据质量。
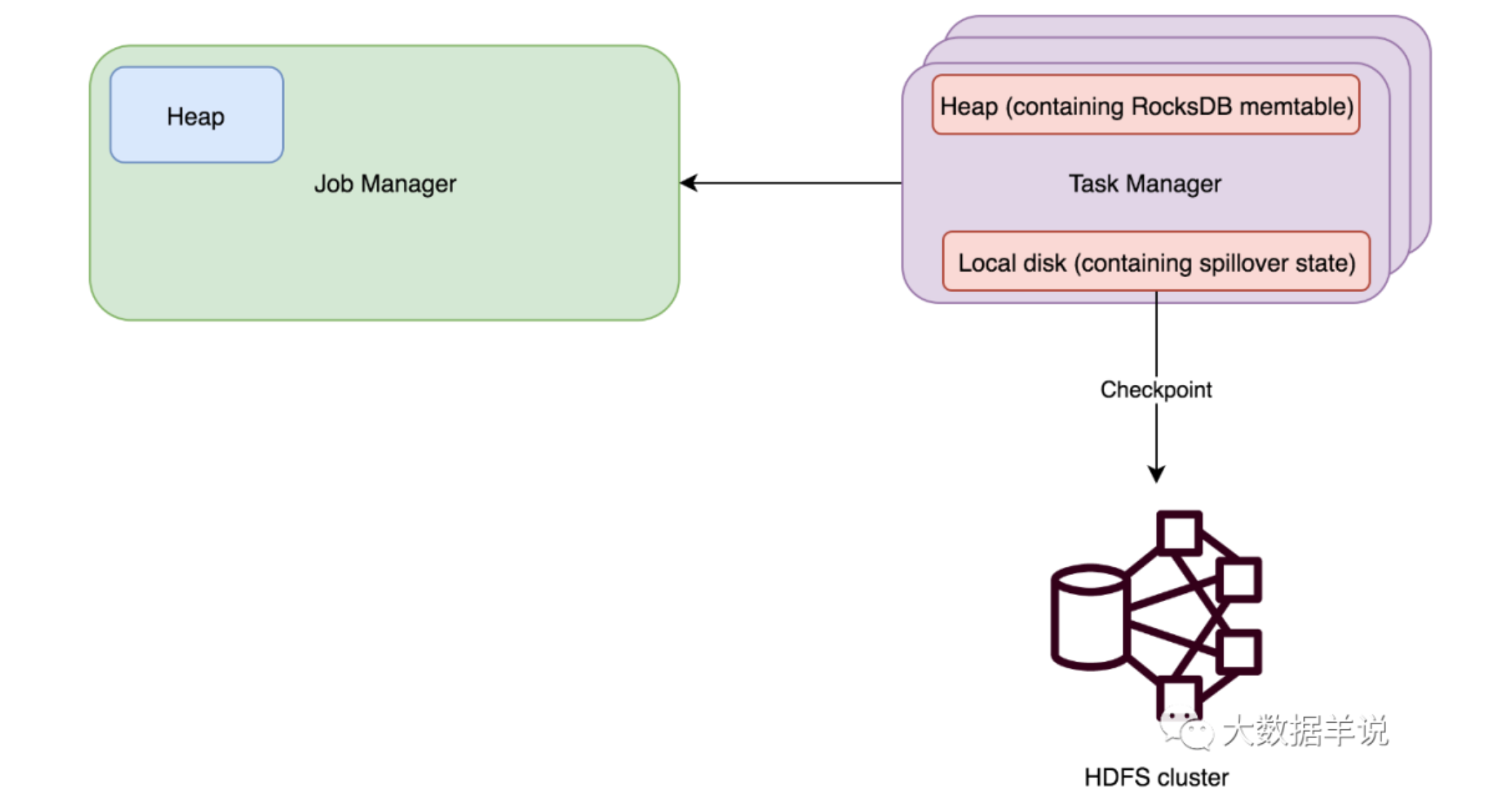
面试题 : 把状态后端从 FileSystem 变为 RocksDB 后,Flink 任务状态存储会发生那些变化?
