

一、首先,我为什么聊机架感知
在了解hdfs负载均衡时,需要获取DataNode情况,包括每个DataNode磁盘使用情况,获取到数据不均衡,就要做负载均衡处理。做负载均衡就要考虑热点数据发送到哪里去,集群服务器配置是否相同,机架使用情况等。
机架感知在这里面有3个很重要的原因:
1、数据扩容,扩容的服务器在新机架上,导致数据不均衡
2、机架上的服务器磁盘配置不同(至于为什么,先不细聊)
通过感知机架,方便系统管理员手动操作,从而实现负载均衡
3、副本策略三副本,同节点、同机架、不同机架(同机房),可以实现保证有效存储时同时最大化安全策略
机架图
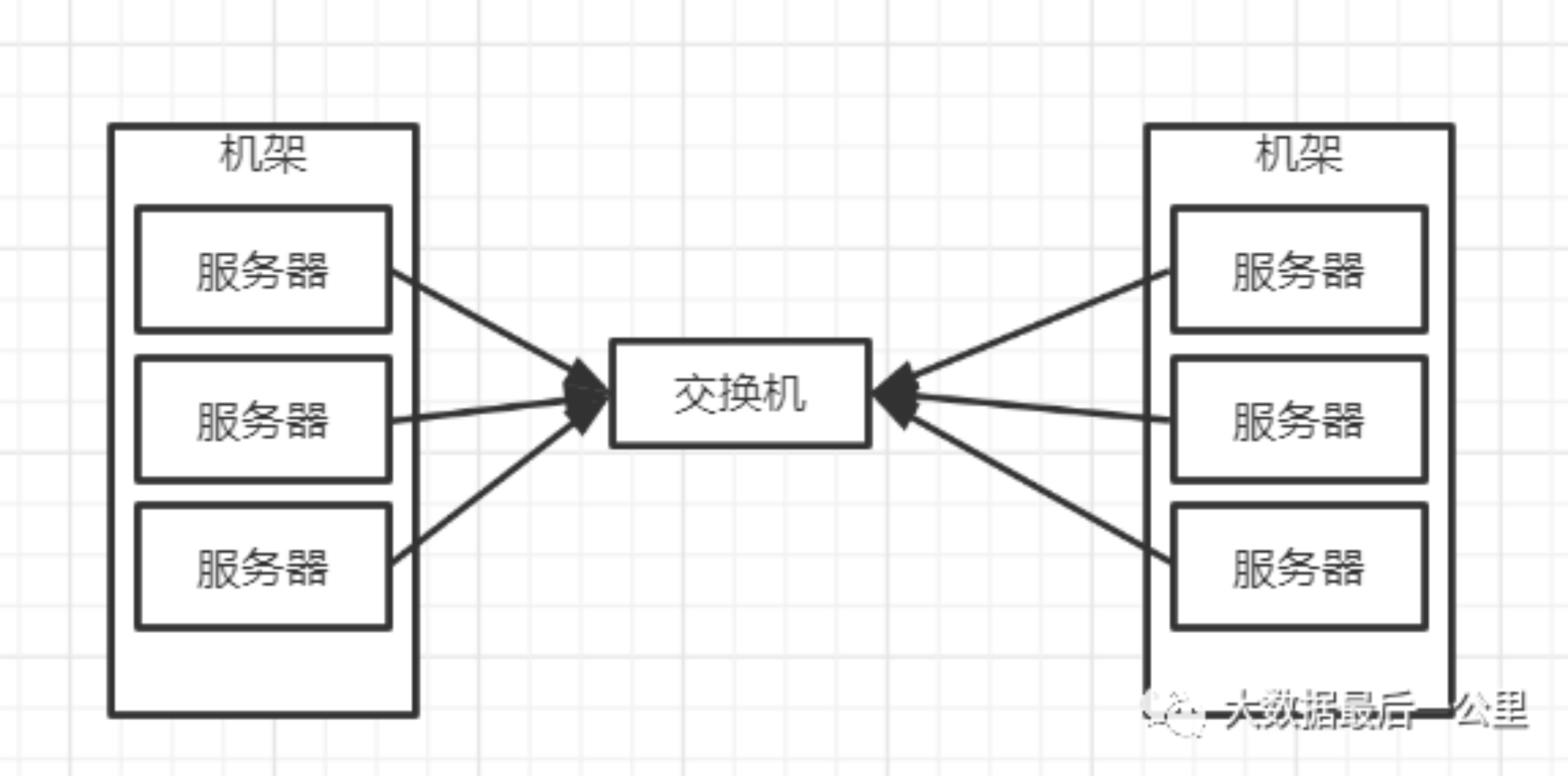
二、关于机架感知
- Hadoop不能自动获取节点是否分布在多机架上
- Hadoop大规模集群才会存在跨机架
- 不同节点之间通信尽量发生在同一个机架(可用性)
- 数据块副本策略会跨机架(容错性)
三、机架感知配置
1、自定义类实现 DNSToSwitchMapping,重写 resolve() 方法;打为 jar 包,并复制到 NameNode 节点的 /soft/hadoop/shared/hadoop/common/lib 目录下
1 | /** |
2、配置core-site.xml
1 | <property> |
3、重启集群
四、机架感知(来自官网)
Hadoop 组件是机架感知的。例如,HDFS 块放置将通过将一个块副本放置在不同的机架上来使用机架感知来实现容错。这在网络交换机故障或集群内分区的情况下提供数据可用性。
Hadoop 主守护进程通过调用配置文件指定的外部脚本或 java 类来获取集群工作线程的机架 ID。使用 java 类或外部脚本进行拓扑,输出必须遵循 java org.apache.hadoop.net.DNSToSwitchMapping接口。接口期望保持一一对应,拓扑信息格式为’/myrack/myhost’,其中’/‘为拓扑分隔符,’myrack’为机架标识,’myhost’为个人主机。假设每个机架有一个 /24 子网,可以使用“/192.168.100.0/192.168.100.5”格式作为唯一的机架-主机拓扑映射。
要使用java 类进行拓扑映射,类名由配置文件中的net.topology.node.switch.mapping.impl参数指定。一个示例 NetworkTopology.java 包含在 hadoop 发行版中,可由 Hadoop 管理员自定义。使用 Java 类而不是外部脚本具有性能优势,因为当新的工作节点注册自己时,Hadoop 不需要分叉外部进程。