1 | 结论:是否使用 RocksDB 只会影响 Flink 任务中 keyed-state 存储的方式和地方,Flink 任务中的 operator-state 不会受到影响。 |
首先我们来看看,Flink 中的状态只会分为两类:
keyed-state:键值状态,如其名字,此类状态是以 k-v 的形式存储,状态值和 key 绑定。Flink 中的 keyby 之后紧跟的算子的 state 就是键值状态;
operator-state:算子状态,非 keyed-state 的 state 都是算子状态,非 k-v 结构,状态值和算子绑定,不和 key 绑定。Flink 中的 kafka source 算子中用于存储 kafka offset 的 state 就是算子状态。
如下图所示是 3 种状态后端和 2 种 State 的对应存储关系:

横向(行)来看,即 Flink 的状态分类。分为 Operator state-backend、Keyed state-backend;
纵向(列)来看,即 Flink 的状态后端分类。用户可以配置 memory,filesystem,rocksdb 3 中状态后端,在 Flink 任务中生成 MemoryStateBackend,FsStateBackend,RocksdbStateBackend,其声明了整个任务的状态管理后端类型;
每个格子中的内容就是用户在配置 xx 状态后端(列)时,给用户使用的状态(行)生成的状态后端实例,生成的这个实例就是在 Flink 中实际用于管理用户使用的状态的组件。
因此对应的结论就是:
Flink 任务中的 operator-state。无论用户配置哪种状态后端(无论是 memory,filesystem,rocksdb),都是使用 DefaultOperatorStateBackend 来管理的,状态数据都存储在内存中,做 Checkpoint 时同步到远程文件存储中(比如 HDFS)。
Flink 任务中的 keyed-state。用户在配置 rocksdb 时,会使用 RocksdbKeyedStateBackend 去管理状态;用户在配置 memory,filesystem 时,会使用 HeapKeyedStateBackend 去管理状态。因此就有了这个问题的结论,配置 rocksdb 只会影响 keyed-state 存储的方式和地方,operator-state 不会受到影响。
面试题: 什么样的业务场景你会选择 filesystem,什么样的业务场景你会选 rocksdb 状态后端?
在回答这个问题前,我们先看看每种状态后端的特性:
MemoryStateBackend
原理:运行时所需的 State 数据全部保存在 TaskManager JVM 堆上内存中,执行 Checkpoint 的时候,会把 State 的快照数据保存到 JobManager 进程 的内存中。执行 Savepoint 时,可以把 State 存储到文件系统中。

适用场景:
- 基于内存的 StateBackend 在生产环境下不建议使用,因为 State 大小超过 JobManager 内存就 OOM 了,此种状态后端适合在本地开发调试测试,生产环境基本不用。
- State 存储在 JobManager 的内存中。受限于 JobManager 的内存大小。
- 每个 State 默认 5MB,可通过 MemoryStateBackend 构造函数调整。d.每个 Stale 不能超过 Akka Frame 大小。
FSStateBackend
原理:运行时所需的 State 数据全部保存在 TaskManager 的内存中,执行 Checkpoint 的时候,会把 State 的快照数据保存到配置的文件系统中。TM 是异步将 State 数据写入外部存储。
适用场景:
- a.适用于处理小状态、短窗口、或者小键值状态的有状态处理任务,不建议在大状态的任务下使用 FSStateBackend。比如 ETL 任务,小时间间隔的 TUMBLE 窗口 b.State 大小不能超过 TM 内存。
RocksDBStateBackend
原理:使用嵌入式的本地数据库 RocksDB 将流计算数据状态存储在本地磁盘中。在执行 Checkpoint 的时候,会将整个 RocksDB 中保存的 State 数据全量或者增量持久化到配置的文件系统中。
适用场景:
- a.最适合用于处理大状态、长窗口,或大键值状态的有状态处理任务。
- b.RocksDBStateBackend 是目前唯一支持增量检查点的后端。
- c.增量检查点非常适用于超大状态的场景。比如计算 DAU 这种大数据量去重,大状态的任务都建议直接使用 RocksDB 状态后端。
到生产环境中:
如果状态很大,使用 Rocksdb;如果状态不大,使用 Filesystem。
Rocksdb 使用磁盘存储 State,所以会涉及到访问 State 磁盘序列化、反序列化,性能会收到影响,而 Filesystem 直接访问内存,单纯从访问状态的性能来说 Filesystem 远远好于 Rocksdb。生产环境中实测,相同任务使用 Filesystem 性能为 Rocksdb 的 n 倍,因此需要根据具体场景评估选择。
面试题: Flink SQL API State TTL 的过期机制是 onCreateAndUpdate 还是onReadAndWrite?
结论:Flink SQL API State TTL 的过期机制目前只支持 onCreateAndUpdate,DataStream API 两个都支持
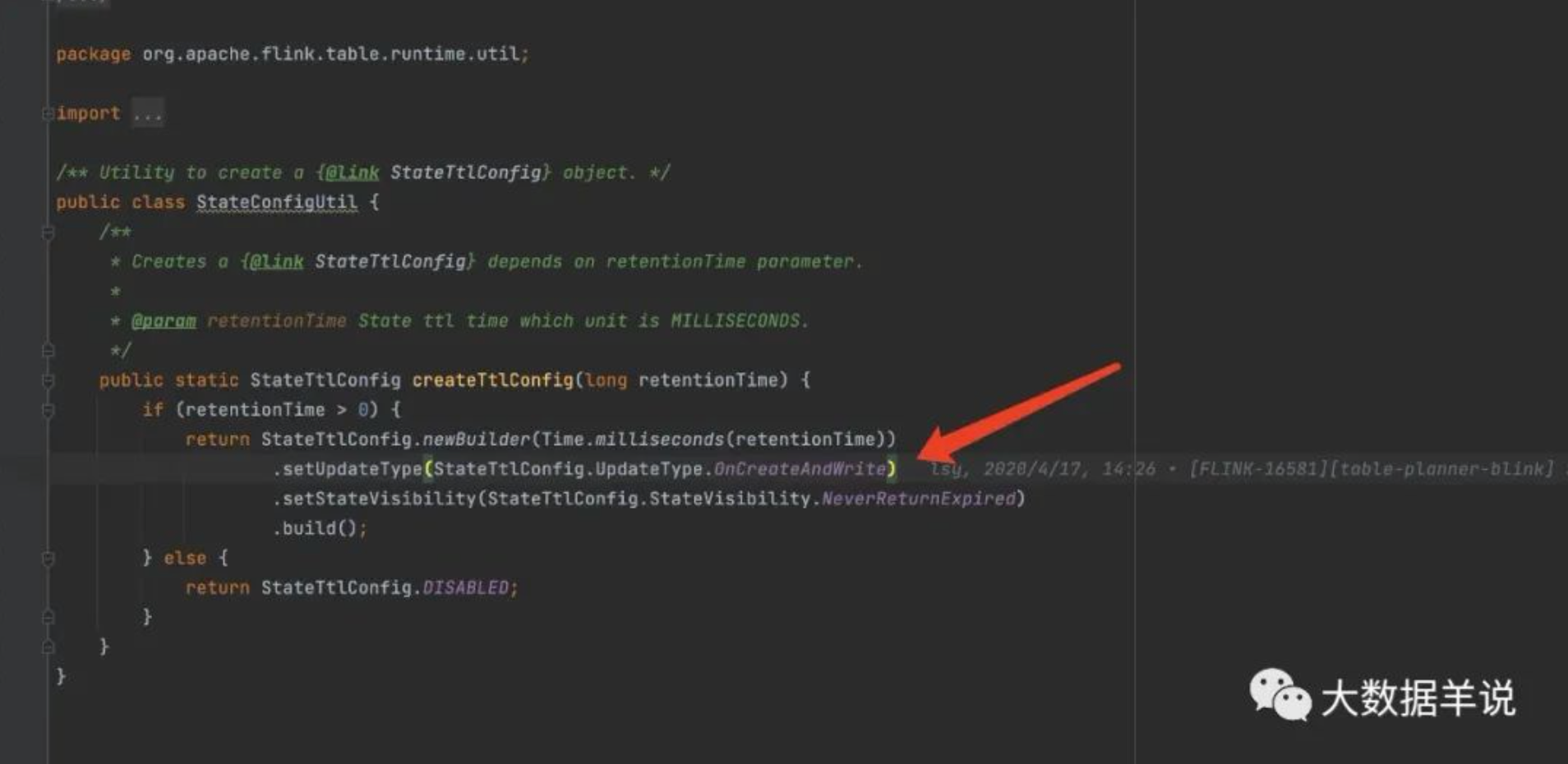
剖析:
- onCreateAndUpdate:是在创建 State 和更新 State 时【更新 State TTL】
- onReadAndWrite:是在访问 State 和写入 State 时【更新 State TTL】
实际踩坑场景:Flink SQL Deduplicate 写法,row_number partition by user_id order by proctime asc,此 SQL 最后生成的算子只会在第一条数据来的时候更新 state,后续访问不会更新 state TTL,因此 state 会在用户设置的 state TTL 时间之后过期。
面试题: watermark 到底是干啥的?应用场景?