如果实现外部脚本,它将在配置文件中使用net.topology.script.file.name参数指定。与 java 类不同,外部拓扑脚本不包含在 Hadoop 发行版中,而是由管理员提供。Hadoop 在 fork 拓扑脚本时会向 ARGV 发送多个 IP 地址。发送到拓扑脚本的 IP 地址数由net.topology.script.number.args控制,默认为 100。如果将net.topology.script.number.args更改为 1,则拓扑脚本将为每个由 DataNodes 和/或 NodeManagers 提交的 IP。
如果net.topology.script.file.name或net.topology.node.switch.mapping.impl未设置,则为任何传递的 IP 地址返回机架 ID ‘/default-rack’。虽然这种行为看起来很可取,但它可能会导致 HDFS 块复制问题,因为默认行为是将一个复制块写到机架外,并且无法这样做,因为只有一个名为“/default-rack”的机架。
python Example
1 | #!/usr/bin/python3 |
bash Example
1 | #!/usr/bin/env bash |
五、Hadoop集群网络拓扑描述
Hadoop集群架构通常包含两级网络拓扑,一般来说,各级机架装配30~40个服务器。
一个机架配置一个交换机,一个交换机实际的连接能力取决于交换机的端口数量,交换机的端口数量最多是48个
为了达到Hadoop的最佳性能,配置Hadoop系统以让其了解网络拓扑状况就极为关键。
如果集群只包含一个机架,无需做什么,就是默认配置。对于多机架的集群来说,描述清楚节点-机架的映射关系,使得Hadoop将MapReduce任务分配到各个节点时,会倾向于执行机架内的数据传输,而非跨机架数据传输。HDFS还能更加智能地防止副本,以uqde性能和弹性的平衡。
重点!!!
节点和机架等网络位置以树的形式来表示,从而能够体现出各个位置之间的网络距离。namenode使用网络位置来确定在哪里防止块的副本。MapReduce的调度器根据网络位置来查找最近的副本,将它作为map任务的输入。
比如spark中提到的移动数据不如移动计算也是同理。又比如yarn任务提交流程中,启动多个task,在哪启动的,现在是不是很清楚了。
综上,回头文章开头,为什么要做负载均衡,为什么要了解机架感知,数据和计算是互相影响的。
文章转载于”大数据最后一公里公众号”, 原址: https://cloud.tencent.com/developer/article/1856190
知识源于积累,登峰造极源于自律.


- 本文作者: xubatian
- 本文链接: http://xubatian.cn/为什么要知道Hadoop机架感知?/
- 版权声明: 本博客所有文章除特别声明外均为原创,采用 CC BY 4.0 CN协议 许可协议。转载请注明出处:https://www.xubatian.cn/
 故人的博客
故人的博客
 IT周的博客
IT周的博客
 大胖胖的笔记
大胖胖的笔记
 常瑞的部落落
常瑞的部落落
 Fortune博客
Fortune博客
 星空下的YZY
星空下的YZY
 BOBL技术博客
BOBL技术博客