大部分同学都只能回答出:watermark 是用于缓解时间时间的乱序问题的。
没错,这个观点是正确的。但是博主认为这只是 watermark 第二重要的作用,其更重要的作用在于可以标识一个 Flink 任务的事件 时间进度。
怎么理解 时间进度?
我们可以现象一下,一个事件时间窗口的任务,如果没有一个 东西 去标识其事件时间的进度,那么这个事件时间的窗口也就是不知道什么时候能够触发了,也就是说这个窗口永远不会触发并且输出结果。
所以要有一个 东西 去标识其事件时间的进度,从而让这个事件时间窗口知道,这个事件时间窗口已经结束了,可以触发计算了。在 Flink 中,这个 东西 就是 watermark。
总结一下,博主认为 watermark 为 Flink 解决了两个问题:
标识 Flink 任务的事件时间进度,从而能够推动事件时间窗口的触发、计算。
解决事件时间窗口的乱序问题。
面试题: 一个 Flink 任务中可以既有事件时间窗口,又有处理时间窗口吗?
结论:一个 Flink 任务可以同时有事件时间窗口,又有处理时间窗口。
那么有些小伙伴们问了,为什么我们常见的 Flink 任务要么设置为事件时间语义,要么设置为处理时间语义?
确实,在生产环境中,我们的 Flink 任务一般不会同时拥有两种时间语义的窗口。
那么怎么解释开头博主所说的结论呢?
博主这里从两个角度进行说明:
我们其实没有必要把一个 Flink 任务和某种特定的时间语义进行绑定。对于事件时间窗口来说,我们只要给它 watermark,能让 watermark 一直往前推进,让事件时间窗口能够持续触发计算就行。对于处理时间来说更简单,只要窗口算子按照本地时间按照固定的时间间隔进行触发就行。无论哪种时间窗口,主要满足时间窗口的触发条件就行。
Flink 的实现上来说也是支持的。Flink 是使用一个叫做 TimerService 的组件来管理 timer 的,我们可以同时注册事件时间和处理时间的 timer,Flink 会自行判断 timer 是否满足触发条件,如果是,则回调窗口处理函数进行计算。
面试题: window 后面跟 aggregate 和 process 的两个窗口计算的区别是什么?
aggregate:是增量聚合,来一条数据计算完了存储在累加器中,不需要等到窗口触发时计算,性能较好;
process:全量函数,缓存全部窗口内的数据,满足窗口触发条件再触发计算,同时还提供定时触发,窗口信息等上下文信息;
应用场景:aggregate 一个一个处理的聚合结果向后传递一般来说都是有信息损失的,而 process 则可以更加定制化的处理。
面试题: 为什么 Flink DataStream API 在函数入参或者出参有泛型时,不能使用 lambda 表达式?
Flink 类型信息系统是通过反射获取到 Java class 的方法签名去获取类型信息的。
以 FlatMap 为例,Flink 在通过反射时会检查及获取 FlatMap collector 的出参类型信息。
但是 lambda 表达式写的 FlatMap 逻辑,会导致反射方法获取类型信息时【直接获取不到】collector 的出参类型参数,所以才会报错。
面试题: Flink 为什么强调 function 实现时,实例化的变量要实现 serializable 接口?
其实这个问题可以延伸成 3 个问题:
为什么 Flink 要用到 Java 序列化机制。和 Flink 类型系统的数据序列化机制的用途有啥区别?
非实例化的变量没有实现 Serializable 为啥就不报错,实例化就报错?
为啥加 transient 就不报错?
上面 3 个问题的答案如下:
Flink 写的函数式编程代码或者说闭包,需要 Java 序列化从 JobManager 分发到 TaskManager,而 Flink 类型系统的数据序列化机制是为了分发数据,不是分发代码,可以用非Java的序列化机制,比如 Kyro。
编译期不做序列化,所以不实现 Serializable 不会报错,但是运行期会执行序列化动作,没实现 Serializable 接口的就报错了
Flink DataStream API 的 Function 作为闭包在网络传输,必须采用 Java 序列化,所以要通过 Serializable 接口标记,根据 Java 序列化的规定,内部成员变量要么都可序列化,要么通过 transient 关键字跳过序列化,否则 Java 序列化的时候会报错。静态变量不参与序列化,所以不用加 transient。
面试题: Flink 的并行度可以通过哪几种方式设置,优先级关系是什么?
代码中算子单独设置
代码中Env全局设置
提交参数
默认配置信息
上面的 Flink 并行度优先级从上往下由大变小。
面试题: 你是怎么合理的评估 Flink 任务的并行度?
Flink 任务并行度合理行一般根据峰值流量进行压测评估,并且根据集群负载情况留一定量的 buffer 资源。
- 如果数据源已经存在,则可以直接消费进行测试
- 如果数据源不存在,需要自行造压测数据进行测试
对于一个 Flink 任务来说,一般可以按照以下方式进行细粒度设置并行度:
source 并行度配置:以 kafka 为例,source 的并行度一般设置为 kafka 对应的 topic 的分区数
transform(比如 flatmap、map、filter 等算子)并行度的配置:这些算子一般不会做太重的操作,并行度可以和 source 保持一致,使得算子之间可以做到 forward 传输数据,不经过网络传输
keyby 之后的处理算子:建议最大并行度为此算子并行度的整数倍,这样可以使每个算子上的 keyGroup 是相同的,从而使得数据相对均匀 shuffle 到下游算子,如下图为 shuffle 策略

sink 并行度的配置:sink 是数据流向下游的地方,可以根据 sink 的数据量及下游的服务抗压能力进行评估。如果 sink 是 kafka,可以设为 kafka 对应 topic 的分区数。注意 sink 并行度最好和 kafka partition 成倍数关系,否则可能会出现如到 kafka partition 数据不均匀的情况。但是大多数情况下 sink 算子并行度不需要特别设置,只需要和整个任务的并行度相同就行。
面试题: 你是怎么合理评估任务最大并行度?
- 前提:并行度必须 <= 最大并行度
- 最大并行度的作用:合理设置最大并行度可以缓解数据倾斜的问题
- 根据具体场景的不同,最大并行度大小设置也有不同的方式:
- 在 key 非常多的情况下,最大并行度适合设置比较大(几千),不容易出现数据倾斜,以 Flink SQL 场景举例:row_number = 1 partition key user_id 的 Deduplicate 场景(user_id 一般都非常多)
- 在 key 不是很多的情况下,最大并行度适合设置不是很大,不然会加重数据倾斜,以 Flink SQL 场景举例:group by dim1,dim2 聚合并且维度值不多的 group agg 场景(dim1,dim2 可以枚举),如果依然有数据倾斜的问题,需要自己先打散数据,缓解数据倾斜
- 最大并行度的使用限制:最大并行度一旦设置,是不能随意变更的,否则会导致检查点或保存点失效;最大并行度设置会影响 MapState 状态划分的 KeyGroup 数,并行度修改后再从保存点启动时,KeyGroup 会根据并行度的设定进行重新分布。
- 最大并行度的设置:最大并行度可以自己设置,也可以框架默认生成;默认的算法是取当前算子并行度的 1.5 倍和 2 的 7 次方比较,取两者之间的最大值,然后用上面的结果和 2 的 15 次方比较,取其中的最小值为默认的最大并行度,非常不建议自动生成,建议用户自己设置。
面试题:operator state 和 keyed state 两者的区别?最大并行度和这两种 state 的关系?举个例子,当用户停止任务、更新代码逻辑并且改变任务并发度时,两种 state 都是怎样进行恢复的?
区分 operator-state 和 keyed-state 的方式
a. operator-state:
1 | 1. 状态适用算子:所有算子都可以使用 operator-state,没有限制。 |
b. keyed-state:
1 | 1. 状态适用算子:keyed-stream 后的算子使用。注意这里很多同学会犯一个错误,就是大家会认为 keyby 后面跟的所有算子都使用的是 keyed-state,但这是错误的 ❌,比如有 keyby.process.flatmap,其中 flatmap 中使用状态的话是 operator-state |
面试题:你们公司是通过什么样的监控及保障手段来保障实时指标的质量?比如事前事中事后是怎么做的?
上面的保障方案博主总结一个大多数企业都可以【快速构建的简版】,从【事前、事中、事后】x【任务层面、指标层面】进行监控、保障:
- 事前:
a. 任务层面:根据峰值流量进行压力测试,并且留一定 buffer,用于事前保障任务在资源层面没有瓶颈
b. 指标层面:根据业务要求,上线实时指标前进行相同口径的实时、离线指标的验数 - 事中:
a. 任务层面:贴源层监控 kafka 堆积延迟等报警检测手段,用于事中及时发现问题。比如的普罗米修斯监控 lag 时长
b. 指标层面:根据指标特点进行实时指标同环比对比监控、实时离线指标结果对比监控。这里的监控算法可以是阈值、时序异常算法等。检测到波动过大就报警。比如最简单的方式是可以通过将实时结果导入到离线,然后和离线指标对比;也可以构建异构数据源对比工具进行对比 - 事后:
a. 任务层面:对于可能发生的故障类型,构建用于故障修复、数据回溯的实时任务备用链路
b. 指标层面:构建指标修复预案,根据不同的故障类型,判断是否可以使用实时任务进行修复。如果实时无法修复,构建离线恢复链路,以便使用离线数据进行覆写修复
面试题:在实时数仓的分层设计中,你是怎么兼顾时效性和通用性的?具体的分层设计方案是怎样的?
实时数仓相比离线数仓的特点其实就两个字:实时。具体体现在:
- 产出速度比离线数仓快,常常为分钟级别产出数据。
- 实时数据时间粒度比离线数仓细,dws、ads 聚合粒度通常为分钟级别。
那么我们再来看看,如果按照离线数仓分层方案去设计实时数仓分层会有什么问题,其实就对应上面两个特点:
- 分层太多,产出速度必然减慢。举例:ods->dwd->dws(1min 窗口)->dws(1min 窗口)->ads(1min 窗口)。这样 ads 层数据产出延迟肯定在 3 min 以上。
- 分层太多,实时数据粒度又细,多种粒度的 dws 的数据量基本一样,不如不建。举例:ods->dwd->dws1(uid,page,style,1min粒度)->dws2(uid,page,1min粒度)->ads(uid 1min粒度),因为一个用户在 1min 内发生的行为很少,你可能会发现 dws1,dws2,ads 的 qps 都差不多;而离线通常都是 1天的粒度,所以分这几层的数据量是会有骤减的。
综上所述,实时数仓分层不宜特别多。建议:
如果数据量不大,建立 ods->dwd 就足够使用。
如果数据量大,可以根据 dws 聚合后,数据量缩减的实际效果来评估是否需要建立 dws。
面试题:你们公司的实时数仓用到的维表都有哪些类型?分别是通过什么样的方式构建的?
常用的维表一般分为 2 种:
- t-1 维表:
a.应用场景:比如画像类维表,一般画像类基本很少发生变化,比如性别、年龄区间等,所以这类在实时数仓中常常是访问 t-1 维表数据的就足够使用
b.常用存储介质:redis,hbase,mysql
c.维表构建方式:一般原始数据都存储在 hive 中,可以使用同步工具(比如 Apache Seatunnel)定时调度(比如 Apache Dolphinscheduler)将 hive 中的数据导入 redis,hbase,mysql 中 - 实时维表:
a.应用场景:维度实时发生更新的,这类在实时数仓中需要访问最新的维度数据
b.常用存储介质:redis,hbase,mysql
c.维表构建方式:这种实时的维度数据一般是存储在原始日志中,比如常见存储在 Kafka 这类消息队列中,可以通过 Flink 消费原始日志,然后实时构建维度数据写入 redis,hbase,mysql 中
面试题:你是怎么避免或者缓解数据倾斜的?
业务数据本身的特点导致倾斜:
场景:拿计算直播间的同时在线观看用户数来说,大 v 直播间的人数会比小直播间的任务多几个量级,因此如果计算一个直播间的数据需要注意这种业务数据倾斜的特点
解决方案:计算这种数据时,我们可以先按照直播间 id 将数据进行打散,如下 sql 案例所示,内层打散,外层合并:
select id, sum(bucket_uv) as uv
from (select id, count(distinct uid) as bucket_uv from source group by id, mod(uid, 1000))
group by id。datastream 也是相同的解决方案数据任务处理时代码处理逻辑导致倾斜:
场景:比如有时候虽然用户已经按照 key 进行分桶计算,但是【最大并发度】设置为 150,【并发度】设置为 100,会导致 keygroup 在 sub-task 的划分不均匀(其中 50 个 sub-task 的 keygroup 为 2 个,剩下的 50 个 sub-task 为 1 个)导致数据倾斜。
解决方案:设置合理的【最大并发度】【并发度】,【最大并发度】最好为【并发度】的倍数关系,比如【最大并发度】1024,【并发度】512我已经设置【数据分桶打散】+【最大并发为并发 n 倍】,为啥还出现数据倾斜?
场景:你的【数据分桶】和【最大并发数】之间可能是不均匀的。因为 Flink 会将 keyby 的 key 拿到之后计算 hash 值,然后根据 hash 值去决定发送到那个 sub-task 去计算。这是就有可能出现你的【数据分桶】key 经过 hash 计算完成之后,并不能均匀的发到所有的 keygroup 中。比如【最大并发数】4096,【数据分桶】key 只有 1024 个,那么这些数据必然最多只能到 1024 个 keygroup 中,有可能还少于 1024,从而导致剩下的 3072 个 keygroup 没有任何数据
解决方案:其实可以利用【数据分桶】key 和【最大并行度】两个参数,在 keyby 中实现和 Flink key hash 选择 keygroup 的算法一致的算法,在【最大并发数】4096,【数据分桶】为 4096 时,做到分桶值为 1 的数据一定会发送到 keygroup1 中,2 一定会发到 keygroup2 中,从而缓解数据倾斜。
面试题:你们公司在遇到大促时是怎么估算 flink 任务资源的,有没有成体系的方案?flink任务压测又是怎么做的,有没有工具支持?
1 | 这有一个背景: |
其实现在很多公司的现状就是:拍脑袋,能多要资源就多要。但是其实如果我们能对资源预估有一个成体系、有数据支撑的方案在要资源时是更有说服力的。
一般有 3 种思路去成体系预估资源:
目前在线任务的资源占用情况评估:
a. 适用场景:目前存量(在线)任务要在大促中使用时的场景。
b. 举例:比如历史大促时,流量是 n,资源会用 x,今年预估流量最大是 2n,则资源可以认为也是 2x 就足够。
c. 预估的准确率:高按照目前很多云厂商提供的标准评估:
a. 适用场景:大促新开发的任务,并且没有之前的经验可以借鉴的场景。
b. 举例:比如我们的 dwd 任务(简单业务),一般就 1CU 处理 1w qps 数据,复杂的清洗可能流量会讲到更低;dws,ads 任务(复杂任务)一般就 1CU 处理 5k qps 数据;涉及到访问外部接口时,则要使用访问外部接口的 qps / 接口请求时延评估。
c. 预估准确率:中。这些标准都是云厂商经过无数的测试、压测得到的,大家可以参考。新模块、新任务评估:
a. 适用场景:大促新开发的任务,之前的经验可以借鉴的场景。
b. 举例:比如按照历史大促情况来看,一个模块、一类任务的处理能力。比如分模块来说,历史经验 1 个模块基本需要 n cu(云厂商 1cu = 1core 4GB),当前有 5 个模块,则大致需要 5n cu;又比如分任务类型来说,历史经验 dwd 可以达到 1CU x qps,dws、ads 可以到达 1CU y qps,根据需求来看总共 3 dwd,每个 dwd 2x qps,5 ads,每个 ads 3y qps,则 dwd 总共需要 6CU,ads 总共需要 15CU
c. 预估准确率:高。这个一般都是自己公司内部的历史经验,所以可参考性更高。
面试题:Flink 配置 State TTL 时都有哪些配置项?每种配置项的作用?Flink State TTL 是怎么做到数据过期的?
a.State TTL 时都有哪些配置项?
这个问题的答案就如下图所示:
其实和 redis 的过期策略类似,举例:
- 支持 ttl
- 支持 ttl 更新类型
- 过期数据的可见性
- 过期时间语义:目前只支持处理时间
- 具体过期实现:lazy,后台线程
b.Flink State TTL 是怎么做到数据过期的?
首先我们来想想,要做到 TTL 的话,要具备什么条件呢?想想 Redis 的 TTL 设置,如果我们要设置 TTL 则必然需要给一条数据给一个时间戳,只有这样才能判断这条数据是否过期了。
在 Flink 中设置 State TTL,就会有这样一个时间戳,具体实现时,Flink 会把时间戳字段和具体数据字段存储作为同级存储到 State 中。举个例子,我要将一个 String 存储到 State 中时,没有设置 State TTL 时,则直接将 String 存储在 State 中;如果设置 State TTL 时,则 Flink 会将 <String, Long> 存储在 State 中,其中 Long 为时间戳。
接下来以 FileSystem 状态后端下的 MapState 作为案例来说:
如果没有设置 State TTL,则生产的 MapState 的字段类型如下:
可以看到生成的就是 HeapMapState 实例
如果设置了 State TTL,则生成的 MapState 的字段类型如下:
可以看到使用到了装饰器的设计模式生成是 TtlMapState
因此这里至少我们可以得到一个结论就是,如果任务设置了 State TTL 和不设置 State TTL 的状态是不兼容的。这里大家在使用时一定要注意。
然后我们再来看看 State 过期的几种策略,先总结一下:
- lazy 删除策略:就是在访问 State 的时候根据时间戳判断是否过期,如果过期则主动删除 State 数据
- full snapshot cleanup 删除策略:从状态恢复(checkpoint、savepoint)的时候采取做过期删除,但是不支持 rocksdb 增量 ck。
- incremental cleanup 删除策略:访问 state 的时候,主动去遍历一些 state 数据判断是否过期,如果过期则主动删除 State 数据。
a. 如果没有 state 访问,也没有处理数据,则不会清理过期数据。
b. 增量清理会增加数据处理的耗时。
c. 现在仅 Heap state backend 支持增量清除机制。在 RocksDB state backend 上启用该特性无效。 - rocksdb compaction cleanup 删除策略:rockdb 做 compaction 的时候遍历进行删除。仅仅支持 rocksbd。
a. 压缩时调用 TTL 过滤器会降低速度。TTL 过滤器需要解析上次访问的时间戳,并对每个将参与压缩的状态进行是否过期检查。 对于集合型状态类型(比如 list 和 map),会对集合中每个元素进行检查。
b. 对于元素序列化后长度不固定的列表状态,TTL 过滤器需要在每次 JNI 调用过程中,额外调用 Flink 的 java 序列化器, 从而确定下一个未过期数据的位置。
面试题:我们都知道 flink 任务 failover 之后,可能会重复写出数据到 sink 中,你们公司是怎么做到端对端 exactly-once 的?
目前有两种常用方法:
- sink 两阶段:由于两阶段提交是随着 checkpoint 进行的,所以会碰到产出数据延迟等问题,目前用的比较少
- sink 支持幂等:举例:sink mysql 按照 key 更新数据,sink druid 选用 longmax,sink redis 按照 key 重复 set
收录文章地址:
https://mp.weixin.qq.com/s/meKL9R0zlkLh-OAWyfLZ1g


- 本文作者: xubatian
- 本文链接: http://xubatian.cn/大数据公羊说之Flink每日一题收录/
- 版权声明: 本博客所有文章除特别声明外均为原创,采用 CC BY 4.0 CN协议 许可协议。转载请注明出处:https://www.xubatian.top/
 故人的博客
故人的博客
 IT周的博客
IT周的博客
 大胖胖的笔记
大胖胖的笔记
 常瑞的部落落
常瑞的部落落
 Fortune博客
Fortune博客
 星空下的YZY
星空下的YZY
 BOBL技术博客
BOBL技术博客